Сообщения HTTP состоят из текстовой информации в кодировке ASCII, записанной в несколько строк. В HTTP/1.1 и более ранних версиях они пересылались в качестве обычного текста. В HTTP/2 текстовое сообщение разделяется на фреймы, что позволяет выполнить оптимизацию и повысить производительность.
Механизм бинарного фрагментирования в HTTP/2 разработан так, чтобы не потребовалось вносить изменения в имеющиеся APIs и конфигурационные файлы: он вполне прозрачен для пользователя.
HTTP запросы и ответы имеют близкую структуру. Они состоят из:
Запросы HTTP
Стартовая строка
Заголовки
Заголовки запроса HTTP имеют стандартную для заголовка HTTP структуру: не зависящая от регистра строка, завершаемая ( ‘:’ ) и значение, структура которого определяется заголовком. Весь заголовок, включая значение, представляет собой одну строку, которая может быть довольно длинной.
Существует множество заголовков запроса. Их можно разделить на несколько групп:
Тела можно грубо разделить на две категории:
Ответы HTTP
Строка статуса (Status line)
Стартовая строка ответа HTTP, называемая строкой статуса, содержит следующую информацию:
Пример строки статуса: HTTP/1.1 404 Not Found.
Заголовки
Заголовки ответов HTTP имеют ту же структуру, что и все остальные заголовки: не зависящая от регистра строка, завершаемая двоеточием ( ‘:’ ) и значение, структура которого определяется типом заголовка. Весь заголовок, включая значение, представляет собой одну строку.
Существует множество заголовков ответов. Их можно разделить на несколько групп:
Тела можно разделить на три категории:
Фреймы HTTP/2
Сообщения HTTP/1.x имеют несколько недостатков в отношении производительности:
Фреймы HTTP сейчас прозрачны для веб-разработчиков. Это дополнительный шаг, который HTTP/2 делает по отношению к сообщениям HTTP/1.1 и лежащему в основе транспортному протоколу. Для реализации фреймов HTTP веб-разработчикам не требуется вносить изменения в имеющиеся APIs; если HTTP/2 доступен и на сервере, и на клиенте, он включается и используется.
Заключение
Сообщения HTTP играют ключевую роль в использовании HTTP; они имеют простую структуру и хорошо расширяемы. Механизм фреймов в HTTP/2 добавляет ещё один промежуточный уровень между синтаксисом HTTP/1.x и используемым им транспортным протоколом, не проводя фундаментальных изменений: создаётся надстройка над уже зарекомендовавшими себя методами.
Протокол HTTP¶
HTTP (HyperText Transfer Protocol — протокол передачи гипертекста) — символьно-ориентированный клиент-серверный протокол прикладного уровня без сохранения состояния, используемый сервисом World Wide Web.
Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier – уникальный идентификатор ресурса) в запросе клиента. Основными ресурсами являются хранящиеся на сервере файлы, но ими могут быть и другие логические (напр. каталог на сервере) или абстрактные объекты (напр. ISBN). Протокол HTTP позволяет указать способ представления (кодирования) одного и того же ресурса по различным параметрам: mime-типу, языку и т. д. Благодаря этой возможности клиент и веб-сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
Структура протокола¶
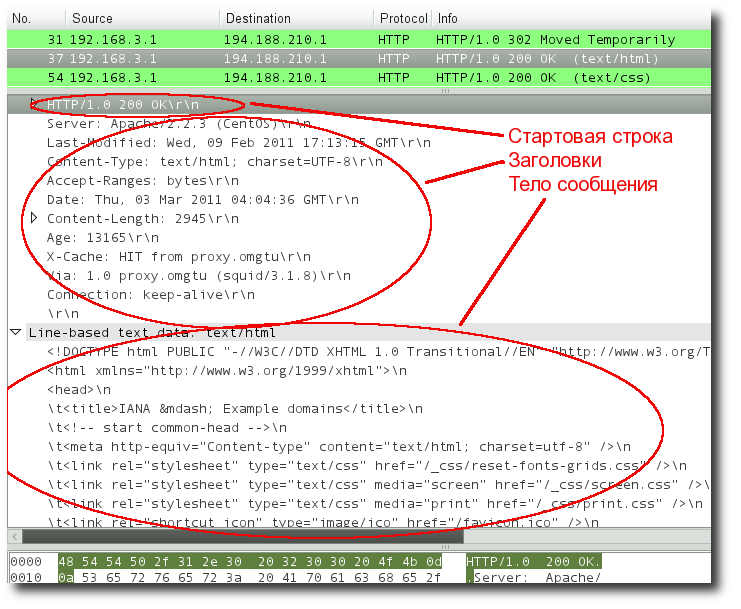
Структура протокола определяет, что каждое HTTP-сообщение состоит из трёх частей (рис. 1), которые передаются в следующем порядке:
Рис. 1. Структура протокола HTTP (дамп пакета, полученный сниффером Wireshark)
Стартовая строка HTTP¶
Cтартовая строка является обязательным элементом, так как указывает на тип запроса/ответа, заголовки и тело сообщения могут отсутствовать.
Стартовые строки различаются для запроса и ответа. Строка запроса выглядит так:
Стартовая строка ответа сервера имеет следующий формат:
Например, на предыдущий наш запрос клиентом данной страницы сервер ответил строкой:
Методы протокола¶
Метод HTTP (англ. HTTP Method) — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами (Табл. 1). Названия метода чувствительны к регистру.
Таблица 1. Методы протокола HTTP
Метод
Краткое описание
OPTIONS
Используется для определения возможностей веб-сервера или параметров соединения для конкретного ресурса. Предполагается, что запрос клиента может содержать тело сообщения для указания интересующих его сведений. Формат тела и порядок работы с ним в настоящий момент не определён. Сервер пока должен его игнорировать. Аналогичная ситуация и с телом в ответе сервера.
Для того чтобы узнать возможности всего сервера, клиент должен указать в URI звёздочку — «*». Запросы «OPTIONS * HTTP/1.1» могут также применяться для проверки работоспособности сервера (аналогично «пингованию») и тестирования на предмет поддержки сервером протокола HTTP версии 1.1.
Результат выполнения этого метода не кэшируется.
Используется для запроса содержимого указанного ресурса. С помощью метода GET можно также начать какой-либо процесс. В этом случае в тело ответного сообщения следует включить информацию о ходе выполнения процесса. Клиент может передавать параметры выполнения запроса в URI целевого ресурса после символа «?»: GET /path/resource?param1=value1¶m2=value2 HTTP/1.1
Согласно стандарту HTTP, запросы типа GET считаются идемпотентными[4] — многократное повторение одного и того же запроса GET должно приводить к одинаковым результатам (при условии, что сам ресурс не изменился за время между запросами). Это позволяет кэшировать ответы на запросы GET.
Кроме обычного метода GET, различают ещё условный GET и частичный GET. Условные запросы GET содержат заголовки If-Modified-Since, If-Match, If-Range и подобные. Частичные GET содержат в запросе Range. Порядок выполнения подобных запросов определён стандартами отдельно.
Аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения.
Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше копия ресурса помечается как устаревшая.
Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом POST и он помещает их на страницу. При этом передаваемые данные (в примере с блогами — текст комментария) включаются в тело запроса. Аналогично с помощью метода POST обычно загружаются файлы.
В отличие от метода GET, метод POST не считается идемпотентным[4], то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться одна копия этого комментария).
При результатах выполнения 200 (Ok) и 204 (No Content) в тело ответа следует включить сообщение об итоге выполнения запроса. Если был создан ресурс, то серверу следует вернуть ответ 201 (Created) с указанием URI нового ресурса в заголовке Location.
Сообщение ответа сервера на выполнение метода POST не кэшируется.
Применяется для загрузки содержимого запроса на указанный в запросе URI. Если по заданному URI не существовало ресурса, то сервер создаёт его и возвращает статус 201 (Created). Если же был изменён ресурс, то сервер возвращает 200 (Ok) или 204 (No Content). Сервер не должен игнорировать некорректные заголовки Content-* передаваемые клиентом вместе с сообщением. Если какой-то из этих заголовков не может быть распознан или не допустим при текущих условиях, то необходимо вернуть код ошибки 501 (Not Implemented).
Фундаментальное различие методов POST и PUT заключается в понимании предназначений URI ресурсов. Метод POST предполагает, что по указанному URI будет производиться обработка передаваемого клиентом содержимого. Используя PUT, клиент предполагает, что загружаемое содержимое соответствуют находящемуся по данному URI ресурсу.
Сообщения ответов сервера на метод PUT не кэшируются.
Аналогично PUT, но применяется только к фрагменту ресурса.
Удаляет указанный ресурс.
Возвращает полученный запрос так, что клиент может увидеть, что промежуточные сервера добавляют или изменяют в запросе.
Устанавливает связь указанного ресурса с другими.
Убирает связь указанного ресурса с другими.
Каждый сервер обязан поддерживать как минимум методы GET и HEAD. Если сервер не распознал указанный клиентом метод, то он должен вернуть статус 501 (Not Implemented). Если серверу метод известен, но он не применим к конкретному ресурсу, то возвращается сообщение с кодом 405 (Method Not Allowed). В обоих случаях серверу следует включить в сообщение ответа заголовок Allow со списком поддерживаемых методов.
Наиболее востребованными являются методы GET и POST — на человеко-ориентированных ресурсах, POST — роботами поисковых машин и оффлайн-браузерами.
Прокси-сервер
Коды состояния¶
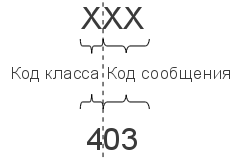
Код состояния информирует клиента о результатах выполнения запроса и определяет его дальнейшее поведение. Набор кодов состояния является стандартом, и все они описаны в соответствующих документах RFC.
Рис. 1. Структура кода состояния HTTP
Введение новых кодов должно производиться только после согласования с IETF. Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода.
Применяемые в настоящее время классы кодов состояния и некоторые примеры ответов сервера приведены в табл. 2.
Таблица 2. Коды состояния протокола HTTP
Класс кодов
Краткое описание
1xx Informational (Информационный)
В этот класс выделены коды, информирующие о процессе передачи. В HTTP/1.0 сообщения с такими кодами должны игнорироваться. В HTTP/1.1 клиент должен быть готов принять этот класс сообщений как обычный ответ, но ничего отправлять серверу не нужно. Сами сообщения от сервера содержат только стартовую строку ответа и, если требуется, несколько специфичных для ответа полей заголовка. Прокси-сервера подобные сообщения должны отправлять дальше от сервера к клиенту.
Примеры ответов сервера:
Сообщения данного класса информируют о случаях успешного принятия и обработки запроса клиента. В зависимости от статуса сервер может ещё передать заголовки и тело сообщения.
Примеры ответов сервера:
Коды статуса класса 3xx сообщают клиенту, что для успешного выполнения операции нужно произвести следующий запрос к другому URI. В большинстве случаев новый адрес указывается в поле Location заголовка. Клиент в этом случае должен, как правило, произвести автоматический переход (жарг. «редирект»).
Обратите внимание, что при обращении к следующему ресурсу можно получить ответ из этого же класса кодов. Может получиться даже длинная цепочка из перенаправлений, которые, если будут производиться автоматически, создадут чрезмерную нагрузку на оборудование. Поэтому разработчики протокола HTTP настоятельно рекомендуют после второго подряд подобного ответа обязательно запрашивать подтверждение на перенаправление у пользователя (раньше рекомендовалось после 5-го). За этим следить обязан клиент, так как текущий сервер может перенаправить клиента на ресурс другого сервера. Клиент также должен предотвратить попадание в круговые перенаправления.
Примеры ответов сервера:
Класс кодов 4xx предназначен для указания ошибок со стороны клиента. При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя.
Примеры ответов сервера:
Коды 5xx выделены под случаи неудачного выполнения операции по вине сервера. Для всех ситуаций, кроме использования метода HEAD, сервер должен включать в тело сообщения объяснение, которое клиент отобразит пользователю.
Примеры ответов сервера:
Заголовки HTTP¶
Заголовок HTTP (HTTP Header) — это строка в HTTP-сообщении, содержащая разделённую двоеточием пару вида «параметр-значение». Формат заголовка соответствует общему формату заголовков текстовых сетевых сообщений ARPA (RFC 822). Как правило, браузер и веб-сервер включают в сообщения более чем по одному заголовку. Заголовки должны отправляться раньше тела сообщения и отделяться от него хотя бы одной пустой строкой (CRLF).
Название параметра должно состоять минимум из одного печатного символа (ASCII-коды от 33 до 126). После названия сразу должен следовать символ двоеточия. Значение может содержать любые символы ASCII, кроме перевода строки (CR, код 10) и возврата каретки (LF, код 13).
Пробельные символы в начале и конце значения обрезаются. Последовательность нескольких пробельных символов внутри значения может восприниматься как один пробел. Регистр символов в названии и значении не имеет значения (если иное не предусмотрено форматом поля).
Пример заголовков ответа сервера:
Все HTTP-заголовки разделяются на четыре основных группы:
Сущности (entity, в переводах также встречается название “объект”) — это полезная информация, передаваемая в запросе или ответе. Сущность состоит из метаинформации (заголовки) и непосредственно содержания (тело сообщения).
В отдельный класс заголовки сущности выделены, чтобы не путать их с заголовками запроса или заголовками ответа при передаче множественного содержимого (multipart/ * ). Заголовки запроса и ответа, как и основные заголовки, описывают всё сообщение в целом и размещаются только в начальном блоке заголовков, в то время как заголовки сущности характеризуют содержимое каждой части в отдельности, располагаясь непосредственно перед её телом.
В таблице 3 приведено краткое описание некоторых HTTP-заголовков.
Таблица 3. Заголовки HTTP
В листинге 1 приведен фрагмент дампа заголовков при подключении к серверу http://example.org
Листинг 1. Заголовки HTTP
Тело сообщения¶
Тело HTTP сообщения (message-body), если оно присутствует, используется для передачи сущности, связанной с запросом или ответом. Тело сообщения (message-body) отличается от тела сущности (entity-body) только в том случае, когда при передаче применяется кодирование, указанное в заголовке Transfer-Encoding. В остальных случаях тело сообщения идентично телу сущности.
Присутствие тела сообщения в запросе отмечается добавлением к заголовкам запроса поля заголовка Content-Length или Transfer-Encoding. Тело сообщения (message-body) может быть добавлено в запрос только когда метод запроса допускает тело объекта (entity-body).
Все ответы содержат тело сообщения, возможно нулевой длины, кроме ответов на запрос методом HEAD и ответов с кодами статуса 1xx (Информационные), 204 (Нет содержимого, No Content), и 304 (Не модифицирован, Not Modified).
HTTP Headers для «чайников»
Russian (Pусский) translation by Yuri Yuriev (you can also view the original English article)
Являетесь вы программистом или нет, вы видели его повсюду в Интернете. На данный момент в адресной строке браузера отображается нечто, что начинается с «https: //». Даже ваш первый скрипт Hello World отправил HTTP-header без вашего понимания. В этой статье мы собираемся узнать об основах HTTP-заголовков и о том, как их можно использовать в наших веб-приложениях.
Что такое HTTP Headers?
HTTP значит «Hypertext Transfer Protocol» (Протокол передачи гипертекста). Всемирная паутина использует этот протокол. Он был создан в начале 1990-х годов. Почти всё, что вы видите в вашем браузере, передаётся на ваш компьютер через HTTP. Например, когда вы открыли страницу этой статьи, ваш браузер отправил более 40 HTTP-запросов и получил HTTP-ответы для каждого из них.
Заголовки HTTP являются основной частью этих HTTP-запросов и ответов, и они несут информацию о браузере клиента, запрошенной странице, сервере и многом другом.
Пример
Когда вы вводите URL-адрес в адресной строке, ваш браузер отправляет HTTP-запрос, и он может выглядеть так:
После этого запроса ваш браузер получает ответ HTTP, который может выглядеть так:
Когда вы смотрите на исходный код веб-страницы в своём браузере, вы видите только часть HTML, а не заголовки HTTP, хотя они фактически были переданы вместе.
Эти HTTP-запросы также отправляются и принимаются для других вещей, таких как изображения, CSS-файлы, файлы JavaScript и т. д. Именно поэтому я сказал ранее, что ваш браузер отправил не менее 40 или более HTTP-запросов, поскольку вы загрузили только эту страницу статьи.
Теперь давайте рассмотрим структуру более подробно.
Как увидеть HTTP Headers
Для анализа HTTP-заголовков я использую следующие расширения Firefox:
Далее в этой статье мы увидим примеры кода в PHP.
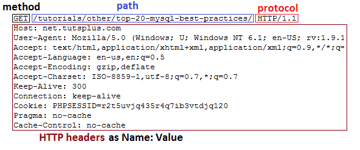
Структура запроса HTTP
Первая строка HTTP-запроса называется линией запроса и состоит из трёх частей:
Остальная часть запроса содержит HTTP headers как пары «Name: Value» в каждой строке. Они содержат различную информацию о HTTP-запросе и вашем браузере. Например, строка «User-Agent» предоставляет информацию о версии браузера и операционной системе, которую вы используете. «Accept-Encoding» сообщает серверу, может ли ваш браузер принимать сжатый output, например gzip.
Возможно, вы заметили, что данные cookie также передаются внутри HTTP-заголовка. И если бы ссылочный url, это было бы в header тоже.
Большинство этих заголовков являются необязательными. Этот HTTP-запрос мог быть таким же маленьким:
И вы всё равно получите правильный ответ от веб-сервера.
Методы запроса
Три наиболее часто используемых метода запроса: GET, POST и HEAD. Вы, вероятно, уже знакомы с первыми двумя, начиная с написания html-форм.
GET: получение документа
Это основной метод, используемый для извлечения html, изображений, JavaScript, CSS и т. д. С использованием этого метода запрошено большинство данных, загружаемых в ваш браузер.
Например, при загрузке статьи Nettuts +, самая первая строка HTTP-запроса выглядит так:
Как только html загрузится, браузер начнет отправлять GET-запрос изображений, который может выглядеть так:
Веб-формы можно настроить под метод GET. Вот пример.
Когда эта форма отправлена, HTTP-запрос начинается так:
Вы можете видеть, что каждый ввод формы был добавлен в строку запроса.
POST: отправка данных на сервер
Даже если вы можете отправлять данные на сервер с помощью GET и строки запроса, во многих случаях POST будет предпочтительнее. Отправка больших объёмов данных с помощью GET нецелесообразна и имеет ограничения.
Запросы POST чаще всего отправляются веб-формами. Давайте изменим предыдущий пример формы на метод POST.
Отправка этой формы создает HTTP-запрос следующим образом:
Здесь нужно отметить три важных момента:
Запросы POST метода также могут быть сделаны через AJAX, приложения, cURL и т. д. И все формы загрузки файлов необходимы для использования метода POST.
HEAD: получение информации заголовка
HEAD идентичен GET, за исключением того, что сервер не возвращает содержимое HTTP-ответа. Когда вы отправляете запрос HEAD, это означает, что вас интересуют только код ответа и HTTP headers, а не сам документ.
«Когда вы отправляете запрос HEAD, это означает, что вас интересуют только код ответа и HTTP headers, а не сам документ».
С помощью этого метода браузер может проверить, был ли документ изменён для целей caching. Он также может проверить, существует ли документ вообще.
Например, если у вас много ссылок на веб-сайте, вы можете периодически отправлять HEAD-запросы каждой из них, чтобы проверить наличие неработающих ссылок. Это будет намного быстрее, чем при использовании GET.
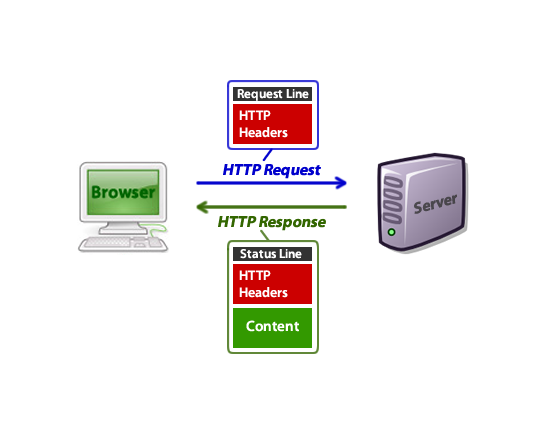
Структура ответа HTTP
После того, как браузер отправляет HTTP-запрос, сервер отвечает HTTP-ответом. Исключая контент, он выглядит так:
Первой порцией данных является протокол. Обычно это снова HTTP/1.x или HTTP/1.1 на современных серверах.
Мы все видели «404» pages. Это число фактически приходит из части кода состояния HTTP-ответа. Если запрос GET будет создан для path, который сервер не может найти, он ответил бы 404, а не 200.
Остальная часть ответа содержит headers так же, как HTTP-запрос. Эти значения могут содержать информацию о софте сервера при последнем изменении страницы/файла, типе mime и прочее.
Опять же, большинство этих headers на самом деле являются необязательными.
Коды статуса HTTP
200 OK
Как упоминалось ранее, этот код состояния отправляется в ответ на успешный запрос.
206 Partial Content
Если приложение запрашивает только диапазон запрошенного файла, возвращается код 206.
Это часто используется с менеджерами закачек, которые могут остановить и возобновить загрузку или разделить загрузку на части.
404 Not Found
Когда запрашиваемая страница или файл не найдена, сервер отправляет код ответа 404.
401 Unauthorized
Защищённые паролем веб-страницы отправляют этот код. Если вы не ввели логин правильно, вы можете увидеть следующее в вашем браузере.
Обратите внимание, что это относится только к страницам, защищённым паролем HTTP, которые вызывают запросы для входа следующим образом:
403 Forbidden
Если вам не разрешен доступ к странице, этот код может быть отправлен в ваш браузер. Это часто происходит, когда вы пытаетесь открыть URL-адрес для папки, в которой нет индексной страницы. Если параметры сервера не позволяют отображать содержимое папки, вы получите ошибку 403.
Существуют другие способы блокировки доступа и 403 могут быть отправлены. Например, вы можете блокировать по IP-адресу с помощью некоторых директив htaccess.
302 (or 307) Moved Temporarily & 301 Moved Permanently
Эти два кода используются для перенаправления браузера. Например, когда вы используете службу сокращения URL, такую как bit.ly, именно так они перенаправляют людей, которые идут по ссылке.
302 и 301 обрабатываются браузером очень похоже, но они могут иметь различные значения для spiders поисковых систем. Например, если ваш сайт не готов для обслуживания, вы можете перенаправить его в другое место с помощью 302. Поисковая система продолжит проверку вашей страницы в будущем. Но если вы перенаправите с использованием 301, это сообщит spider, что ваш сайт переехал в это место навсегда. За более точной информацией: http://www.nettuts.com перейдите на https://net.tutsplus.com/ используя 301 код вместо 302.
500 Internal Server Error
Этот код обычно отображается при сбое веб-скрипта. Большинство скриптов CGI не выводят ошибки непосредственно в браузер, в отличие от PHP. Если есть фатальные ошибки, они просто отправят код статуса 500. И тогда программист должен искать в журналах ошибок сервера, чтобы найти сообщения об ошибках.
Complete List
Вы можете найти полный список кодов состояния HTTP с их пояснениями here.
Заголовки HTTP в запросах HTTP
HTTP-запрос отправляется на определенные IP-адреса. Но так как большинство серверов способны размещать несколько сайтов под одним IP, они должны знать, какое доменное имя ищет браузер.
Это в основном имя host, включая домен и поддомен.
User-Agent
Этот заголовок может содержать несколько частей информации, таких как:
Именно так веб-сайты могут собирать определённую общую информацию о своих системах surfers. Например, они могут определить, использует ли surfer мобильный браузер и перенаправляет их на мобильную версию своего веб-сайта, который лучше работает с низким разрешением.
Accept-Language
Этот заголовок отображает настройки языка по умолчанию. Если сайт имеет разные языковые версии, он может перенаправить нового surfer на основе этих данных.
Accept-Encoding
Большинство современных браузеров поддерживают gzip и отправляют это в header. Затем веб-сервер может отправить выходной HTML-код в сжатом формате. Это позволяет уменьшить размер до 80% для экономии пропускной способности и времени.
If-Modified-Since
Если веб-документ уже сохранен в кеше в браузере и вы посещаете его снова, ваш браузер может проверить, был ли документ обновлён, отправив следующее:
Существует также HTTP-заголовок Etag, который можно использовать для проверки текущего кэша. Мы поговорим об этом в ближайшее время.
Cookie
Как следует из названия, это отправляет файлы cookie, хранящиеся в вашем браузере для этого домена.
Это пары name=value, разделённые точками с запятой. Cookies могут также содержать id сеанса.
Referer
Как следует из названия, этот HTTP header содержит ссылочный url.
Например, если я зашел на домашнюю страницу Nettuts + и нажал ссылку на статью, этот header будет отправлен в мой браузер:
Возможно, вы заметили, что слово «referrer» написано с ошибкой, как «referer». К сожалению, он превратился в официальную спецификацию HTTP подобным образом и застрял.
Authorization
Когда веб-страница запрашивает авторизацию, браузер открывает окно входа в систему. Когда вы вводите имя пользователя и пароль в этом окне, браузер отправляет другой HTTP-запрос, но на этот раз он содержит этот header
Данные внутри header имеют кодировку base64. Например, base64_decode (‘bXl1c2VyOm15cGFzcw ==’) возвратит ‘myuser: mypass’
Подробнее об этом будет, когда мы поговорим о заголовке WWW-Authenticate.
Заголовки HTTP в ответах HTTP
Теперь мы рассмотрим некоторые из наиболее распространенных HTTP headers, найденных в HTTP-ответах.
В PHP вы можете установить заголовки ответа, используя функцию header(). PHP уже отправляет определённые заголовки автоматически, для загрузки содержимого и настройки файлов cookie и прочее. Вы можете увидеть headers, которые отправляются или будут отправляться с помощью функции headers_list (). Вы можете проверить, были ли уже отправлены заголовки с помощью функции headers_sent().
Cache-Control
Определение из w3.org: «Поле заголовка Cache-Control используется для указания директив, которые ДОЛЖНЫ выполняться всеми механизмами кэширования по цепочке запросов/ответов». Эти «механизмы кэширования» включают шлюзы и прокси, которые может использовать ваш интернет-провайдер.
«public» означает, что ответ может быть кэширован кем угодно. «max-age» указывает, сколько секунд действителен кеш. Разрешение кэширования вашего сайта может снизить нагрузку на сервер и пропускную способность, а также увеличить время загрузки в браузере.
Кэширование также может быть предотвращено с помощью директивы «no-cache».
Подробности смотрите в w3.org.
Content-Type
Этот header указывает «mime-type» документа. Затем браузер определяет, как интерпретировать содержимое на основании этого. Например, страница html (или PHP-скрипт с выходом html) может возвращать это:
Для gif-изображения это может быть отправлено.
Браузер может использовать внешнее приложение или расширение браузера на основе mime-type. Например, это приведет к загрузке Adobe Reader:
При загрузке напрямую Apache обычно может обнаружить mime-тип документа и отправить соответствующий header. Кроме того, большинство браузеров имеют некоторую степень отказоустойчивости и автоопределение типов mime, если заголовки указаны неверно или отсутствуют.
Вы можете найти список общих типов mime here.
В PHP вы можете использовать функцию finfo_file() для определения mime-типа файла.
Content-Disposition
Этот header указывает браузеру открыть окно загрузки файла, вместо того, чтобы пытаться проанализировать содержимое. Пример:
Это заставит браузер сделать это:
Обратите внимание, что соответствующий заголовок Content-Type также должен быть отправлен вместе с этим:
Content-Length
Когда контент будет передаваться браузеру, сервер может указать его размер (в байтах), используя этот header.
Это особенно полезно при загрузке файлов. Именно так браузер может определить ход загрузки.
Например, вот сценарий-макет, который я написал, имитирует медленную загрузку.
Теперь я собираюсь закомментировать заголовок Content-Length
Теперь результат такой:
Браузер может только сказать, сколько байтов было загружено, но он не знает общую сумму. И индикатор выполнения не показывает прогресс.
Это еще один header, который используется для кеширования. Это выглядит так:
Веб-сервер может отправлять этот header с каждым документом, который он обслуживает. Значение может быть основано на последней изменённой дате, размере файла или даже контрольной сумме файла. Браузер затем сохраняет это значение, так как он кэширует документ. В следующий раз, когда браузер запрашивает тот же файл, он отправляет это в HTTP-запросе:
Если значение Etag документа совпадает с этим, сервер будет отправлять код 304 вместо 200, и никакого содержимого. Браузер будет загружать содержимое из своего кеша.
Last-Modified
Как следует из названия, этот header указывает дату последнего изменения документа в формате GMT:
Это предлагает браузеру другой способ для cache документа. Браузер может отправить это в HTTP-запросе:
Мы уже говорили об этом ранее в разделе «If-Modified-Since».
Location
Этот заголовок используется для перенаправления. Если код ответа 301 или 302, сервер также должен отправить этот header. Например, когда вы перейдете на страницу http://www.nettuts.com, ваш браузер получит следующее:
В PHP вы можете перенаправить surfer так:
По умолчанию, это отправит 302 код ответа. Если вы хотите вместо 301 отправить:
Set-Cookie
Когда веб-сайт хочет установить или обновить файл cookie в вашем браузере, он будет использовать этот header.
Каждый файл cookie отправляется как отдельный header. Обратите внимание, что файлы cookie, установленные с помощью JavaScript, не проходят через HTTP headers.
В PHP вы можете установить cookie-файлы, используя функцию setcookie(), а PHP отправляет соответствующие HTTP headers.
Что приводит к отправке этого заголовка:
Если дата истечения срока действия не указана, cookie удаляется, когда окно браузера закрыто.
WWW-Authenticate
Сайт может отправить этот header для аутентификации пользователя через HTTP. Когда браузер увидит этот header, он откроет диалоговое окно входа в систему.
Что будет выглядеть так:
В руководстве PHP есть section, в котором приведены образцы кода, как это сделать в PHP.
Content-Encoding
Этот header обычно устанавливается, когда возвращаемое содержимое сжимается.
В PHP, если вы используете функцию обратного вызова ob_gzhandler(), она будет автоматически установлена.
Заключение
Спасибо за прочтение. Надеюсь, эта статья послужит хорошей отправной точкой для изучения HTTP Headers. Пожалуйста, оставьте свои комментарии и вопросы ниже, и я постараюсь дать как можно больше ответов.