Нейронные сети, перцептрон
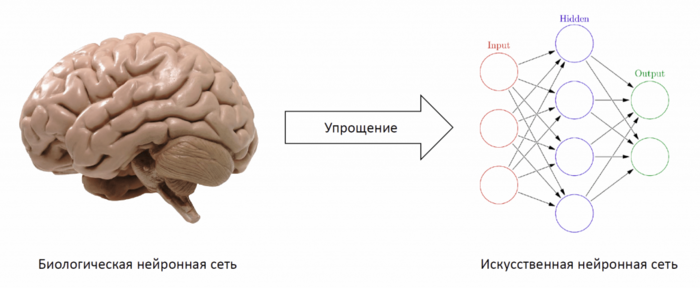
Искусственная нейронная сеть (ИНС) (англ. Artificial neural network (ANN)) — упрощенная модель биологической нейронной сети, представляющая собой совокупность искусственных нейронов, взаимодействующих между собой.
На данный момент нейронные сети используются в многочисленных областях машинного обучения и решают проблемы различной сложности.
Содержание
Структура нейронной сети [ править ]
Хорошим примером биологической нейронной сети является человеческий мозг. Наш мозг — сложнейшая биологическая нейронная сеть, которая принимает информацию от органов чувств и каким-то образом ее обрабатывает (узнавание лиц, возникновение ощущений и т.д.). Мозг же, в свою очередь, состоит из нейронов, взаимодействующих между собой.
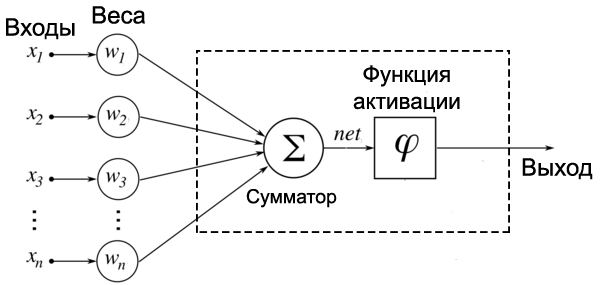
Для разных типов нейронов используют самые разные функции активации, но одними из самых популярных являются:
Виды нейронных сетей [ править ]
Разобравшись с тем, как устроен нейрон в нейронной сети, осталось понять, как их в этой сети располагать и соединять.
Как правило, в большинстве нейронных сетей есть так называемый входной слой, который выполняет только одну задачу — распределение входных сигналов остальным нейронам. Нейроны этого слоя не производят никаких вычислений. В остальном нейронные сети делятся на основные категории, представленные ниже.
Однослойные нейронные сети [ править ]
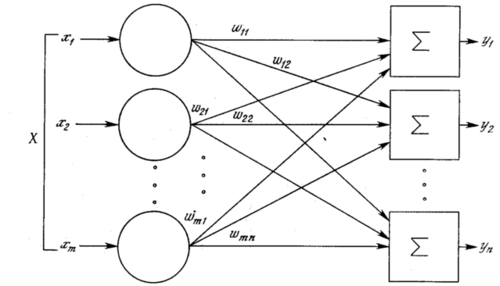
Однослойная нейронная сеть (англ. Single-layer neural network) — сеть, в которой сигналы от входного слоя сразу подаются на выходной слой, который и преобразует сигнал и сразу же выдает ответ.
Как видно из схемы однослойной нейронной сети, представленной справа, сигналы [math]x_1, x_2, \ldots x_n[/math] поступают на входной слой (который не считается за слой нейронной сети), а затем сигналы распределяются на выходной слой обычных нейронов. На каждом ребре от нейрона входного слоя к нейрону выходного слоя написано число — вес соответствующей связи.
Многослойные нейронные сети [ править ]
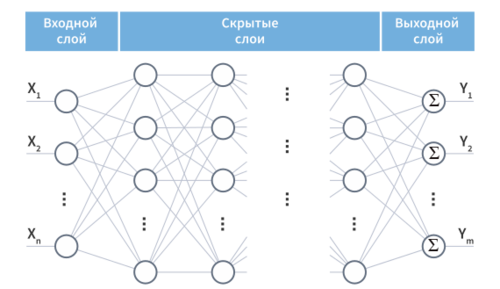
Многослойная нейронная сеть (англ. Multilayer neural network) — нейронная сеть, состоящая из входного, выходного и расположенного(ых) между ними одного (нескольких) скрытых слоев нейронов.
Помимо входного и выходного слоев эти нейронные сети содержат промежуточные, скрытые слои. Такие сети обладают гораздо большими возможностями, чем однослойные нейронные сети, однако методы обучения нейронов скрытого слоя были разработаны относительно недавно.
Работу скрытых слоев нейронов можно сравнить с работой большого завода. Продукт (выходной сигнал) на заводе собирается по стадиям на станках. После каждого станка получается какой-то промежуточный результат. Скрытые слои тоже преобразуют входные сигналы в некоторые промежуточные результаты.
Сети прямого распространения [ править ]
Сети прямого распространения (англ. Feedforward neural network) (feedforward сети) — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Все сети, описанные выше, являлись сетями прямого распространения, как следует из определения. Такие сети широко используются и вполне успешно решают определенный класс задач: прогнозирование, кластеризация и распознавание.
Однако сигнал в нейронных сетях может идти и в обратную сторону.
Сети с обратными связями [ править ]
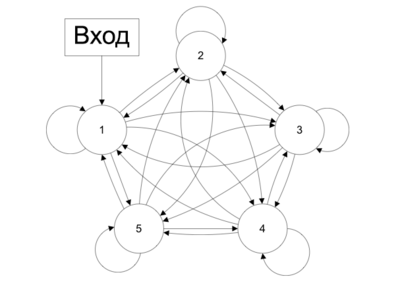
Сети с обратными связями (англ. Recurrent neural network) — искусственные нейронные сети, в которых выход нейрона может вновь подаваться на его вход. В более общем случае это означает возможность распространения сигнала от выходов к входам.
В сетях прямого распространения выход сети определяется входным сигналом и весовыми коэффициентами при искусственных нейронах. В сетях с обратными связями выходы нейронов могут возвращаться на входы. Это означает, что выход какого-нибудь нейрона определяется не только его весами и входным сигналом, но еще и предыдущими выходами (так как они снова вернулись на входы).
Обучение нейронной сети [ править ]
Обучение нейронной сети — поиск такого набора весовых коэффициентов, при котором входной сигнал после прохода по сети преобразуется в нужный нам выходной.
Это определение «обучения нейронной сети» соответствует и биологическим нейросетям. Наш мозг состоит из огромного количества связанных друг с другом нейросетей, каждая из которых в отдельности состоит из нейронов одного типа (с одинаковой функцией активации). Наш мозг обучается благодаря изменению синапсов — элементов, которые усиливают или ослабляют входной сигнал.
Если обучать сеть, используя только один входной сигнал, то сеть просто «запомнит правильный ответ», а как только мы подадим немного измененный сигнал, вместо правильного ответа получим бессмыслицу. Мы ждем от сети способности обобщать какие-то признаки и решать задачу на различных входных данных. Именно с этой целью и создаются обучающие выборки.
Обучающая выборка — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит обучение сети.
После обучения сети, то есть когда сеть выдает корректные результаты для всех входных сигналов из обучающей выборки, ее можно использовать на практике. Однако прежде чем сразу использовать нейронную сеть, обычно производят оценку качества ее работы на так называемой тестовой выборке.
Тестовая выборка — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит оценка качества работы сети.
Перцептрон [ править ]
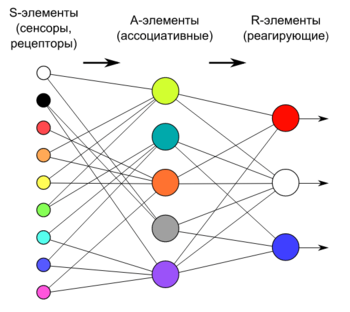
Перцептрон (англ. Perceptron) — простейший вид нейронных сетей. В основе лежит математическая модель восприятия информации мозгом, состоящая из сенсоров, ассоциативных и реагирующих элементов.
История [ править ]
Идею перцептрона предложил нейрофизиолог Фрэнк Розенблатт. Он предложил схему устройства, моделирующего процесс человеческого восприятия, и назвал его «перцептроном» (от латинского perceptio — восприятие). В 1960 году Розенблатт представил первый нейрокомпьютер — «Марк-1», который был способен распознавать некоторые буквы английского алфавита.
Таким образом перцептрон является одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером.
Описание [ править ]
В основе перцептрона лежит математическая модель восприятия информации мозгом. Разные исследователи по-разному его определяют. В самом общем своем виде (как его описывал Розенблатт) он представляет систему из элементов трех разных типов: сенсоров, ассоциативных элементов и реагирующих элементов.
Принцип работы перцептрона следующий:
Для элементов перцептрона используют следующие названия:
Классификация перцептронов [ править ]
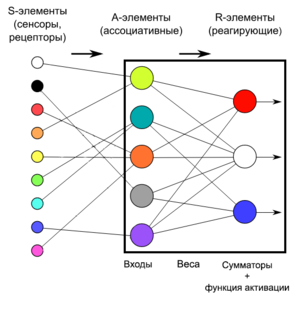
Перцептрон с одним скрытым слоем (элементарный перцептрон, англ. elementary perceptron) — перцептрон, у которого имеется только по одному слою S, A и R элементов.
Однослойный персептрон (англ. Single-layer perceptron) — перцептрон, каждый S-элемент которого однозначно соответствует одному А-элементу, S-A связи всегда имеют вес 1, а порог любого А-элемента равен 1. Часть однослойного персептрона соответствует модели искусственного нейрона.
Его ключевая особенность состоит в том, что каждый S-элемент однозначно соответствует одному A-элементу, все S-A связи имеют вес, равный +1, а порог A элементов равен 1. Часть однослойного перцептрона, не содержащая входы, соответствует искусственному нейрону, как показано на картинке. Таким образом, однослойный перцептрон — это искусственный нейрон, который на вход принимает только 0 и 1.
Однослойный персептрон также может быть и элементарным персептроном, у которого только по одному слою S,A,R-элементов.
Многослойный перцептрон по Розенблатту (англ. Rosenblatt multilayer perceptron) — перцептрон, который содержит более 1 слоя А-элементов.
Многослойный перцептрон по Румельхарту (англ. Rumelhart multilater perceptron) — частный случай многослойного персептрона по Розенблатту, с двумя особенностями:
Обучение перцептрона [ править ]
Иначе говоря, мы минимизируем суммарное отклонение наших ответов от правильных, но только в неправильную сторону; верный ответ ничего не вносит в функцию ошибки. Умножение на [math]y(x)[/math] здесь нужно для того, чтобы знак произведения всегда получался отрицательным: если правильный ответ −1, значит, перцептрон выдал положительное число (иначе бы ответ был верным), и наоборот. В результате у нас получилась кусочно-линейная функция, дифференцируемая почти везде, а этого вполне достаточно.
Алгоритм такой — мы последовательно проходим примеры [math]x_1, x_2, \ldots[/math] из обучающего множества, и для каждого [math]x_n[/math] :
Ошибка на примере [math]x_n[/math] при этом, очевидно, уменьшается, но, конечно, совершенно никто не гарантирует, что вместе с тем не увеличится ошибка от других примеров. Это правило обновления весов так и называется — правило обучения перцептрона, и это было основной математической идеей работы Розенблатта.
Применение [ править ]
Примеры кода [ править ]
Пример использования с помощью scikit-learn [4] [ править ]
Нейронные сети для начинающих. Часть 1

Привет всем читателям Habrahabr, в этой статье я хочу поделиться с Вами моим опытом в изучении нейронных сетей и, как следствие, их реализации, с помощью языка программирования Java, на платформе Android. Мое знакомство с нейронными сетями произошло, когда вышло приложение Prisma. Оно обрабатывает любую фотографию, с помощью нейронных сетей, и воспроизводит ее с нуля, используя выбранный стиль. Заинтересовавшись этим, я бросился искать статьи и «туториалы», в первую очередь, на Хабре. И к моему великому удивлению, я не нашел ни одну статью, которая четко и поэтапно расписывала алгоритм работы нейронных сетей. Информация была разрознена и в ней отсутствовали ключевые моменты. Также, большинство авторов бросается показывать код на том или ином языке программирования, не прибегая к детальным объяснениям.
Поэтому сейчас, когда я достаточно хорошо освоил нейронные сети и нашел огромное количество информации с разных иностранных порталов, я хотел бы поделиться этим с людьми в серии публикаций, где я соберу всю информацию, которая потребуется вам, если вы только начинаете знакомство с нейронными сетями. В этой статье, я не буду делать сильный акцент на Java и буду объяснять все на примерах, чтобы вы сами смогли перенести это на любой, нужный вам язык программирования. В последующих статьях, я расскажу о своем приложении, написанном под андроид, которое предсказывает движение акций или валюты. Иными словами, всех желающих окунуться в мир нейронных сетей и жаждущих простого и доступного изложения информации или просто тех, кто что-то не понял и хочет подтянуть, добро пожаловать под кат.
Первым и самым важным моим открытием был плейлист американского программиста Джеффа Хитона, в котором он подробно и наглядно разбирает принципы работы нейронных сетей и их классификации. После просмотра этого плейлиста, я решил создать свою нейронную сеть, начав с самого простого примера. Вам наверняка известно, что когда ты только начинаешь учить новый язык, первой твоей программой будет Hello World. Это своего рода традиция. В мире машинного обучения тоже есть свой Hello world и это нейросеть решающая проблему исключающего или(XOR). Таблица исключающего или выглядит следующим образом:
| a | b | c |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число — ответ. Теперь о самих нейронных сетях.
Что такое нейронная сеть?
Нейронная сеть — это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1, Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей — это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация — распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание — возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание — в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?

Нейрон — это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.
Важно помнить, что нейроны оперируют числами в диапазоне [0,1] или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ — это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?
Синапс это связь между двумя нейронами. У синапсов есть 1 параметр — вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример — смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов — это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить, что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?
В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H — скрытый нейрон, а буквой w — веса. Из формулы видно, что входная информация — это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации — это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия — это диапазон значений.
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Это самая распространенная функция активации, ее диапазон значений [0,1]. Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет — это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.
Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка — это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.
Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Задача
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE.
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
Результат — 0.33, ошибка — 45%.
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Всё, что нужно знать о нейронных сетях
Говорим о нейронных сетях: легкая подача сложной информации так, что поймет даже ребенок. Изучаем базис и углубляемся в тему с нуля.
 Источник изображения
Источник изображения
Машинное обучение, data science, нейронные сети – эти сферы не только крайне интересные, но и довольно сложные. Остановимся на нейронных сетях: объясним, что это такое, и расскажем об основных понятиях. Нет времени читать и готовы сразу перейти к практике? Обратите внимание на курс Deep Learning и нейронные сети.
Нейрон – базовая единица нейронной сети. У каждого нейрона есть определённое количество входов, куда поступают сигналы, которые суммируются с учётом значимости (веса) каждого входа. Далее сигналы поступают на входы других нейронов. Вес каждого такого «узла» может быть как положительным, так и отрицательным. Например, если у нейрона есть четыре входа, то у него есть и четыре весовых значения, которые можно регулировать независимо друг от друга.
Искусственная нейронная сеть имитирует работу естественной нейронной сети – человеческого мозга – и используется для создания машин с искусственным интеллектом. Как правило, для обучения ИИ нужен «учитель» – набор информации с определёнными параметрами, значениями и показателями.
Соединения связывают нейроны между собой. Значение веса напрямую связано с соединением, а цель обучения – обновить вес каждого соединения, чтобы в дальнейшем не допускать ошибок.
 Источник изображения
Источник изображения
Смещение – это дополнительный вход для нейрона, который всегда равен 1 и, следовательно, имеет собственный вес соединения. Это гарантирует, что даже когда все входы будут равны нулю, нейрон будет активен.
Функция активации используется для того, чтобы ввести нелинейность в нейронную сеть. Она определяет выходное значение нейрона, которое будет зависеть от суммарного значения входов и порогового значения.
Также эта функция определяет, какие нейроны нужно активировать, и, следовательно, какая информация будет передана следующему слою. Благодаря функции активации глубокие сети могут обучаться.
Входной слой – это первый слой в нейронной сети, который принимает входящие сигналы и передает их на последующие уровни.
Скрытый (вычислительный) слой применяет различные преобразования ко входным данным. Все нейроны в скрытом слое связаны с каждым нейроном в следующем слое.
Выходной слой – последний слой в сети, который получает данные от последнего скрытого слоя. С его помощью мы сможем получить нужное количество значений в желаемом диапазоне.
Вес представляет силу связи между нейронами. Например, если вес соединения узлов 1 и 3 больше, чем узлов 2 и 3, это значит, что нейрон 1 оказывает на нейрон 3 большее влияние. Нулевой вес означает, что изменения входа не повлияют на выход. Отрицательный вес показывает, что увеличение входа уменьшит выход. Вес определяет влияние ввода на вывод.
Прямое распространение – это процесс передачи входных значений в нейронную сеть и получения выходных данных, которые называются прогнозируемым значением. Когда входные значения передаются в первый слой нейронной сети, процесс проходит без каких-либо операций. Второй уровень сети принимает значения первого уровня, а после операций по умножению и активации передает значения далее. Тот же процесс происходит на более глубоких слоях.
Обратное распространение ошибки. После прямого распространения мы получаем значение, которое называется прогнозируемым. Чтобы вычислить ошибку, мы сравниваем прогнозируемое значение с фактическим с помощью функции потери. Затем мы можем вычислить производную от значения ошибки по каждому весу в нейронной сети.
В методе обратного распространения ошибки используются правила дифференциального исчисления. Градиенты (производные значений ошибок) вычисляются по значениям веса последнего слоя нейронной сети (сигналы ошибки распространяются в направлении, обратном прямому распространению сигналов) и используются для вычисления градиентов слоев.
Этот процесс повторяется до тех пор, пока не будут вычислены градиенты каждого веса в нейронной сети. Затем значение градиента вычитают из значения веса, чтобы уменьшить значение ошибки. Ээто позволяет добиться минимальных потерь.
Скорость обучения – это характеристика, которая используется во время обучения нейронных сетей. Она определяет, как быстро будет обновлено значение веса в процессе обратного распространения. Скорость обучения должна быть высокой, но не слишком, иначе алгоритм будет расходиться. При слишком маленькой скорости обучения алгоритм будет сходиться очень долго и застревать в локальных минимумах.
 Источник изображения
Источник изображения
Конвергенция – это явление, когда в процессе итерации выходной сигнал становится все ближе к определенному значению. Чтобы не возникло переобучения (проблем работы с новыми данными из-за высокой скорости), используют регуляризацию – понижение сложности модели с сохранением параметров. При этом учитываются потеря и вектор веса (вектор изученных параметров в данном алгоритме).
Нормализация данных – процесс изменения масштаба одного или нескольких параметров в диапазоне от 0 до 1. Этот метод стоит использовать в том случае, если вы не знаете, как распределены ваши данные. Также с его помощью можно ускорить обучение.
Стоит упомянуть и о таком термине, как полностью связанные слои. Это значит, что активность всех узлов в одном слое переходит на каждый узел в следующем. В таком случае слои будут полностью связанными.
С помощью функции потери вы можете вычислить ошибку в конкретной части обучения. Это среднее значение функции для обучения:
Для обновления весов в модели используются оптимизаторы:
Для измерения производительности нейронной сети используются метрики производительности. Точность, потеря, точность проверки, оценка — это лишь некоторые показатели.
Batch size – количество обучающих примеров за одну итерацию. Чем больше batch size, тем больше места будет необходимо.
Количество эпох показывает, сколько раз модель подвергается воздействию обучения. Эпоха – один проход вперёд или назад для всех примеров обучения.
Так что же такое искусственная нейронная сеть? Это система нейронов, которые взаимодействуют между собой. Каждый нейрон принимает сигналы или же отправляет их другим процессорам (нейронам). Объединённые в одну большую сеть, нейроны, обучаясь, могут выполнять сложные задачи.
Углубиться в сферу искусственного интеллекта и наработать практические навыки по программированию глубоких нейронных сетей вы можете на специализированном курсе Deep Learning и нейронные сети, где познакомитесь с основными библиотеками для Deep Learning, такими как TensorFlow, Keras и другими.



