Сжатие информации
Сжатие информации
Сжатие информации, компрессия, Шаблон:Англ. data compression — алгоритмическое преобразование данных (кодирование), при котором за счет уменьшения их избыточности уменьшается их обьём.
Содержание
Принципы сжатия информации
В основе любого способа сжатия информации лежит модель источника информации, или, более конкретно, модель избыточности. Иными словами для сжатия информации используются некоторые сведения о том, какого рода информация сжимается — не обладая никакми сведениями об информации нельзя сделать ровным счётом никаких предположений, какое преобразование позволит уменьшить объём сообщения. Эта информация используется в процессе сжатия и разжатия. Модель избыточности может также строиться или параметризоваться на этапе сжатия. Методы, позволяющие на основе входных данных изменять модель избыточности информации, называются адаптивными. Неадаптивными являются обычно узкоспецифичные алгоритмы, применяемые для работы с хорошо определёнными и неизменными характеристиками. Подавляющая часть же достаточно универсальных алгоритмов являются в той или иной мере адаптивными.
Любой метод сжатия информации включает в себя два преобразования обратных друг другу:
Преобразование сжатия обеспечивает получение сжатого сообщения из исходного. Разжатие же обеспечивает получение исходного сообщения (или его приближения) из сжатого.
Все методы сжатия делятся на два основных класса
Кардинальное различие между ними в том, что сжатие без потерь обеспечивает возможность точного восстановления исходного сообщения. Сжатие с потерями же позволяет получить только некоторое приближение исходного сообщения, то есть отличающееся от исходного, но в пределах некоторых заранее определённых погрешностей. Эти погрешности должны определяться другой моделью — моделью приёмника, определяющей, какие данные и с какой точностью представленные важны для получателя, а какие допустимо выбросить.
Характеристики алгоритмов сжатия и применимость
Коэффициент сжатия
Коэффициент сжатия — основная характеристика алгоритма сжатия, выражающая основное прикладное качество. Она определяется как отношение размера несжатых данных к сжатым, то есть:
где k — коэффициент сжатия, So — размер несжатых данных, а Sc — размер сжатых. Таким образом, чем выше коэффициент сжатия, тем алгоритм лучше. Следует отметить:
Коэффициент сжатия может быть как постоянным коэффициентом (некоторые алгоритмы сжатия звука, изображения и т. п., например А-закон, μ-закон, ADPCM), так и переменным. Во втором случае он может быть определён либо для какого либо конкретного сообщения, либо оценён по некоторым критериям:
или каким либо другим. Коэффициент сжатия с потерями при этом сильно зависит от допустимой погрешности сжатия или его качества, которое обычно выступает как параметр алгоритма.
Допустимость потерь
Основным критерием различия между алгоритмами сжатия является описанное выше наличие или отсутствие потерь. В общем случае алгоритмы сжатия без потерь универсальны в том смысле, что их можно применять на данных любого типа, в то время как применение сжатия потерь должно быть обосновано. Некоторые виды данных не приемлят каких бы то ни было потерь:
Однако сжатие с потерями позволяет добиться гораздо больших коэффициентов сжатия за счёт отбрасывания незначащей информации, которая плохо сжимается. Так, например алгоритм сжатия звука без потерь FLAC, позволяет в большинстве случаев сжать звук в 1,5—2,5 раза, в то время как алгоритм с потерями Vorbis, в зависимости от установленного параметра качетсва может сжать до 15 раз с сохранением приемлемого качества звучания.
Системные требования алгоритмов
Различные алгоритмы могут требовать различного количества ресурсов вычислительной системы, на которых исполняются:
В целом, эти требования зависят от сложности и «интеллектуальности» алгоритма. По общей тенденции, чем лучше и универсальнее алгоритм, тем большие требования с машине он предъявляет. Однако в специфических случаях простые и компактные алгоритмы могут работать лучше. Системные требования определяют их потребительские качества: чем менее требователен алгоритм, тем на более простой, а следовательно, компактной, надёжной и дешёвой системе он может работать.
Так как алгоритмы сжатия и разжатия работают в паре, то имеет значение также соотношение системных требований к ним. Нередко можно усложнив один алгоритм можно значительно упростить другой. Таким образом мы можем иметь три варианта:
Алгоритм сжатия гораздо требовательнее к ресурсам, нежели алгоритм расжатия. Это наиболее распространённое соотношение, и оно применимо в основном в случаях, когда однократно сжатые данные будут использоваться многократно. В качетсве примера можно привести цифровые аудио и видеопроигрыватели. Алгоритмы сжатия и расжатия имеют примерно равные требования. Наиболее приемлемый вариант для линии связи, когда сжатие и расжатие происходит однократно на двух её концах. Например, это могут быть телефония. Алгоритм сжатия существенно менее требователен, чем алгоритм разжатия. Довольно экзотический случай. Может применяться в случаях, когда передатчиком является ультрапортативное устройство, где объём доступных ресурсов весьма критичен, например, космический аппарат или большая распределённая сеть датчиков, или это могут быть данные распаковка которых требуется в очень малом проценте случаев, например запись камер видеонаблюдения.
Сжатие данных

Сжатие данных (англ. data compression ) — алгоритмическое преобразование данных, производимое с целью уменьшения их объёма. Применяется для более рационального использования устройств хранения и передачи данных. Синонимы — упаковка данных, компрессия, сжимающее кодирование, кодирование источника. Обратная процедура называется восстановлением данных (распаковкой, декомпрессией).
Сжатие основано на устранении избыточности, содержащейся в исходных данных. Простейшим примером избыточности является повторение в тексте фрагментов (например, слов естественного или машинного языка). Подобная избыточность обычно устраняется заменой повторяющейся последовательности ссылкой на уже закодированный фрагмент с указанием его длины. Другой вид избыточности связан с тем, что некоторые значения в сжимаемых данных встречаются чаще других. Сокращение объёма данных достигается за счёт замены часто встречающихся данных короткими кодовыми словами, а редких — длинными (энтропийное кодирование). Сжатие данных, не обладающих свойством избыточности (например, случайный сигнал или белый шум, зашифрованные сообщения), принципиально невозможно без потерь.
Содержание
Принципы сжатия данных
В основе любого способа сжатия лежит модель источника данных, или, точнее, модель избыточности. Иными словами, для сжатия данных используются некоторые априорные сведения о том, какого рода данные сжимаются. Не обладая такими сведениями об источнике, невозможно сделать никаких предположений о преобразовании, которое позволило бы уменьшить объём сообщения. Модель избыточности может быть статической, неизменной для всего сжимаемого сообщения, либо строиться или параметризоваться на этапе сжатия (и восстановления). Методы, позволяющие на основе входных данных изменять модель избыточности информации, называются адаптивными. Неадаптивными являются обычно узкоспециализированные алгоритмы, применяемые для работы с данными, обладающими хорошо определёнными и неизменными характеристиками. Подавляющая часть достаточно универсальных алгоритмов являются в той или иной мере адаптивными.
Все методы сжатия данных делятся на два основных класса:
При использовании сжатия без потерь возможно полное восстановление исходных данных, сжатие с потерями позволяет восстановить данные с искажениями, обычно несущественными с точки зрения дальнейшего использования восстановленных данных. Сжатие без потерь обычно используется для передачи и хранения текстовых данных, компьютерных программ, реже — для сокращения объёма аудио- и видеоданных, цифровых фотографий и т. п., в случаях, когда искажения недопустимы или нежелательны. Сжатие с потерями, обладающее значительно большей, чем сжатие без потерь, эффективностью, обычно применяется для сокращения объёма аудио- и видеоданных и цифровых фотографий в тех случаях, когда такое сокращение является приоритетным, а полное соответствие исходных и восстановленных данных не требуется.
Характеристики алгоритмов сжатия и их применимость
Коэффициент сжатия
Коэффициент сжатия — основная характеристика алгоритма сжатия. Она определяется как отношение объёма исходных несжатых данных к объёму сжатых, то есть:  , где k — коэффициент сжатия, So — объём исходных данных, а Sc — объём сжатых. Таким образом, чем выше коэффициент сжатия, тем алгоритм эффективнее. Следует отметить:
, где k — коэффициент сжатия, So — объём исходных данных, а Sc — объём сжатых. Таким образом, чем выше коэффициент сжатия, тем алгоритм эффективнее. Следует отметить:
Коэффициент сжатия может быть как постоянным (некоторые алгоритмы сжатия звука, изображения и т. п., например А-закон, μ-закон, ADPCM, усечённое блочное кодирование), так и переменным. Во втором случае он может быть определён либо для каждого конкретного сообщения, либо оценён по некоторым критериям:
или каким-либо другим. Коэффициент сжатия с потерями при этом сильно зависит от допустимой погрешности сжатия или качества, которое обычно выступает как параметр алгоритма. В общем случае постоянный коэффициент сжатия способны обеспечить только методы сжатия данных с потерями.
Допустимость потерь
Основным критерием различия между алгоритмами сжатия является описанное выше наличие или отсутствие потерь. В общем случае алгоритмы сжатия без потерь универсальны в том смысле, что их применение безусловно возможно для данных любого типа, в то время как возможность применения сжатия с потерями должна быть обоснована. Для некоторых типов данных искажения не допустимы в принципе. В их числе
Системные требования алгоритмов
Различные алгоритмы могут требовать различного количества ресурсов вычислительной системы, на которых они реализованы:
В целом, эти требования зависят от сложности и «интеллектуальности» алгоритма. Общая тенденция такова: чем эффективнее и универсальнее алгоритм, тем большие требования к вычислительным ресурсам он предъявляет. Тем не менее, в специфических случаях простые и компактные алгоритмы могут работать не хуже сложных и универсальных. Системные требования определяют их потребительские качества: чем менее требователен алгоритм, тем на более простой, а следовательно, компактной, надёжной и дешёвой системе он может быть реализован.
Так как алгоритмы сжатия и восстановления работают в паре, имеет значение соотношение системных требований к ним. Нередко можно усложнив один алгоритм значительно упростить другой. Таким образом, возможны три варианта:
Алгоритм сжатия требует больших вычислительных ресурсов, нежели алгоритм восстановления. Это наиболее распространённое соотношение, характерное для случаев, когда однократно сжатые данные будут использоваться многократно. В качестве примера можно привести цифровые аудио- и видеопроигрыватели. Алгоритмы сжатия и восстановления требуют приблизительно равных вычислительных ресурсов. Наиболее приемлемый вариант для линий связи, когда сжатие и восстановление происходит однократно на двух её концах (например, в цифровой телефонии). Алгоритм сжатия существенно менее требователен, чем алгоритм восстановления. Такая ситуация характерна для случаев, когда процедура сжатия реализуется простым, часто портативным устройством, для которого объём доступных ресурсов весьма критичен, например, космический аппарат или большая распределённая сеть датчиков. Это могут быть также данные, распаковка которых требуется в очень малом проценте случаев, например запись камер видеонаблюдения.
Алгоритмы сжатия данных неизвестного формата
Имеется два основных подхода к сжатию данных неизвестного формата.
Алгоритмы сжатия данных
Цель лекции: изучить основные виды и алгоритмы сжатия данных и научиться решать задачи сжатия данных по методу Хаффмана и с помощью кодовых деревьев.
Сжатие данных – это процесс, обеспечивающий уменьшение объема данных путем сокращения их избыточности. Сжатие данных связано с компактным расположением порций данных стандартного размера. Сжатие данных можно разделить на два основных типа:
Введем ряд определений, которые будут использоваться далее в изложении материала.
Алфавит кода – множество всех символов входного потока. При сжатии англоязычных текстов обычно используют множество из 128 ASCII кодов. При сжатии изображений множество значений пиксела может содержать 2, 16, 256 или другое количество элементов.
Кодовое слово – это последовательность кодовых символов из алфавита кода. Если все слова имеют одинаковую длину (число символов), то такой код называется равномерным (фиксированной длины), а если же допускаются слова разной длины, то – неравномерным (переменной длины).
Код – полное множество слов.
Токен – единица данных, записываемая в сжатый поток некоторым алгоритмом сжатия. Токен состоит из нескольких полей фиксированной или переменной длины.
Фраза – фрагмент данных, помещаемый в словарь для дальнейшего использования в сжатии.
Кодирование – процесс сжатия данных.
Декодирование – обратный кодированию процесс, при котором осуществляется восстановление данных.
Отношение сжатия – одна из наиболее часто используемых величин для обозначения эффективности метода сжатия.
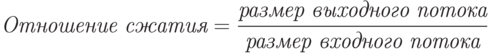
Коэффициент сжатия – величина, обратная отношению сжатия.
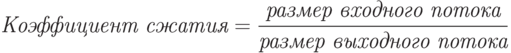
Средняя длина кодового слова – это величина, которая вычисляется как взвешенная вероятностями сумма длин всех кодовых слов.
где – вероятности кодовых слов;
Существуют два основных способа проведения сжатия.
Статистические методы – методы сжатия, присваивающие коды переменной длины символам входного потока, причем более короткие коды присваиваются символам или группам символам, имеющим большую вероятность появления во входном потоке. Лучшие статистические методы применяют кодирование Хаффмана.
Словарное сжатие – это методы сжатия, хранящие фрагменты данных в «словаре» (некоторая структура данных ). Если строка новых данных, поступающих на вход, идентична какому-либо фрагменту, уже находящемуся в словаре, в выходной поток помещается указатель на этот фрагмент. Лучшие словарные методы применяют метод Зива-Лемпела.
Рассмотрим несколько известных алгоритмов сжатия данных более подробно.
Метод Хаффмана
Этот алгоритм кодирования информации был предложен Д.А. Хаффманом в 1952 году. Хаффмановское кодирование (сжатие) – это широко используемый метод сжатия, присваивающий символам алфавита коды переменной длины, основываясь на вероятностях появления этих символов.
Префиксный код – это код, в котором никакое кодовое слово не является префиксом любого другого кодового слова. Эти коды имеют переменную длину.
Алгоритм Хаффмана можно разделить на два этапа.
Первоначально необходимо прочитать исходный текст полностью и подсчитать вероятности появления символов в нем (иногда подсчитывают, сколько раз встречается каждый символ). Если при этом учитываются все 256 символов, то не будет разницы в сжатии текстового или файла иного формата.
Пример 1. Программная реализация метода Хаффмана.
Сжатие информации без потерь. Часть первая
Доброго времени суток.
Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
| Сжатие с потерями |
| Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Третья группа методов – это так называемые методы преобразования блока. Входящие данные разбиваются на блоки, которые затем трансформируются целиком. При этом некоторые методы, особенно основанные на перестановке блоков, могут не приводить к существенному (или вообще какому-либо) уменьшению объема данных. Однако после подобной обработки, структура данных значительно улучшается, и последующее сжатие другими алгоритмами проходит более успешно и быстро.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon’s source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики
Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F = 
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.
Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.
Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 B1
a2 B2
…
an Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B’B». Тогда B’ называют началом, или префиксом слова B, а B» — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — < a1, a2, a3, a4>. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
Если сделать иллюстрацию этого процесса, получится примерно следующее:
Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).



