Как работают искусственный интеллект, машинное и глубокое обучение
Об авторе: Андрей Беляев, технический директор (CTO) исследовательской компании Neurodata Lab.
Умные дома, самоуправляемые автомобили, роботы-помощники… Нас окружают инновационные технологии, в основе которых лежат алгоритмы, по своей специфике напоминающие работу человеческого мозга. Их называют по-разному: алгоритмы с использованием машинного обучения, глубокого обучения, а иногда и вовсе искусственный интеллект (ИИ).
В чем разница между этими названиями?
Все задачи, которые может решать человек или компьютер, можно условно разделить на две категории: рутинные и нерутинные.
К рутинным задачам можно отнести те, где достаточно просто найти универсальный путь решения: например, сложение чисел или измерение температуры воздуха.
Искусственным интеллектом сейчас принято называть все, что способно решать нерутинные задачи на уровне, близком к человеческому, а иногда и лучше. Такие задачи окружают нас везде. Камеры над дорогой вычисляют скорость автомобиля, распознают его знак и высылают штраф, а системы безопасности в метро и аэропортах находят преступников в толпе. Все это сегодня принято считать искусственным интеллектом, хотя в действительности алгоритмы, лежащие в основе каждой такой технологии, уникальны. И только некоторые используют машинное обучение.
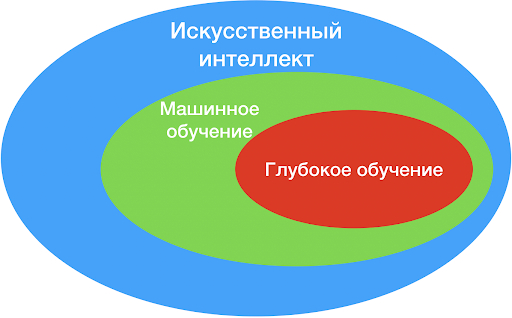
Получается, что машинное обучение — это обучение ИИ
Искусственный интеллект — это название не какого-то отдельного алгоритма, но скорее группы методов, которыми пользуются для решения различного рода задач. Алгоритмы, которые используют подходы с обучением, являются лишь одной из подгрупп всего того множества алгоритмов, что принято называть искусственным интеллектом.
Машинное обучение — это подход, при котором алгоритм «учится» решать задачу. Один из самых простых примеров алгоритма, использующего машинное обучение, это классификация фотографий на те, где изображены кошки и те, где есть собаки:

Допустим, есть несколько тысяч фотографий кошек и несколько тысяч — собак. Эти данные можно загрузить в алгоритм и заставить его «учиться» отличать кошек от собак, «ругая» за ошибки в классификации и «поощряя» за правильные ответы. В зависимости от количества и качества вводных данных, а также от сложности используемого алгоритма после некоторого количества итераций с «наказанием» и «поощрением», получается обученный алгоритм, которой с разным качеством умеет отличать кошек и собак.
Применяя методы машинного обучения, эти же алгоритмы можно «натренировать» и для выполнения более сложных задач — таких как поиск людей на кадре, определение пола и возраста человека и т.д.
Такие алгоритмы можно научить решать задачи любой сложности?
В теории — да. Но на практике мы сталкиваемся с большим количеством проблем, начиная от недостаточного количества данных для обучения, заканчивая невозможностью интерпретировать действия человека при решении такой же задачи. Получается, что невозможно построить алгоритм, который эти действия бы совершал. Хороший пример — автопилотируемый автомобиль. Научить машину держать полосу, входить в повороты и автоматически перестраивать маршрут, если на дороге ремонт, сравнительно несложно, потому что есть понимание, как вел бы себя человек (а значит, как должна вести себя машина) в таких ситуациях.

Однако научить автомобиль принимать решения в чрезвычайных ситуациях гораздо сложнее: проблема в том, что и самому человеку трудно понять, как именно надо поступать в том или ином экстренном случае. Поэтому человек не может показать алгоритмам примеры хорошего и плохого поведения для таких случаев.
А что насчет глубокого обучения? Чем оно отличается от машинного?
Как машинное обучение является подвидом искусственного интеллекта, так и глубокое обучение является подвидом машинного (см. картинку в начале статьи). В глубоком обучении используются те же подходы: алгоритму дают много данных и «ругают» его за ошибки. Разница здесь в том, что сами алгоритмы глубокого обучения устроены гораздо сложнее и часто используют более серьезные математические модели. Сейчас под алгоритмами глубокого обучения практически всегда подразумевают нейронные сети.
Нейронные сети? Как те, что в мозгу у человека?
Такое сравнение действительно часто используется. Нейронная сеть — это последовательность слоев, каждый из которых, в свою очередь, состоит из нейронов, и каждый выполняет свою роль. Есть нейроны (или структуры нейронов), которые учатся выделять важные элементы на изображениях, например шерсть у кошки или собаки; есть те, которые учатся делать выводы, исходя из выделенных элементов — например, если у животного длинные лапы, то, скорее всего, это собака. Эти нейроны объединяются в группы (слои), а они превращаются в единую искусственную нейронную сеть.

И все же можно как-то сравнить процессы внутри нейросети с деятельностью мозга?
Некоторое количество идей, используемых в нейросетях, разработчики почерпнули из знаний об устройстве человеческого мозга. Одни из самых частых задач для нейросетей — это задачи, связанные с работой с изображениями. Для таких задач используют специальный тип нейросетей, внутри которых есть так называемые сверточные слои.
Если говорить упрощенно, смысл этой сверточной нейронной сети в том, чтобы оценивать каждый элемент картинки (пиксель) не отдельно, а в группе с несколькими соседними, благодаря чему можно находить как базовые фигуры (линии, углы, и т.д.), так и объекты целиком. Примерно такой же процесс происходит и в человеческом мозге при обработке визуальной информации. После снятия всех возможных визуальных признаков в нейросети, как и в человеческом мозге, происходит анализ этих признаков, а затем принимается решение: видим мы, допустим, кошку или собаку.

А как происходит процесс обучения?
Процесс обучения алгоритма во многом напоминает процесс обучения человека. Как мы совершаем ошибки и учимся на них (например, что не стоит засовывать руку в кипящую воду), так и алгоритмы, использующие машинное обучение, совершают ошибки, за что получают штраф.
Как работает нейросеть? В качестве примера можно рассмотреть процесс обучения нейросети распознаванию лиц. Чтобы корректно обучить любую нейросеть, нужно сделать две вещи: собрать достаточное количество данных и определить, за что мы будем ее штрафовать. Применительно к этой задаче необходимо собрать несколько десятков фотографий лиц для каждого из людей, которых надо определить, и штрафовать нейросеть за то, что предсказанный ею человек не совпадает с человеком на фотографии.
Что значит «поощрять» и «штрафовать» нейросеть?
С математической точки зрения нейросеть — это функция с большим количеством параметров. Штрафование этой функции за неверное определения лица — это когда мы, упрощенно говоря, корректируем работу функции таким образом, чтобы в будущем она меньше ошибалась. Соответственно, поощрение нейросети — это когда мы ее просто не штрафуем.
Во всех примерах вы рассказываете про конкретные задачи. А можно ли нейросеть научить думать, как человек?
Это уже скорее философский вопрос. Мыслительный процесс напрямую связан с наличием сознания. Нейронная сеть, как и любой другой алгоритм машинного обучения, по своей сути является лишь математической функцией, и умеет решать лишь одну конкретную задачу. Нейросеть, которую учили отличать кошек и собак, не сможет отличить медведя от слона, ведь она даже не знала, что такие существуют. Процессы же анализа данных, которые происходят в голове у человека, намного сложнее чем те, что происходят в нейросети, так что даже при наличии данных, сопоставимых по размеру с массивом информации, которую за жизнь получает человек, сегодня обучить нейросеть думать, как человек, невозможно.
Подписывайтесь и читайте нас в Яндекс.Дзене — технологии, инновации, эко-номика, образование и шеринг в одном канале.
Что такое машинное обучение и как оно работает

Что такое машинное обучение?
Единого определения для machine learning (машинного обучения) пока нет. Но большинство исследователей формулируют его примерно так:
Машинное обучение — это наука о том, как заставить ИИ учиться и действовать как человек, а также сделать так, чтобы он сам постоянно улучшал свое обучение и способности на основе предоставленных нами данных о реальном мире.
Вот как определяют машинное обучение представители ведущих ИТ-компаний и исследовательских центров:
Nvidia: «Это практика использования алгоритмов для анализа данных, изучения их и последующего определения или предсказания чего-либо».
Университет Стэнфорда: «Это наука о том, как заставить компьютеры работать без явного программирования».
McKinsey & Co: «Машинное обучение основано на алгоритмах, которые могут учиться на данных, не полагаясь на программирование на основе базовых правил».
Вашингтонский университет: «Алгоритмы машинного обучения могут сами понять, как выполнять важные задачи, обобщая примеры, которые у них есть».
Университет Карнеги Меллон: «Сфера машинного обучения пытается ответить на вопрос: «Как мы можем создавать компьютерные системы, которые автоматически улучшаются по мере накопления опыта и каковы фундаментальные законы, которые управляют всеми процессами обучения?»
История машинного обучения
Дмитрий Ветров, профессор-исследователь, заведующий Центром глубинного обучения и байесовских методов Факультета компьютерных наук ВШЭ, отмечает: изначально компьютеры использовались для задач, алгоритм решения которых был известен человеку. И только в последние годы пришло понимание, что они могут находить способ решать задачи, для которых алгоритма решения нет или он не известен человеку. Так появился искусственный интеллект в широком смысле и технологии машинного обучения в частности.
Как связаны машинное и глубокое обучение, ИИ и нейросети
Нейросети — один из видов машинного обучения.
Глубокое обучение — это один из видов архитектуры нейросетей.
Глубокое обучение также включает в себя исследование и разработку алгоритмов для машинного обучения. В частности — обучения правильному представлению данных на нескольких уровнях абстракции. Системы глубокого обучения за последние десять лет добились особенных успехов в таких областях как обнаружение и распознавание объектов, преобразование текста в речь, поиск информации.
Какие задачи решает машинное обучение?
С помощью машинного обучения ИИ может анализировать данные, запоминать информацию, строить прогнозы, воспроизводить готовые модели и выбирать наиболее подходящий вариант из предложенных.
Особенно полезны такие системы там, где необходимо выполнять огромные объемы вычислений: например, банковский скоринг (расчет кредитного рейтинга), аналитика в области маркетинговых и статистических исследований, бизнес-планирование, демографические исследования, инвестиции, поиск фейковых новостей и мошеннических сайтов.
В Леруа Мерлен используют Big Data и Machine Learning, чтобы находить остатки товара на складах.
В маркетинге и электронной коммерции машинное обучение помогает настроить сервисы и приложения так, чтобы они выдавали персональные рекомендации.
Стриминговый сервис Spotify с помощью машинного обучения составляет для каждого пользователя персональные подборки треков на основе того, какую музыку он слушает.
Сегодня ключевые исследования сфокусированы на разработке машинного обучения с эффективным использованием данных — то есть систем глубокого обучения, которые могут обучаться более эффективно, с той же производительностью, за меньшее время и с меньшими объемами данных. Такие системы востребованы в персонализированном здравоохранении, обучении роботов с подкреплением, анализе эмоций.
Китайский производитель «умных» пылесосов Ecovacs Robotics обучил свои пылесосы распознавать носки, провода и другие посторонние предметы на полу с помощью множества фотографий и машинного обучения.
«Умная» камера на базе микрокомпьютера Raspberry Pi 3B+ с помощью фреймворка TensorFlow Light научилась распознавать улыбку и делать снимок ровно в этот момент, а также — выполнять голосовые команды.
В сфере инвестиций алгоритмы на базе машинного обучения анализируют рынок, отслеживают новости и подбирают активы, которые выгоднее всего покупать именно сейчас. При этом с помощью предикативной аналитики система может предсказать, как будет меняться стоимость тех или иных акций за конкретный период и корректирует свои данные после каждого важного события в отрасли.
Согласно исследованию BarclayHedge, более 50% хедж-фондов используют ИИ и машинное обучение для принятия инвестиционных решений, а две трети — для генерации торговых идей и оптимизации портфелей.
Наконец, машинное обучение способствует настоящим прорывам в науке.
Нейросеть AlphaFold от DeepMind в 2020 году смогла расшифровать механизм сворачивания белка. Над этой задачей ученые-биологи бились больше 50 лет.
Как устроено машинное обучение
По словам Дмитрия Ветрова, процесс машинного обучения выглядит следующим образом.
Есть большое число однотипных задач, в которых известны условие и правильный ответ или один из возможных ответов. Например, машинный перевод, где условие — фраза на одном языке, а правильный ответ — ее перевод на другой язык.
Модель машинного обучения, например, глубинная нейронная сеть, работает по принципу «черного ящика», который принимает на вход условие задачи, а на выходе выдает произвольный ответ. Например, какой-либо текст на втором языке.
У «черного ящика» есть дополнительные параметры, которые влияют на то, как будет обрабатываться входной сигнал. Процесс обучения нейросети заключается в поиске таких значений параметров, при которых она будет выдавать ответ, максимально близкий к правильному. Когда мы настроим параметры нужным образом, нейросеть сможет правильно (или максимально близко к этому) решать и другие задачи того же типа — даже если никогда не знала ответов к ним.
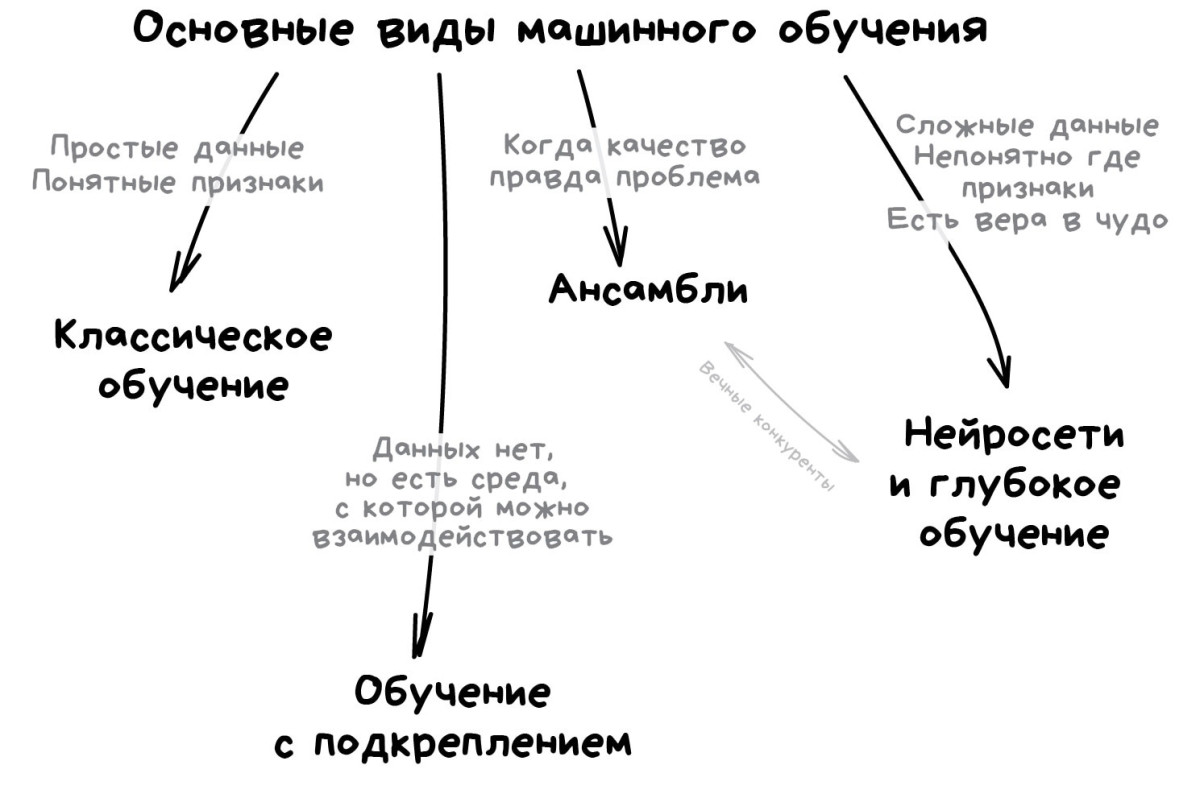
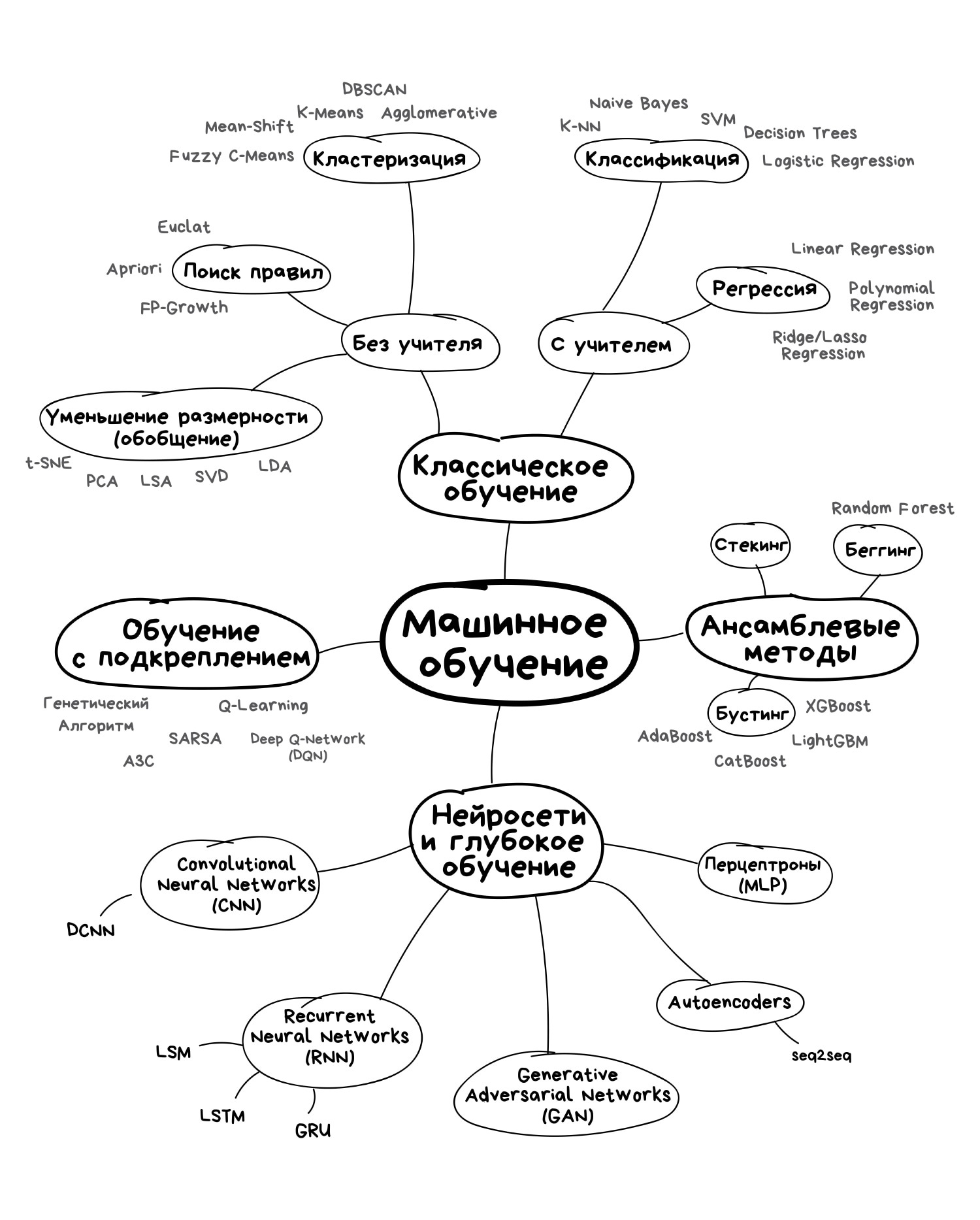
Основные виды машинного обучения
1. Классическое обучение
Это простейшие алгоритмы, которые являются прямыми наследниками вычислительных машин 1950-х годов. Они изначально решали формальные задачи — такие, как поиск закономерностей в расчетах и вычисление траектории объектов. Сегодня алгоритмы на базе классического обучения — самые распространенные. Именно они формируют блок рекомендаций на многих платформах.
Но классическое обучение тоже бывает разным:
Обучение с учителем — когда у машины есть некий учитель, который знает, какой ответ правильный. Это значит, что исходные данные уже размечены (отсортированы) нужным образом, и машине остается лишь определить объект с нужным признаком или вычислить результат.
Такие модели используют в спам-фильтрах, распознавании языков и рукописного текста, выявлении мошеннических операций, расчете финансовых показателей, скоринге при выдаче кредита. В медицинской диагностике классификация помогает выявлять аномалии — то есть возможные признаки заболеваний на снимках пациентов.
Обучение без учителя — когда машина сама должна найти среди хаотичных данных верное решение и отсортировать объекты по неизвестным признакам. Например, определить, где на фото собака.
Эта модель возникла в 1990-х годах и на практике используется гораздо реже. Ее применяют для данных, которые просто невозможно разметить из-за их колоссального объема. Такие алгоритмы применяют для риск-менеджмента, сжатия изображений, объединения близких точек на карте, сегментации рынка, прогноза акций и распродаж в ретейле, мерчендайзинга. По такому принципу работает алгоритм iPhoto, который находит на фотографиях лица (не зная, чьи они) и объединяет их в альбомы.
2. Обучение с подкреплением
Это более сложный вид обучения, где ИИ нужно не просто анализировать данные, а действовать самостоятельно в реальной среде — будь то улица, дом или видеоигра. Задача робота — свести ошибки к минимуму, за что он получает возможность продолжать работу без препятствий и сбоев.
Обучение с подкреплением инженеры используют для беспилотников, роботов-пылесосов, торговли на фондовом рынке, управления ресурсами компании. Именно так алгоритму AlphaGo удалось обыграть чемпиона по игре Го: просчитать все возможные комбинации, как в шахматах, здесь было невозможно.
3. Ансамбли
Это группы алгоритмов, которые используют сразу несколько методов машинного обучения и исправляют ошибки друг друга. Их получают тремя способами:
Ансамбли работают в поисковых системах, компьютерном зрении, распознавании лиц и других объектов.
4. Нейросети и глубокое обучение
Самый сложный уровень обучения ИИ. Нейросети моделируют работу человеческого мозга, который состоит из нейронов, постоянно формирующих между собой новые связи. Очень условно можно определить их как сеть со множеством входов и одним выходом. Нейроны образуют слои, через которые последовательно проходит сигнал. Все это соединено нейронными связями — каналами, по которым передаются данные. У каждого канала свой «вес» — параметр, который влияет на данные, которые он передает.
ИИ собирает данные со всех входов, оценивая их вес по заданным параметрами, затем выполняет нужное действие и выдает результат. Сначала он получается случайным, но затем через множество циклов становится все более точным. Хорошо обученная нейросеть работает, как обычный алгоритм или точнее.
Настоящим прорывом в этой области стало глубокое обучение, которое обучает нейросети на нескольких уровнях абстракций.
Здесь используют две главных архитектуры:
Нейросети с глубоким обучением требуют огромных массивов данных и технических ресурсов. Именно они лежат в основе машинного перевода, чат-ботов и голосовых помощников, создают музыку и дипфейки, обрабатывают фото и видео.
Проблемы машинного обучения
Перспективы машинного обучения: не начнет ли ИИ думать за нас?
Вопрос о том, не сделает ли машинное обучение ИИ умнее человека, изначально не совсем корректный. Дело в том, что в природе нет универсальной иерархии в плане интеллекта. Мы по умолчанию считаем себя умнее остальных существ, но, к примеру, белка способна запоминать местонахождения тысячи тайников с запасами, что не под силу даже очень умному человеку. А у осьминогов каждое щупальце способно мыслить и действовать самостоятельно.
Так же и с ИИ: он уже превосходит нас во всем, что касается сложных вычислений, но по-прежнему не способен сам ставить себе новые задачи и решать их, подбирая нужные данные и условия. Это ограничение в последние годы пытаются преодолеть в рамках сильного ИИ, но пока безуспешно. Надежду на решение этой проблемы внушают квантовые компьютеры, которые выходят за пределы обычных вычислений.
Зато мы в ближайшем будущем сможем заметно расширить свои возможности с помощью ИИ, передавая ему рутинные и затратные операции, общаясь и управляя техникой при помощи нейроинтерфейсов.
Искусственный интеллект, машинное обучение и глубокое обучение: в чём разница
Компьютер запросто диагностирует рак, управляет автомобилем и умеет обучаться. Почему же машины пока не захватили власть над человечеством?


Мы пользуемся Google-картами, позволяем сайтам подбирать для нас интересные фильмы и советовать, что купить. И, в общем-то, слышали, что под капотом всех этих умных вещей — искусственный интеллект, машинное обучение и deep learning. Но сможете ли вы с ходу отличить одно от другого? Разбираемся на примерах.
Что такое искусственный интеллект
Искусственный интеллект (англ. artificial intelligence) — это способность компьютера обучаться, принимать решения и выполнять действия, свойственные человеческому интеллекту.
Кроме того, ИИ — это наука на стыке математики, биологии, психологии, кибернетики и ещё кучи всего. Она изучает технологии, которые позволяют человеку писать «интеллектуальные» программы и учить компьютеры решать задачи самостоятельно. Главная задача ИИ — понять, как устроен человеческий интеллект, и смоделировать его.
В области искусственного интеллекта есть подразделы. К ним относятся робототехника, наука о компьютерном зрении, обработка естественного языка и машинное обучение.
Хотите знать, может ли машина мыслить и чувствовать как человек? Приходите на курс «Философия искусственного интеллекта». Здесь вы получите новые знания об ИИ, обсудите актуальные вопросы с преподавателями и однокурсниками и прокачаете навык публичных выступлений.

Пишет про digital и машинное обучение для корпоративных блогов. Топ-автор в категории «Искусственный интеллект» на Medium. Kaggle-эксперт.
Каким бывает искусственный интеллект
Исследователи обычно делят ИИ на три группы:
Слабый ИИ (Weak, или Narrow AI)
Слабый интеллект — тот, что нам уже удалось создать. Такой ИИ способен решать определённую задачу. Зачастую даже лучше, чем человек. Например, как Deep Blue — компьютерная программа, которая обыграла Гарри Каспарова в шахматы ещё в 1996 году. Но такая Deep Blue не умеет делать ничего другого и никогда этому не научится. Слабый ИИ используют в медицине, логистике, банковском деле, бизнесе:
Это несколько примеров, в реальности применений намного больше.
Сильный ИИ (Strong, или General AI)
Как выглядел бы сильный искусственный интеллект, можно увидеть в игре Detroit: Become Human.
Во вселенной Detroit роботы способны учиться, мыслить, чувствовать, осознавать себя и принимать решения. Одним словом, становятся похожи на человека. А в обычной жизни ближе всего к General AI чат-боты и виртуальные ассистенты, которые имитируют человеческое общение. Здесь ключевое слово — имитируют. Siri или Алиса не думают — и неспособны принимать решения в ситуациях, которым их не обучили. Сильный искусственный интеллект пока остаётся мечтой.
Суперинтеллект (Superintelligence)
Суперинтеллект мы не только не создали, но и не имеем пока что ни малейшего представления, как это сделать и можно ли вообще. Это не просто умные машины, а компьютеры, которые во всём превосходят людей. Проще говоря, что-то из области фантастики.
Машинное обучение: как учится ИИ
Машинное обучение (англ. machine learning) — это один из разделов науки об ИИ. Здесь используются алгоритмы для анализа данных, получения выводов или предсказаний в отношении чего-либо. Вместо того чтобы кодировать набор команд вручную, машину обучают и дают ей возможность научиться выполнять поставленную задачу самостоятельно.
Чтобы машина могла принимать решения, необходимы три вещи:
В машинном обучении много разных алгоритмов. Один из самых простых — линейная регрессия. Её применяют, если есть линейная зависимость между переменными. Пример: чем больше сумма заказа, тем больше вы оставите чаевых. По имеющимся данным можно предсказать сумму чаевых в будущем. В общем-то, простая математика.
Есть байесовские алгоритмы. В их основе применение теоремы Байеса и теории вероятности. Эти алгоритмы используют для работы с текстовыми документами — например, для спам-фильтрации. Программе нужно дать наборы данных по категориям «спам» и «не спам». Дальше алгоритм будет самостоятельно оценивать вероятность того, что слова «Бесплатные туры для пенсионеров» и «Закажи маме тур, пожалуйста» относятся к той или иной категории.
А ещё есть нейронные сети, о них вы наверняка слышали. Они относятся к методам глубокого машинного обучения, и об этом чуть подробнее.
Deep learning: глубокое обучение для разных целей
Глубокое обучение — подраздел машинного обучения. Алгоритмам глубокого обучения не нужен учитель, только заранее подготовленные (размеченные) данные.
Самый популярный, но не единственный метод глубокого обучения, — искусственные нейронные сети (ИНС). Они больше всего похожи на то, как устроен человеческий мозг.
Нейронные сети — это набор связанных единиц (нейронов) и нейронных связей (синапсов). Каждое соединение передаёт сигнал от одного нейрона к другому, как в мозге человека. Обычно нейроны и синапсы организованы в слои, чтобы обрабатывать информацию. Первый слой нейросети — это вход, который получает данные. Последний — выход, результат работы. Например, несколько категорий, к одной из которых мы просим отнести то, что было отправлено на вход. И между ними — скрытые слои, которые выполняют преобразование.
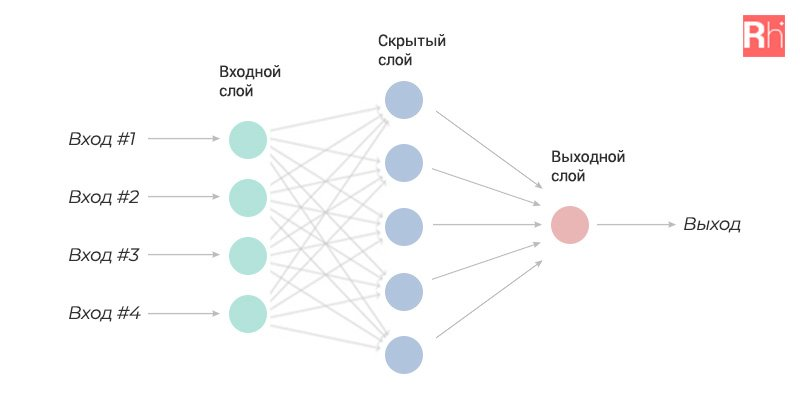
По сути, скрытые слои выполняют какую-то математическую функцию. Мы её не задаём, программа сама учится выводить результат. Можно научить нейросеть классифицировать изображения или находить на изображении нужный объект. Помните, как reCAPTCHA просит найти все изображения грузовиков или светофоров, чтобы доказать, что вы не робот? Нейронная сеть выполняет то же самое, что и наш мозг, — видит знакомые элементы и понимает: «О, кажется, это грузовик!»
А ещё нейросети могут генерировать объекты: музыку, тексты, изображения. Например, компания Botnik скормила нейросети все книги про Гарри Поттера и попросила написать свою. Получился «Гарри Поттер и портрет того, что выглядит как огромная куча пепла». Звучит немного странно, но как минимум с точки зрения грамматики это сочинение имеет смысл.
Сегодня нейронные сети могут применяться практически для любой задачи. Например, при диагностике рака, прогнозировании продаж, идентификации лиц в системах безопасности, машинных переводах, обработке фотографий и музыки.
Чтобы обучить нейросеть, нужны гигантские наборы тщательно отобранных данных. Например, для распознавания сортов огурцов нужно обработать 1,5 млн разных фотографий. Не получится просто слить рандомные картинки или текст из интернета — их нужно подготовить: привести к одному формату и удалить то, что точно не подходит (например, мы классифицируем пиццу, а в наборе данных у нас фото грузовика). На разметку данных — подготовку и систематизацию — уходят тысячи человеко-часов.
Чтобы создать новую нейросеть, требуется задать алгоритм, прогнать через него все данные, протестировать и неоднократно оптимизировать. Это сложно и долго. Поэтому иногда проще воспользоваться более простыми алгоритмами — например, регрессией.
Подведём итоги
Искусственный интеллект — одновременно и наука, которая помогает создавать «умные» машины, и способность компьютера обучаться и принимать решения.
Машинное обучение — одна из областей искусственного интеллекта. МО использует алгоритмы для анализа данных и получения выводов.
А глубокое обучение — лишь один из методов машинного обучения, в рамках которого компьютер учится без учителя подспудно, с помощью данных.
Если чувствуете, что вас привлекает проектирование машинного интеллекта, продолжить образование можно на нашем курсе. Вы научитесь писать алгоритмы, собирать и сортировать данные и получите престижную профессию Data Scientist — специалист по машинному обучению.



