Трансферное обучение: почему deep learning стал доступнее
Что помогает стартапам использовать методы глубинного обучения в своих проектах?
Раньше глубинное обучение требовало огромных мощностей, денежных инвестиций и времени, поэтому было недоступно небольшим компаниям. В последние годы ситуация меняется: стартапы и даже энтузиасты-одиночки могут использовать методы глубинного обучения в своих проектах. Разработчик Калеб Кайзер делится своими наблюдениями о том, почему deep learning становится все доступнее.
Раньше для того, чтобы заняться глубинным обучением, вы должны были иметь доступ к большому очищенному набору данных и самостоятельно разработать и обучить эффективную модель. Значит, проекты без существенной поддержки извне были невозможны по умолчанию. Однако за последние пару лет всё изменилось. Движущая сила такого роста — трансферное обучение.
Что такое трансферное обучение?
Идея трансферного обучения строится на том, что знания, накопленные в модели, подготовленной для выполнения одной задачи — скажем, распознавания цветов на фотографии — могут быть перенесены на другую модель, чтобы помочь в построении прогнозов для другой, родственной задачи, например, для задачи выявления меланомы.
Существуют различные подходы к трансферному обучению, но один из них — тонкая настройка (finetuning) — находит особенно широкое применение.
При таком подходе команда берет предварительно обученную модель и удаляет или переучивает последние слои этой модели, чтобы сфокусироваться на новой, схожей задаче. Например, AI Dungeon — это текстовая приключенческая игра с открытым миром, которая стала очень популярной из-за того, насколько убедительны сюжеты, написанные с помощью искусственного интеллекта:
Примечательно, что AI Dungeon не была разработана исследовательской лабораторий Google, это проект одного человека, сделанный во время хакатона.
Ник Уолтон, создатель AI Dungeon, не построил ее с нуля, а с помощью новейшей NLP-модели — GPT-2 компании OpenAI — доработал ее тонкой настройкой и дал возможность писать свои тексты для приключений.
Причина, по которой это вообще работает, в том, что в нейросетях базовые слои фокусируются на простых, общих паттернах, тогда как последние слои фокусируются на более специфичных паттернах для задач классификации или регрессии. Профессор Стенфордского университета Эндрю Ын визуализирует слои и их относительные уровни специфичности, представляя модель распознавания образов:
Общее содержание базовых слоев, оказывается, часто хорошо перекладывается на другие задачи. Например, в случае AI Dungeon GPT-2 обладала современным пониманием разговорного английского языка, ей просто потребовалась небольшая перетренировка в заключительных слоях для хороших результатов в создании собственных приключенческих сюжетов.
С помощью этого процесса один разработчик может развернуть модель, которая за несколько дней достигнет современных уровней развития в новой области.
Небольшие наборы данных больше не помеха
Глубинное обучение, как правило, требует больших объемов размеченных данных, а во многих областях таких данных просто не существует. Трансферное обучение может решить эту проблему. Например, команда, связанная с Гарвардской медицинской школой, недавно развернула модель, которая может на основе рентгенограмм грудной клетки прогнозировать смертность в долгосрочной перспективе, в том числе не связанную с раком.
Несмотря на то, что у исследователей был набор данных, состоявший примерно из 50 000 размеченных изображений, они не могли тренировать собственную свёрточную нейросеть с нуля. Вместо этого они взяли подготовленную модель Inception-v4 (которая обучается на наборе данных, состоящем более чем из 14 миллионов изображений ImageNet) и использовали трансферное обучение и небольшие архитектурные модификации для адаптации модели к своему набору данных.
В результате их нейросеть научилась рассчитывать уровень риска по одному изображению грудной клетки пациента.
На обучение моделей теперь требуются минуты, а не дни
Обучение модели на огромном объеме данных требует не только приобретения этих данных, нужны также ресурсы и время.
Например, когда в Google разрабатывали свою state of the art модель классификации изображений Xception, были подготовлены две версии: одна на датасете ImageNet (14 миллионов изображений), а другая на наборе данных JFT (350 миллионов изображений).
Обучение на 60 графических процессорах NVIDIA K80 с различными оптимизациями заняло три дня для проведения одного эксперимента с ImageNet. Эксперимент с JFT занял больше месяца. Однако теперь, когда предварительно обученная модель Xception выпущена, команды могут провести тонкую настройку своих версий намного быстрее.
Например, команда из Университета штата Иллинойс и Аргоннской национальной лаборатории недавно подготовила модель для классификации изображений галактик.
Несмотря на то, что их набор данных составляет всего 35 000 размеченных изображений, они смогли настроить Xception всего за восемь минут с помощью графических процессоров NVIDIA.
Полученная модель способна классифицировать галактики с точностью 99,8% при сверхчеловеческой скорости.
Машинное обучение становится экосистемой
В программировании мы видим, как экосистемы «взрослеют» по довольно стандартным шаблонам. Появляется новый язык программирования с интересными возможностями, и его используют для определенных сценариев, исследовательских проектов и игр. Сегодня каждый, кто будет им пользоваться, должен собирать вспомогательные программы с нуля.
В итоге сообщество разрабатывает библиотеки и проекты, которые абстрагируются от общих утилит до тех пор, пока инструментарий не будет достаточно устойчив и работоспособен для использования. На этом этапе разработчики не думают об отправке HTTP-запросов или о подключении к базам данных, а сосредоточены исключительно на создании своего продукта.
Другими словами, большие компании создают свои модели, а разработчики используют их для создания продуктов. По мере того, как компании вроде OpenAI, Google, Facebook и других технологических гигантов выпускают мощные модели с открытым исходным кодом, инструменты в распоряжении разработчиков машинного обучения становятся все более мощными и стабильными.
Вместо того чтобы тратить время на построение модели с нуля при помощи PyTorch или TensorFlow, датасаентисты используют модели с открытым исходным кодом и трансферное обучение для создания продуктов, а значит, придет новое поколение программного обеспечения на основе программного обучения.
Теперь разработчикам машинного обучения остается думать только о том, как бы запустить эти модели в производство.
Трансферное обучение искусственный интеллект
Transfer Learning (трансферное обучение) — это подраздел машинного обучения, целью которого является применение знаний, полученные из одной задачи, к другой целевой задаче. Существует множество решений, который могут помочь Data Scientist’у применить его к своей проблеме, поэтому нет необходимости изобретать велосипед.
Например, знания, полученные при обучении классификации статей Википедии, можно использовать для решения задачи классификации медицинских текстов. Можно пойти дальше, и использовать модель, обученную для решения классификации автомобилей, чтобы распознавать птиц в небе, как одну из задач компьютерного зрения (Computer Vision).
История Transfer Learning
История трансферного обучения восходит к 1993 году. В своей статье «Передача между нейронными сетями на основе различимости (англ. Discriminability-Based Transfer between Neural Networks)» Lorien Pratt открыла ящик Пандоры и представила миру потенциал трансферного обучения [1]. В июле 1997 года журнал Machine Learning опубликовал серию статей о трансферном обучении [2]. По мере развития смежные области, например многозадачное обучение (multi-task learning), также были включены в трансферное обучение. Сегодня Transfer Learning является мощным инструментом искусственного интеллекта. Andrew Ng предсказывает подъём трансферного обучения с точки зрения коммерческого успеха [3].
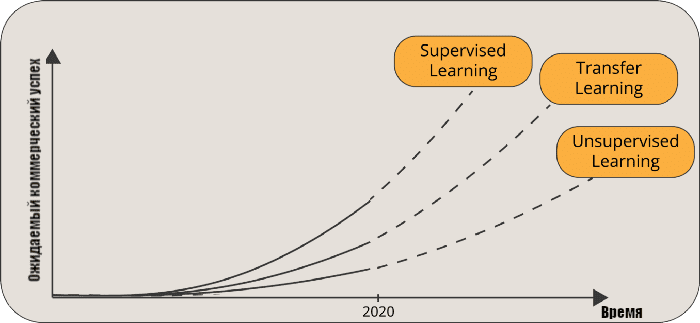 Ожидание Andrew Ng коммерческого успеха подразделов машинного обучения
Ожидание Andrew Ng коммерческого успеха подразделов машинного обучения
Как работает Transfer Learning
Прежде всего стоит обратить внимание на 2 аспекта при использовании Transfer Learning:
Предварительно обученная модель — это модель, созданная и обученная кем-то другим для решения проблемы, аналогичной нашей. На практике кто-то, имея большие вычислительные ресурсы, они конструируют большую нейронную сеть для решения конкретной проблемы, тренируют её на большом наборе данных (Big Data), например ImageNet или Wikipedia Corpus. Так, например, VGG19 имеет 143.667.240 параметров и используется для классификации изображений. Под «открытой» моделью мы подразумеваем, что она обнародована, и её можно свободно использовать.
Ресурсы с предварительно обученными моделями:
В редких случаях предварительно обученные модели хорошо работают для целевой задачи. Как правило, их необходимо поднастроить по следующим причинам:
Предварительно обученные сети используются для дообучения (fine-tuning) или выделения признаков (feature extraction).
Дообучение
В архитектурах Deep Learning начальные слои изучают общую информацию, а слои на последнем уровне более специфичные признаки. Например, первые слои запониманют текстуру, цвет, общую картину, а последние слои глаза, рот, родинки и т.д. Многие модели обучены на всевозможных ситуациях, например, ImageNet содержит 1 миллион изображений с 1000 классами, поэтому нет необходимости изменять общую картину, которую видит текущая модель. Вместо этого полезнее дополнить новыми конкретными признаками, дообучив только последние слои, чтобы перепрофилировать её для собственных нужд.
Затрагивая больше слоев для дообучения, повышается риск переобучения (overfitting). Например, модель VGG19 может после полного переобучения показать непредсказуемые результаты в рамках Transfer Learning, причем не в пользу Data Scientist’а. Поэтому часто обходятся двумя-тремя последними слоями.
Выделение признаков
Для выделения признаков используются представления, полученные предыдущей моделью, для извлечения признаков из новых образцов, которые затем пропускаются через новый классификатор. В этом методе просто добавляется классификатор, который будет обучаться с нуля, поверх предварительно обученной модели для решения целевой функции.
В сверточные архитектуры нейронных сетей (CNN) обычно состоят из двух частей: сверточной и полносвязной. Для выделения признаков (feature extraction) сверточная часть остаётся неизменной. В то время как Fine Tuning захватывает несколько последних сверточных слоев.
Сверточная основа не используется по причине их универсальности. Так, например, они имеют представления о присутствии объектов и их местоположении. С другой стороны, полносвязные слои не имеют знаний о местоположении объектов, т.е. не обладают свойством инвариантности, поэтому их безбоязненно можно поменять на собственные.
Выделение признаков в Transfer Learning реализуется двумя способами:
Что выбрать дообучение или выделение признаков
Оба метода могут повысить точность модели, но при условии наличия достаточного объёма данных, в противном случае сеть не «почувствует» изменений от нового набора данных и не сможет перепрофилироваться.
Выделение признаков применяется в том случае, когда решаемая задача прошлой сети схожа с целевой. А вот если есть существенные отличия, то используется дообучение, которое является более затратной с вычислительной точки зрения.
Transfer Learning: как быстро обучить нейросеть на своих данных
Машинное обучение становится доступнее, появляется больше возможностей применять эту технологию, используя «готовые компоненты». Например, Transfer Learning позволяет использовать накопленный при решении одной задачи опыт для решения другой, аналогичной проблемы. Нейросеть сначала обучается на большом объеме данных, затем — на целевом наборе.
В этой статье я расскажу, как использовать метод Transfer Learning на примере распознавания изображений с едой. Про другие инструменты машинного обучения я расскажу на воркшопе «Machine Learning и нейросети для разработчиков».
Если перед нами встает задача распознавания изображений, можно воспользоваться готовым сервисом. Однако, если нужно обучить модель на собственном наборе данных, то придется делать это самостоятельно.
Для таких типовых задач, как классификация изображений, можно воспользоваться готовой архитектурой (AlexNet, VGG, Inception, ResNet и т.д.) и обучить нейросеть на своих данных. Реализации таких сетей с помощью различных фреймворков уже существуют, так что на данном этапе можно использовать одну из них как черный ящик, не вникая глубоко в принцип её работы.
Однако, глубокие нейронные сети требовательны к большим объемам данных для сходимости обучения. И зачастую в нашей частной задаче недостаточно данных для того, чтобы хорошо натренировать все слои нейросети. Transfer Learning решает эту проблему.
Transfer Learning для классификации изображений
Нейронные сети, которые используются для классификации, как правило, содержат N выходных нейронов в последнем слое, где N — это количество классов. Такой выходной вектор трактуется как набор вероятностей принадлежности к классу. В нашей задаче распознавания изображений еды количество классов может отличаться от того, которое было в исходном датасете. В таком случае нам придётся полностью выкинуть этот последний слой и поставить новый, с нужным количеством выходных нейронов
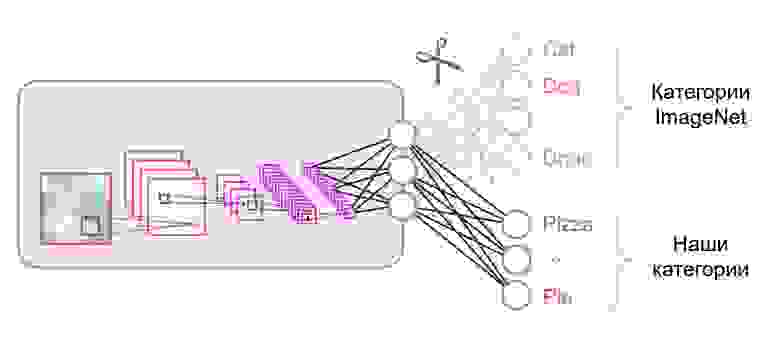
Зачастую в конце классификационных сетей используется полносвязный слой. Так как мы заменили этот слой, использовать предобученные веса для него уже не получится. Придется тренировать его с нуля, инициализировав его веса случайными значениями. Веса для всех остальных слоев мы загружаем из предобученного снэпшота.
Существуют различные стратегии дообучения модели. Мы воспользуемся следующей: будем тренировать всю сеть из конца в конец (end-to-end), а предобученные веса не будем фиксировать, чтобы дать им немного скорректироваться и подстроиться под наши данные. Такой процесс называется тонкой настройкой (fine-tuning).
Структурные компоненты
Для решения задачи нам понадобятся следующие компоненты:
В нашем примере компоненты (1), (2) и (3) я буду брать из собственного репозитория, который содержит максимально легковесный код — при желании с ним можно легко разобраться. Наш пример будет реализован на популярном фреймворке TensorFlow. Предобученные веса (4), подходящие под выбранный фреймворк, можно найти, если они соответствуют одной из классических архитектур. В качестве датасета (5) для демонстрации я возьму Food-101.
Модель
В качестве модели воспользуемся классической нейросетью VGG (точнее, VGG19). Несмотря на некоторые недостатки, эта модель демонстрирует довольно высокое качество. Кроме того, она легко поддается анализу. На TensorFlow Slim описание модели выглядит достаточно компактно:
Веса для VGG19, обученные на ImageNet и совместимые с TensorFlow, скачаем с репозитория на GitHub из раздела Pre-trained Models.
Датасет
В качестве обучающей и валидационной выборки будем использовать публичный датасет Food-101, где собрано более 100 тысяч изображений еды, разбитых на 101 категорию.

Скачиваем и распаковываем датасет:
Пайплайн данных в нашем обучении устроен так, что из датасета нам понадобится распарсить следующее:
Все вспомогательные функции, ответственные за обработку данных, вынесены в отдельный файл data.py :
Обучение модели
Код обучения модели состоит из следующих шагов:
После запуска обучения можно посмотреть на его ход с помощью утилиты TensorBoard, которая поставляется в комплекте с TensorFlow и служит для визуализации различных метрик и других параметров.
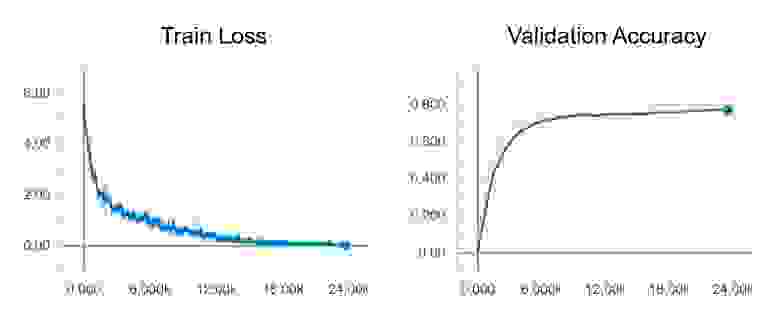
В конце обучения в TensorBoard мы наблюдаем практически идеальную картину: снижение Train loss и рост Validation Accuracy
Тестирование модели
Теперь протестируем нашу модель. Для этого:

Весь код, включая ресурсы для построения и запуска Docker контейнера со всеми нужными версиями библиотек, находятся в этом репозитории — на момент прочтения статьи код в репозитории может иметь обновления.
На воркшопе «Machine Learning и нейросети для разработчиков» я разберу и другие задачи машинного обучения, а студенты к концу интенсива сами представят свои проекты.
Как скопировать стиль Уорхола с помощью нейросети VGG-19, трансферного обучения и TensorFlow

То что мы сделаем ещё называется Нейронный перенос стиля – это метод смешивания двух изображений и создания нового изображения из изображения-контента путём копирования стиля другого изображения, которое называется изображением стиля. Созданное изображение часто называют стилизованным изображением.
В этой статье мы скопируем стиль Энди Уорхола с «Мэрилин Диптих» на наши фотографии. Уорхол создал диптих Монро в 1962 году, сначала раскрасив холст разными цветами, а затем разместив теперь знаменитое изображение Мэрилин поверх холста. Хотя Уорхол не является основателем поп-арта, он – одна из самых влиятельных фигур в этом жанре.

Рис. 1. «Мэрилин Диптих» Уорхола, а на кдпв показан наш результат нейронного переноса стиля в поп-арт, которого мы добились с помощью сети VGG-19
Что касается технического аспекта туториала, вместо использования готовой сети Magenta мы используем предварительно обученную модель компьютерного зрения VGG-19 и настроим её. Таким образом, эта статья представляет собой руководство по переносному обучению, а также по компьютерному зрению. Применяя возможности трансферного обучения, мы можем достичь лучших результатов, если сможем правильно настроить модель и иметь широкий спектр дополнительных возможностей настройки.
переносное обучение – это подраздел машинного обучения и искусственного интеллекта, цель которого – применить знания, полученные в результате выполнения одной задачи (исходной задачи), к другой, но похожей задаче (целевой задаче).
Кратко расскажу о модели, которую мы будем настраивать: VGG-19.
VGG-19
VGG – это свёрточная нейронная сеть с глубиной 19 слоев. Она была построена и обучена К. Симоняном и А. Зиссерманом в Оксфордском университете в 2014 году. Вся информация об этом есть в статье Very Deep Convolutional Networks for Large-Scale Image Recognition, опубликованной в 2015 году. Сеть VGG-19 обучена с использованием более одного миллиона изображений из базы данных ImageNet. Она обучалась на цветных изображениях размером 224×224 пикселей. Естественно, вы можете импортировать модель ImageNet с уже обученными весами. Эта предварительно обученная сеть может классифицировать до тысячи объектов. В этом туториале мы избавимся от верхней части, используемой для классификации, и добавим наши собственные дополнительные слои, чтобы её можно было использовать для нейронного переноса стиля. Вот официальная визуализация сети из научной работы:

Рис. 3. Иллюстрация сети VGG-19
Как я уже упоминал, чей стиль мог бы быть более культовым и более подходящим, чем стиль Энди Уорхолла для переноса в поп-арт. Мы будем использовать его культовую работу Мэрилин Диптих в качестве основы стиля и портретное фото из Unsplash в качестве основного контента:

Рис. 4. Мэрилин Диптих и выбранное для эксперимента фото
Уакзываем пути к изображениям
Используя TensorFlow, я могу написать get_files [получить файлы] с внешних URL-адресов. С помощью приведённого ниже кода я загружу изображения в свой блокнот Colab, одно для стиля, а другое для контента:
Масштабирование изображений
Поскольку наши изображения имеют высокое разрешение, нам необходимо масштабировать их, чтобы обучение не занимало слишком много времени. Приведённый ниже код преобразует данные изображения в подходящий формат, масштабирует изображение (не стесняйтесь изменять параметр max_dim ) и создаёт новый объект, который можно использовать для загрузки в модель:
Загрузка изображений
Отображение изображения
Используя matplotlib, мы можем легко отобразить контент и изображения стиля рядом:
Рис. 5. Визуализация изображений контента и стиля
Теперь, когда у нас есть изображения, подготовленные для нейронного переноса стиля, мы можем создать нашу модель VGG-19 и подготовить её для точной настройки. Этот процесс требует большего внимания, но внимательное чтение и программирование приведут вас к результату. В этом разделе мы:
Обратите внимание на комментарии в gist
Загружаем VGG с Functional API
Поскольку в Keras размещена предварительно обученная модель VGG-19, мы можем загрузить модель из Keras Application API. Сначала создадим функцию, чтобы использовать её позже в разделе «Создание подклассов». Эта функция позволяет нам создавать пользовательскую модель VGG с желаемыми слоями, по-прежнему имея доступ к атрибутам модели:
Основная модель с Model Subclassing
Вместо того чтобы сравнивать необработанные промежуточные выходные данные изображения контента и изображения стиля, мы сравним матрицы Грама двух выводов с помощью функции gram_matrix; она даёт результаты точнее:
Модель VGG-19 состоит из 5 блоков со слоями внутри каждого блока, как показано выше. Мы выберем первый свёрточный слой каждого блока, чтобы получить знания о стиле. Поскольку информация промежуточного уровня более ценна для трансферного обучения, мы оставим второй свёрточный слой пятого блока для слоя контента. Следующие строки создают два списка с информацией об этом слое:
Оптимизатор и настройки потерь
Теперь, когда мы можем выводить прогнозы для /информации о/ стиля и содержимого, пришло время настроить оптимизатор нашей модели с помощью Adam и создать пользовательскую функцию потерь:
Пользовательский шаг обучения
Настраиваемый цикл обучения
Теперь, когда всё прочитано, мы можем запустить пользовательский цикл обучения, чтобы оптимизировать веса и получить наилучшие результаты. Запустим модель на 20 эпох и 100 steps_per_epoch [шагов на эпоху]. Это даст нам красивую версию фотографии, которую мы загрузили вначале, в стиле поп-арт. Кроме того, наш цикл будет выводить стилизованную фотографию после каждой эпохи (это временно).
Если вы используете Google Colab, чтобы повторить шаги туториала, убедитесь, что вы включили аппаратный ускоритель в настройках блокнота. Это значительно сократит время обучения.
Сохраняем и отображаем стилизованное изображение
Теперь, когда наша модель завершила обучение, мы можем сохранить стилизованную фотографию контента с помощью API предварительной обработки TensorFlow. Следующая строка сохранит фотографию в вашем окружении:

Рис. 6. Фото и стилизованная версия
Поздравляю!
Русские Блоги
Введение в ИИ: трансферное обучение
Pokemon Dataset
Собирайте изображения покемонов в Интернете, чтобы создавать наборы данных для классификации изображений. Я собрал 5 видов покемонов, это Пикачу, Супер Сон, Дженни Черепаха, Маленький Огненный Дракон, Семя чудо-лягушки.
Ссылка на набор данных: https://pan.baidu.com/s/1Kept7FF88lb8TqPZMD_Yxw Код извлечения: 1sdd
Всего имеется 1168 изображений покемонов, в том числе 234 Пикачу, 239 Super Dream, 223 Дженни Черепаха, 238 Маленьких огненных драконов и 234 Чудо-лягушки.
Набор данных делится следующим образом (60% набор для обучения, 20% набор для проверки, 20% набор для тестирования). Это соотношение не для каждой категории, а всего 1168 человек.

Load Data
Определение наборов данных в PyTorch в основном включает два основных класса: Dataset и DataLoder.
DataSet класс
среди них __len__() Должен возвращать количество выборок в наборе данных, и __getitem__() Реализовать функцию возврата данных образца через индекс
Сначала посмотрите на пример настраиваемого набора данных
Затем нужно провести предварительную обработку изображения.
Image Resize:224*224 for ResNet18
Data Argumentation:Rotate & Crop
После этого __len__() Код функции
в заключение __getitem__() Код функции, это более сложный, потому что у нас есть только строковый путь изображения (путь в форме строки), и нам нужно сначала преобразовать его в данные трехканального изображения. Для этого используется библиотека PIL Image.open(path).convert(‘RGB’) Функция может быть завершена. После того, как изображение прочитано, оно должно пройти серию преобразований, конкретный код выглядит следующим образом
Параметр Normalize рекомендуется PyTorch, просто напишите его напрямую

DataLoader класс
Класс Dataset предназначен для чтения в наборе данных и индексации считанных данных, но одной этой функции недостаточно. В фактическом процессе загрузки набора данных объем наших данных часто очень велик, поэтому также необходимы следующие Особенности:
Прочтите несколько партий за раз: batch_size
Данные можно читать в случайном порядке, перетасовывая порядок данных (перетасовка)
Наборы данных могут загружаться параллельно (с использованием многоядерных процессоров для повышения эффективности загрузки данных)
Для этого необходим класс DataLoader, и в нем обычно используются следующие параметры:
batch_size: размер каждой партии
shuffle: следует ли выполнять операцию перемешивания
num_works: при загрузке данных используются несколько процессов
Класс DataLoader не требует от нас разработки собственного кода, просто используйте его для чтения подкласса созданного нами набора данных.
Полный код выглядит следующим образом:
Build Model
Использование PyTorch для построения ResNet на самом деле упоминалось в моей предыдущей статье (https://wmathor.com/index.php/archives/1389/), я использую его прямо здесь, просто меняя параметры внутри.
Train and Test
При обучении строго следуйте логике обучения и тестирования, то есть в эпоху обучения периодически выполняйте проверку, а затем проверяйте, является ли текущая точность проверки самой высокой, если она самая высокая, сохраните текущие параметры модели. Встаньте. После обучения загрузите лучшую модель и снова протестируйте. Это очень строгая логика обучения. код показан ниже:
На данный момент код, который может работать полностью, выглядит следующим образом:
Transfer Learning
Запустите приведенный выше код, в основном окончательная точность теста может достигать 0,88. Если вы хотите улучшить, вам нужно использовать больше инженерных приемов или настроек
Я лично понимаю роль Transfer Learning. Все мы знаем, что параметры инициализации нейронной сети очень важны. Иногда инициализация не удалась, что может привести к очень плохим конечным результатам. Теперь мы используем сеть, которая была обучена на задаче A, что эквивалентно хорошей инициализации для вас. Вы можете выполнить задачу B на основе этой сети. Если две задачи относительно близки, это преувеличено. В какой-то момент обучение этой сети может потребовать только тонкой настройки, чтобы показать очень хорошие результаты по задаче B.

Сначала получите основной код
PyTorch обучил resnet различных спецификаций, и вам необходимо загрузить его для первого использования. Нам не нужен последний слой resnet18, поэтому используйте list(trained_model.children())[:-1] Выньте все слои, кроме последнего, сохраните его в списке и используйте * Разверните его список, а затем подключитесь к нашему пользовательскому слою Flatten, который используется для выравнивания вывода и отправки его на линейный слой после выравнивания.
Приведенные выше несколько строк кода реализуют Transfer Learning, и нам не нужно самостоятельно реализовывать resnet. Полный код выглядит следующим образом
Окончательная точность теста составляет около 0,94, что намного лучше, чем наша собственная тренировка от 0.



