Корпусы и корпусная лингвистика. Основные понятия
Корпусная лингвистика – раздел компьютерной лингвистики, занимающийся разработкой общих принципов построения и использования лингвистических корпусов (корпусов текстов) с использованием компьютерных технологий. Под названием лингвистический, или языковой, корпус текстов понимается большой, представленный в электронном виде, унифицированный, структурированный, размеченный, филологически компетентный массив языковых данных, предназначенный для решения конкретных лингвистических задач.
Введение: корпусы и корпусная лингвистика
Корпусная лингвистика – раздел компьютерной лингвистики, занимающийся разработкой общих принципов построения и использования лингвистических корпусов (корпусов текстов) с использованием компьютерных технологий. Под названием лингвистический, или языковой, корпус текстов понимается большой, представленный в электронном виде, унифицированный, структурированный, размеченный, филологически компетентный массив языковых данных, предназначенный для решения конкретных лингвистических задач. В понятие «корпус текстов» входит также система управления текстовыми и лингвистическими данными, которую в последнее время чаще всего называют корпусным менеджером (или корпус-менеджером) (англ. corpus manager). Это специализированная поисковая система, включающая программные средства для поиска данных в корпусе, получения статистической информации и предоставления результатов пользователю в удобной форме.
Целесообразность создания и смысл использования корпусов определяется следующими предпосылками:
Можно сказать, что все современные лингвистические исследования и работы по составлению словарей и грамматик так или иначе ориентированы на использование представительных корпусов текстов. Развитие современных интеллектуальных программных систем, предназначенных для обработки текстов на естественном языке, также требует большой экспериментальной лингвистической базы. Спрос на корпусные данные совпал с появлением соответствующих технических возможностей.
В первой половине 90-х гг. корпусная лингвистика окончательно сформировалась как отдельный раздел науки о языке. При этом она тесно взаимодействует с компьютерной лингвистикой, используя ее достижения и в свою очередь обогащая ее.
Поиск в корпусе данных позволяет по любому слову построить конкорданс – список всех употреблений данного слова в контексте со ссылками на источник. Корпусы могут использоваться для получения разнообразных справок и статистических данных о языковых и речевых единицах. В частности, на основе корпусов можно получить данные о частоте словоформ, лексем, грамматических категорий, проследить изменение частот и контекстов в различные периоды времени, получить данные о совместной встречаемости лексических единиц и т.д. Представительный массив языковых данных за определенный период позволяет изучать динамику процессов изменения лексического состава языка, проводить анализ лексико-грамматических характеристик в разных жанрах и у разных авторов, и т.д. Корпусы призваны служить также источником и инструментом многоаспектных лексикографических работ по подготовке разнообразных исторических и современных словарей. Данные корпусов могут быть использованы для построения и уточнения грамматик и в целях обучения языку.
Можно сказать, что корпусная лингвистика имеет своим предметом теоретические основы и практические механизмы создания и использования представительных массивов языковых данных, предназначенных для лингвистических исследований в интересах широкого круга пользователей.
Репрезентативность
Задача создателей корпуса – собрать как можно большее количество текстов, относящихся к тому подмножеству языка, для изучения которого корпус создается. Но главное не только и не столько в количестве языкового материала, сколько в его пропорциональности. Можно сказать, что корпус – это уменьшенная модель языка или подъязыка. Важнейшее понятие корпусной лингвистики – репрезентативность. Под репрезентативностью понимается необходимо-достаточное и пропорциональное представление в корпусе текстов различных периодов, жанров, стилей, авторов и т.п. Имеются разные подходы к определению репрезентативности, можно сказать, что применительно к общеязыковому (национальному) корпусу это понятие невозможно рассчитать и описать строго математически, однако к этому можно и нужно стремиться, как на этапе проектирования корпуса, так и на этапе его эксплуатации.
Размер корпуса
Термин «корпус» обычно обозначает собрание текстов конечного фиксированного размера. С течением времени объем и состав корпуса может меняться, однако эти изменения должны или не менять его репрезентативность, или менять обоснованно. Объем первых корпусов составлял 1 млн словоупотреблений (Брауновский корпус, Уппсальский корпус русского языка). В настоящее время считается, что объем общеязыкового корпуса должен быть не меньше 100 млн словоупотреблений.
Разметка
Для решения различных лингвистических задач мало лишь наличия массива текстов. Требуется также, чтобы тексты содержали в себе явным образом разного рода дополнительную лингвистическую и экстралингвистическую информацию. Так в корпусной лингвистике возникла идея размеченного корпуса. Разметка (tagging, annotation) заключается в приписывании текстам и их компонентам специальных меток (tag, tags): внешних, экстралингвистических (сведения об авторе и сведения о тексте: автор, название, год и место издания, жанр, тематика; сведения об авторе могут включать не только его имя, но также возраст, пол, годы жизни и многое другое. Это кодирование информации имеет название метаразметка), структурных (глава, абзац, предложение, словоформа) и собственно лингвистических, описывающих лексические, грамматические и прочие характеристики элементов текста. Набор этих метаданных во многом определяет возможности, предоставляемые корпусами исследователям. При выборе этих данных необходимо руководствоваться целями исследования и потребностями лингвистов, а также возможностями по внесению в текст тех или иных дополнительных признаков. Среди лингвистических типов разметки выделяются:
Существуют и другие типы разметки.
Технология создания корпусов
Технологический процесс создания корпуса можно представить в виде следующих шагов или этапов.
1. Определение перечня источников.
2. Оцифровка текстов (преобразование в компьютерную форму). Следует сказать, что насколько раньше задача ввода текстов в компьютер была тяжела и трудоемка, настолько сегодня эта проблема решается довольно легко, по крайней мере, что касается современных текстов и в современной орфографии. Эта легкость базируется на успехах в оптическом вводе (сканирование) и распознавании текстовой информации и на глобальной компьютеризации современной жизни, в том числе и в областях, связанных с обработкой текстовой информации. Тексты в электронном виде для создания корпусов могут быть получены самыми разными способами — ручной ввод, сканирование, авторские копии, дары и обмен, Интернет, оригинал-макеты, предоставляемые составителям корпусов издательствами и проч.
3. Предобработка текста. На этом этапе все тексты, полученные из разных источников, проходят филологическую выверку и корректировку. Также осуществляется подготовка библиографического и экстралингвистического описания текста.
4. Конвертирование и графематический анализ. Некоторые тексты проходят также через один или несколько этапов предварительной машинной обработки, в ходе которых осуществляются различного рода перекодировка (если требуется), удаление или преобразование нетекстовых элементов (рисунки, таблицы), удаление из текста переносов, «жёстких концов строк», обеспечение единообразного написания тире и проч. Как правило, эти операции выполняются в автоматическом режиме. Обычно на этом же этапе осуществляется сегментирование текста на его структурные составляющие.
5. Разметка текста. Разметка текста заключается в приписывании текстам и их компонентам дополнительной информации (метаданных). Метаописание текстов корпуса включает как содержательные элементы данных (библиографические данные, признаки, характеризующие жанровые и стилевые особенности текста, сведения об авторе), так и формальные (имя файла, параметры кодирования, версия языка разметки, исполнители этапов работ). Эти данные обычно вводятся вручную. Структурная разметка документа (выделение абзацев, предложений, слов) и собственно лингвистическая разметка обычно осуществляются автоматически.
6. На следующем этапе осуществляется корректировка результатов автоматической разметки: исправление ошибок и снятие неоднозначности (вручную или полуавтоматически).
7. Заключительный этап – конвертирование размеченных текстов в структуру специализированной лингвистической информационно-поисковой системы (corpus manager), обеспечивающей быстрый многоаспектный поиск и статистическую обработку.
8. И, наконец, обеспечение доступа к корпусу. Корпус может быть доступен в пределах дисплейного класса, может распространяться на CD-ROM и может быть доступен в режиме глобальной сети. Различным категориям пользователей могут предоставляться разные права и разные возможности.
Конечно, в каждом конкретном случае состав и количество процедур могут отличаться от выше перечисленных, и реальная технология может оказаться гораздо сложнее.
Автоматическая разметка
Фактически, корпус в его современном понимании – это всегда компьютерная база данных, и в процессе его создания естественно использование специальных программ. Среди этих программ особое место занимают программы автоматической разметки. Разметка корпусов представляет собой трудоемкую операцию, особенно учитывая размеры современных корпусов. Если для некоторых видов разметки, в частности анафорической, просодической, создание автоматических систем пока представляется довольно сложным и основная часть работы проводится вручную, то для морфологического и синтаксического анализа существуют различные программные средства, которые принято называть соответственно тэггеры (taggers) и парсеры (parsers). В результате работы программ автоматического морфологического анализа каждой лексической единице приписываются грамматические характеристики, включая часть речи, лемму (нормальную форму) и набор граммем (например, род, число, падеж, одушевленность/неодушевленность, переходность и т.п.). В результате работы программ автоматического синтаксического анализа фиксируются синтаксические связи между словами и словосочетаниями, а синтаксическим единицам приписываются соответствующие характеристики (тип предложения, синтаксическая функция словосочетания и т.п.).
Исправление ошибок и снятие неоднозначности
Однако автоматический анализ естественного языка небезошибочен и многозначен – он, как правило, дает несколько вариантов анализа для одной лексической единицы (слова, словосочетания, предложения). В этом случае говорят о грамматической омонимии. Снятие неоднозначности (морфологической, синтаксической) в целом является одной из важнейших и сложнейших задач компьютерной лингвистики. При создании корпусов для снятия неоднозначности используются автоматические и ручные способы. Корпусы нового поколения включают сотни миллионов слов, поэтому выдвигаются принципы разработки систем, которые бы минимизировали вмешательство человека. Автоматическое разрешение морфологической или синтаксической омонимии, как правило, основывается на использовании информации более высокого уровня (синтаксического, семантического) с применением статистических методов.
Форматы данных и стандартизация
Корпусы, как правило, предназначены для многократного использования многими пользователями, соответственно, и их разметка, и их программное обеспечение должны быть определенным образом унифицированы. Что касается разметки, то как лингвистическая, так и экстралингвистическая разметка должны базироваться на некоторых достаточно широко распространенных и принятых принципах описания текстов и языковых единиц. Параметры разметки и их значения должны быть достаточно «естественными», т.е. должны соответствовать общепринятым научным классификациям. Что касается программного обеспечения, то оно должно поддерживать обработку типовых запросов и решение типовых задач. Большое значение имеет унификация форматов, как их наполнения, так и структуры. Единые форматы представления данных позволяют во многих случаях использовать единое программное обеспечение и обмениваться корпусными данными. Стандартизация в отношении корпусов, совместимость типов данных важны и с точки зрения сравнимости разных корпусов. Вопросы оценки корпусов, их пригодности к различным заданиям также требуют своих «стандартов оценки».
В настоящее время на основе международного опыта выработались де-факто стандарты представления метаданных, базирующиеся на описаниях текстов в рамках проекта Text Encoding Initiative (TEI) и на рекомендациях EAGLES (Expert Advisory Group on Language Engineering Standards). В качестве формального языка разметки широко применяются языки SGML и XML. В настоящее время стандарты EAGLES непосредственно включаются в технологическую среду языка XML, см., в частности, разработку стандарта Corpus Encoding Standard for XML (XCES).
Корпусные менеджеры
Работа пользователей с корпусом осуществляется с помощью специализированных программных средств – корпусных менеджеров, предоставляющих разнообразные возможности по получению из корпуса необходимой информации:
Результаты поиска обычно выдаются в виде конкорданса (поэтому корпусные менеджеры еще называют конкордансерами), где искомая единица представлена в ее контекстном окружении и в виде статистических данных. Последние могут фиксировать частотные характеристики отдельных языковых единиц, или граммем, или могут характеризовать совместную встречаемость нескольких лексических единиц. Многие системы позволяют настраивать формат выдачи (менять длину левого и правого контекста, задавать объем выдачи и порядок сортировки данных, отображать или не отображать лингвистические и экстралингвистические характеристики, и т.д.).
Пользователи и способы использования корпусов
Пользователей корпусов, как правило, интересует не содержание конкретных текстов, а их метатекстовая информация и примеры употребления тех или иных языковых элементов и конструкций. Это, в первую очередь, лингвисты. Первоначальные лингвистические исследования, проводившиеся с помощью корпусов, сводились к подсчету частот встречаемости различных языковых элементов. Статистические методики используются в решении сложных лингвистических задач, таких как машинный перевод, распознавание и синтез речи, средства проверки орфографии и грамматики и т.д. Так, устойчивые словосочетания представляют собой с семантической точки зрения неделимую смысловую единицу, что очень важно учитывать в лексикографии, системах автоматической обработки текста. На материале корпуса статистическими методами можно определить, какие слова встречаются вместе регулярно и, таким образом, могут быть отнесены к устойчивым словосочетаниям. Корпусы являются богатым источником данных для исследований по лексикографии и грамматике. С исследованиями по лексикографии тесно связаны исследования в области семантики. Наблюдая окружения той или иной лингвистической единицы в корпусе, можно установить определенные семантические признаки, характеризующие данную единицу.
Лингвисты-теоретики используют корпусы в качестве экспериментальной базы для проверки гипотез и доказательства своих теорий. Прикладные лингвисты (преподаватели, переводчики и т.п.) используют компьютерные корпусы при обучении языкам и для решения своих профессиональных задач. Особый класс пользователей представляют компьютерные лингвисты: они пытаются выявить и использовать статистические и лингвистические закономерности, присутствующие в текстах, для создания компьютерных моделей языка. Другие специалисты по языку (литературоведы, редакторы) также в ряде случаев могут получить ответы на интересующие их вопросы, обратившись к корпусу. Специалисты по общественным наукам (историки, социологи) также могут изучать свои объекты через язык, используя такие параметры текстов, как период, автор или жанр. Литературоведы используют корпусы для стилеметрических исследований. Наконец, корпусы используются для разработки и настройки различных автоматизированных систем (машинный перевод, распознавание речи, информационный поиск).
Типы корпусов
Несмотря на разнообразие корпусов, можно выделить два основных способа деления корпусов на классы: 1) это противопоставление корпусов, относящихся ко всему языку (часто к языку определенного периода), корпусам, относящимся к какому-либо подъязыку (жанр, стиль, язык определенной возрастной или социальной группы, язык писателя или ученого и т.п.); 2) разделение корпусов по типу лингвистической разметки. Несмотря на наличие множества типов разметки, большинство реально существующих корпусов относится к корпусам морфологического либо синтаксического типа (последние в англоязычной литературе называют treebanks, что можно перевести как «банки синтаксических структур»). При этом следует подчеркнуть, что корпус с синтаксической разметкой явно или неявно включает в себя и морфологические характеристики лексических единиц.
Вообще же существует большое число разных типов корпусов. Их разнообразие определяется многообразием исследовательских и прикладных задач, для решения которых они создаются, и различными основаниями для классификации. В зависимости от поставленных целей и классифицирующих признаков, можно выделить различные типы корпусов (см. таблицу).
Основные задачи и направления корпусной лингвистики. Взаимодействие корпусной лингвистики и компьютерной (computational) лингвистики
В качестве своей главной цели изучаемая нами наука видит объективное лингвистическое описание языковой системы, причём к этому описанию корпусная лингвистика подходит от изучения конкретной человеческой коммуникации, от реальных текстов, которые ранее рассматривались лишь как досадная помеха.
Основные задачи
Как уже говорилось в предыдущей лекции, деятельность в рамках корпусной лингвистики может быть сведена к созданию корпусов и к лингвистическим исследованиям на их базе (все задачи по изучению больших массивов текстов). В каком- то смысле, корпусная лингвистика сама создаёт свой материал, точнее, самостоятельно структурирует его. Именно это делает её самостоятельной лингвистической дисциплиной – у неё специфический характер используемого словесного материала (корпусы) и свой собственный инструментарий (программы анализа корпусов). А самостоятельность науки как раз и определяется наличием у неё собственного материала, либо собственных методов его исследования. Корпусная лингвистика обладает как тем, так и другим.
В качестве своей главной цели изучаемая нами наука видит объективное лингвистическое описание языковой системы, причём к этому описанию корпусная лингвистика подходит от изучения конкретной человеческой коммуникации, от реальных текстов, которые ранее рассматривались лишь как досадная помеха. В качестве вторичной задачи рассматривается выработка особого способа отражения речевого материала в корпусе текстов. Этот способ, в свою очередь, может использоваться другими лингвистическими дисциплинами.
Ещё одно отличие в подходах между традиционной лингвистикой и корпусной заключается в том, что традиционно языкознание изучало возможность (possibility) или невозможность какого-либо лингвистического явления. Например, традиционный учебник английского языка скажет вам, что конструкция I’m not в литературном английском возможна, а конструкция I ain’t – нет. Корпусная лингвистика дополнительно изучает и вероятность (probability) лингвистических явлений. То есть, с точки зрения корпусной лингвистики, мы не можем сказать, что употребление I ain’t в литературном языке совершенно невозможно. Оно всего лишь маловероятно.
Основные направления
Кратко и неполно расскажем об основных направлениях современной корпусной лингвистики.
Во-первых, это лексикографические исследования, создание словарей. Практически все современные словари английского языка (Collins, Webster, MacMillan и т.д.) издаются на основе огромных корпусов, которые позволяют сделать словарь репрезентативным. То есть, словарь может быть верным или не верным относительно данного корпуса.
Во-вторых, изучение корпусов позволяет получать точные данные о лексическом составе языков, об относительных частотах употребления тех или иных слов. В частности, при помощи корпусной лингвистики был окончательно доказан так называемый закон Ципфа, утверждающий, что если в любом естественном языке все слова упорядочить по убыванию частоты их использования, то частота любого слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру (так называемому рангу этого слова). Например второе по частоте слово встречается примерно в два раза реже, чем первое, третье — в три раза реже, чем первое, и так далее.
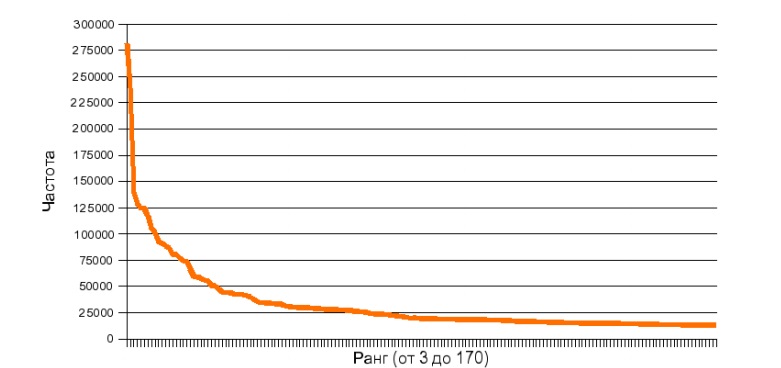
Рисунок 1: Закон Ципфа
Выводом из закона Ципфа является утверждение о том, что язык – это большой набор редких событий. То есть, редких слов в языке значительно больше, чем частых.
В-третьих, корпусная лингвистика изучает и изменения в лексическом составе языков, различные его вариации (например, появление и исчезновение неологизмов).
Четвёртое направление корпусной лингвистики – изучение грамматики естественных языков, в частности – сочетаемости тех или иных грамматических явлений друг с другом. Естественно, что данные, полученные из живой речи, гораздо более актуальны, чем умозрительные грамматики традиционной лингвистики. Кроме того, получается более объективное исследование: грамматика верна лишь относительно того или иного корпуса текстов.
В-пятых, не оставлено без внимания и изучение текстов. Например, используя корпусы, мы можем научиться определять функциональный стиль через статистические характеристики текста – среднюю длину слова и предложения, характерные сочетания слов и т.д. Такие методы уже существуют и используются в автоматическом реферировании и тематическом поиске. Причём, изучать таким образом можно не только письменный, но и устный дискурс.
В-шестых, корпусная лингвистика активно используется в лингводидактике, то есть, в обучении иностранным языкам. Чтобы знать, чему, собственно, учить, необходимы точные количественные данные о преподаваемом языке — состав наиболее частотной лексики, вероятности употребления тех или иных грамматических конструкций и т. д. Что немаловажно, корпусная лингвистика даёт возможность обновить набор примеров, которые используются в преподавании языка.
И наконец, особый интерес для нас, как переводоведов, представляют, конечно, многоязычные корпусы, особенно «выровненные» или «сопоставленные» (aligned). В «выровненном корпусе» каждой фразе на одном языке соответствует её эквивалент на другом языке или языках. Такие корпусы используются при подготовке переводчиков или при создании двуязычных словарей. Очень важны они для создания систем автоматического машинного перевода (если такая система опирается на корпус переводов, сделанных переводчиками-людьми, её качество будет гораздо выше). Кроме того, такой корпус можно использовать для исследований, связанных со сравнением оригинальных и переводных текстов.
Корпусная лингвистика и компьютерная лингвистика
Довольно часто звучит вопрос о соотношении корпусной и так называемой «компьютерной лингвистики». Эти ветви науки о языке, действительно, близки друг другу, но всё же не совпадают.
Что такое «компьютерная лингвистика»? Вообще, термин довольно расплывчат, тем более, что существует ещё некая «математическая лингвистика». В англоязычном языкознании проще — там есть один общий термин computational linguistics, то есть, «вычислительная лингвистика». Мы для простоты будем говорить «компьютерная лингвистика», поскольку сейчас без компьютеров всё равно никто уже ничего не вычисляет. Так вот, обычно говорят, что компьютерная лингвистика — это такая междисциплинарная ветвь лингвистики, занимающаяся либо статистическим либо rule-based (1) моделированием языка с использованием компьютеров. Моделирование – это приблизительный эквивалент английского термина sampling. То есть, компьютерная лингвистика строит модели языка. Кстати, корпусная занимается примерно тем же, поэтому они друг другу помогают.
Вот некоторые точки приложения компьютерной лингвистики:
• автоматизированное извлечение информации из естественных текстов;
• конструирование удобных интерфейсов между человеком и машиной;
• количественное описание общения на естественных языках;
Немаловажно, что компьютерная лингвистика создаёт инструменты (то есть, программы) для корпусной лингвистики. В этом смысле они тоже дополняют друг друга. Например, корпусным лингвистам необходимы средства для автоматической разметки классов слов в корпусах. Если у вас есть корпус на 100 миллионов словоупотреблений и вам нужно отметить часть речи у каждого слова, то вручную это сделать совершенно нереально. Тут и понадобится специализированное программное обеспечение. Обычно сначала его нужно «обучить», то есть разметить вручную какое-то небольшое количество слов, чтобы система «натренировалась». После этого разметка по классам слов (2) будет происходить в автоматическом режиме.
Для исследования корпуса бывает важно сначала снять лексическую неоднозначность, то есть, выделить слова-омонимы. Например, в корпусе русских текстов нужно отделить слово «лук» в значении «овощ» от слова «лук» в значении «оружие». В большом корпусе сделать это вручную затруднительно. Поэтому компьютерная лингвистика создаёт программы семантического анализа текстов, которые могут в более или менее автоматическом режиме определять, в каком значении употреблено то или иное слово.
И, наконец, компьютерная лингвистика активно занимается вопросами создания параллельных корпусов, о которых говорилось выше. Ведь это очень интересная лингвистическая задача – как в автоматическом режиме «сопоставить» (Англ. Text alignment) два текста, один из которых является переводом другого? Как «соотнести» друг с другом отдельные предложения на языке оригинала и на языке перевода? Здесь достаточно проблем и трудностей, но решения уже есть и уже существуют автоматические системы сопоставления текстов. Некоторые из таких программ мы будем изучать в рамках курса «компьютерные технологии в переводе».
Итак, как можно видеть, компьютерная лингвистика выступает для корпусной в качестве «поставщика» инструментов анализа и обработки корпусов. Поскольку большой корпус можно обрабатывать только при помощи компьютера, необходимы программы. А написанием лингвистически ориентированных программ как раз и занимается компьютерная лингвистика. С другой стороны, в современной науке порой сложно отделить корпусного лингвистика от компьютерного, поскольку чаще всего учёные занимаются и тем и другим.
1 На основе правил.
2 Англ. POS (part-of-speech) tagging.
3 По английски синтаксический анализ – parsing.
Курс «Корпусная лингвистика» (А.Б. Кутузов), ТюмГУ
Лицензия Creative commons Attribution Share-Alike 3.0 Unported
 06.06.2016, 6097 просмотров.
06.06.2016, 6097 просмотров.



