Случалось ли вам при воспроизведении какого-то музыкального трека или видеоролика видеть на экране программного плеера название композиции, альбома или имя исполнителя? Конечно же, да. Так вот! Для отображения такой информации используются метаданные. Это описание является как бы сопутствующим и включено в основную архитектуру воспроизводимого файла. Но на самом деле понятие метаданных намного шире, нежели в приведенном примере. Далее рассмотрим, как любая информационная система может использовать такие данные и что это такое в принципе. В качестве примеров для лучшего понимания будут приведены технологии мультимедиа и программы управления предприятиями на основе 1С.
Если исходить из того, что предлагает в качестве основной трактовки этого понятия такой уважаемый ресурс, как Wikipedia, объяснить этот термин можно достаточно просто. По сути своей метаданные – это в некоторым смысле информация о другой информации.
Иными словами, в понятие метаданных вкладывается дополнительное описание какого-то объекта или процесса. Объект метаданных, например, в программе 1С может иметь разные формы и классифицироваться по какому-то признаку взаимодействия системы с пользователем (чаще всего визуальному). В некотором смысле такие объекты распределяются в программном пакете по видам и ролям (письма, отчеты, сообщения, вызываемые процедуры и т. д.). Но это лишь частный случай. На самом деле понятие метаданных несколько шире.
Разновидности и типы метаданных
Для того чтобы в полной мере понять смысл, вкладываемый в этот термин, необходимо знать применяемую классификацию. Их несколько.
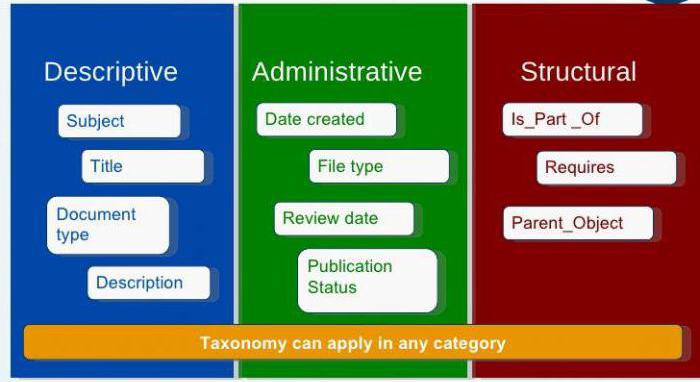
Во-первых, метаданные можно классифицировать по следующим признакам:
Во-вторых, любая информационная система предполагает еще и классификацию по другим признакам, среди которых можно выделить три большие группы метаданных:
Различие и сходство между данными и метаданными
В понимании такой информационной структуры весьма интересным является и тот факт, что обычные данные и метаданные могут меняться ролями.
В качестве самого простого примера можно взять заголовок статьи. Если рассматривать его как часть всего текста, он относится к данным. Но если рассматривать его применительно ко всему текстовому файлу, это метаданные.
Точно так же можно взять в качестве примера обычное стихотворение. Само по себе оно изначально является данными. Но если написать на него музыку, то есть прикрепить текст к сопровождению, стихотворение уже начинает выступать в роли метаданных.

Форматы метаданных
Собственно, формат метаданных представляет собой некую унифицированную форму описания свойств какого-то объекта, на основании которого о нем можно получить полное представление. Как правило, такие формы включают в себя несколько полей для ввода атрибутов, описания свойств объекта, их сути и т. д.

Самыми распространенными являются следующие:
Список можно продолжать до бесконечности, поскольку для любого аспекта человеческой деятельности сегодня можно найти какой-то единый подход в описании.
Что касается прикладного программирования, метаданные можно позиционировать как инструмент инкапсуляции или определения логики работы с таблицами, входящими в состав единой СУБД (например, 1С). Их применение позволяет произвести изоляцию работу с одной отдельно взятой таблицей от всех данных, содержащихся в основной базе.
Простейшие примеры использования метаданных
Приведенные выше примеры дают несколько отвлеченное понятие метаданных. Точное понимание можно получить, если привести в пример ID3-теги, которые в большинстве своем присутствуют в MP3-файлах, соответствующих официальным трекам каких-то исполнителей.
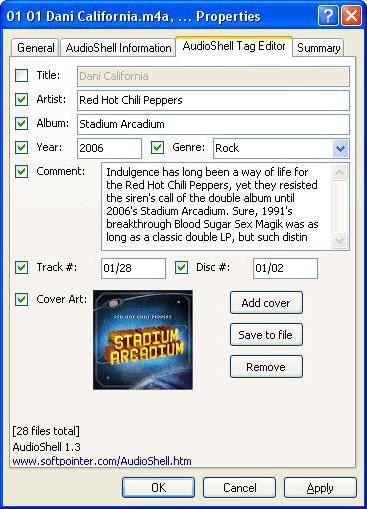
Эта информация как раз и содержит данные о композиции, альбоме, самом исполнителе, годе выпуска и т. д. Собственно, загрузка метаданных в любом программном плеере или аудиоредакторе сложностей не представляет. Но в плеерах информацию нужно сохранить или обновить, а вот в редакторах вроде Adobe Audition (бывшее приложение Cool Edit Pro) такие сведения после ввода прикрепляются к треку автоматически, и повторное сохранение не требуется.
В некотором смысле к метаданным можно отнести и файлы формата XML, в которых сохраняется либо информация с тегами, либо настройки программ, к которым они прикреплены.
Ошибки чтения
Как раз с XML-данными зачастую могут возникать проблемы, когда появляется ошибка метаданных. О чем это говорит? Да только о том, что теги, если они вводились вручную, были прописаны некорректно.
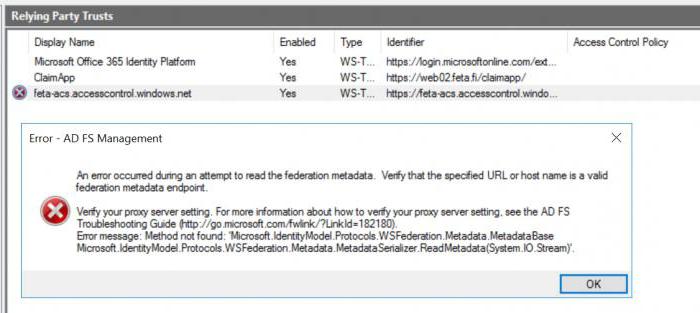
Но сбой может быть связан еще и с повреждением самого описательного файла. Как правило, редактирование, причем даже файлов запроса лицензий и ключей в таком формате, можно произвести в обычном «Блокноте», если знать, что именно удалять или изменять.
В той же системе 1С, как правило, ошибка подгрузки метаданных связана с повреждением базы данных, а точнее – с их загрузкой со съемных носителей, когда пользователи пытаются перезаписать существующий MD-файл собственными силами. Иногда причиной такой ситуации может стать внезапное отключение электроэнергии. В принципе, для восстановления можно использовать распаковщшик GComp, при помощи которого сначала нужно извлечь данные, а потом упаковать их снова. Можно проверить содержимое файла в HEX-редакторе и, если оно не соответствует оригиналу, просто заменить файл, скопировав его из аналогичной версии 1С.
Вместо итога
Вот, собственно, и все, что мы хотели вам поведать о метаданных. Как видите, суть самого понятия сводится к простому информационному описанию другой информации, объектов, их свойств, сути и т. д. И с такой информацией человек сталкивается чуть ли не ежедневно, даже не придавая этому значения. А стоило бы…
Мета-данные. На пути к идеалам управления моделями данных
О чём этот пост
Определения и ограничения
Предполагается, что читатель является (или когда-нибудь станет) разработчиком Enterprise Application, которому часто нужно писать быстро и качественно, но не боящегося лезть в дебри JPA/JTA/RMI чтобы «подкрутить напильником» особо тонкие места.
Данные — то, что хранится в базе данных приложения. Данные о клиентах, пользователях, заказах и т.п.
Метаданные — описание структуры данных. Описание того, какие типы объектов хранятся в базе данных, какие у них есть поля (аттрибуты, элементы), описание зависимостей между объектами. В общем случает типы могут наследовать атрибуты родительского типа, а один атрибут в общем случае может присутствовать у двух и более типов, несвязанных отношением наследования.
Enterprise Application работает с использованием (чаще всего) Application Server’а (WebLogic, JBOSS) и некоторой РСУБД (Oracle, Informix, MySQL). Хотя автор не видит ничего зазорного в самостоятельной сборке AS на основе Tomcat/Hibernate/JOTM/DBCP/etc, это очень и очень интересно, но за рамками данного топика.
В качестве РСУБД предполагается одна из тех стандартных, которая поддерживается Hibernate/OpenJPA.
В топике используются термины из XML Schema: пространство имён, тип, атрибут. Последним двум в некоторой степени соответствуют понятия Java класс (объект класса, бин) и свойство (property, aka get+set, также иногда просто поле, field).
Введение. Простейший случай
Большие приложения — чаще всего это не только приложения с большим объёмом данных. Чаще всего это приложения работающие с большим количеством разнородных данных, имеющих разную структуру с точки зрения бизнес-логики. (Кстати, последнее важно — структура данных может быть различной на уровне СУБД, на уровне приложения и даже внутри него)
Заметьте в последнем предложении важное уточнение — «бизнес-логики». Речь идёт об описании процессов взаимодействия структур данных, их изменении и пр. — то есть кода, который должен знать и знает о структуре данных. Но если, например, мы говорим про редактирование бинов через WEB-интерфейс (или любым другим способом), то для написания редактора, который может редактировать 80% объектов, не зная заранее их структуры (т.н. generalized), нам придётся разбираться с Reflection/Beans/etc и другими, в принципе, не очень страшными словами. (Страшные — в конце топика).
Современные средства проектирования позволяют автоматизировать часть процессов связанных с обновлением, например, структуры базы данных по коду, либо наоборот — сгенерировать или обновить код по описанию структуры данных. Не уверен, но, думаю, существуют средства создания одновременно и кода, и структуры базы данных на основе некой абстрактной схемы данных, записанной, например, в виде XML Schema. (Код так точно можно сгенерировать — см. XML Beans и пр.). Однако все эти средства работают в «offline» и не затрагивают работающее приложение (если вы, конечно, не сделаете обновление прямо по «живому», но ничего хорошего из этого не бывает).
Кстати, некоторые из вспомогательных утилит можно заставить и формочки для каждого типа объектов нарисовать.
Гибкие структуры данных
Самой гибкой можно считать структуру, в которой каждый объект хранится как запись в базе данных в виде, ну, например, XML. То есть большая-большая таблица, в которой две колонки — ID объекта и его содержание в виде XML. Как вы правильно догадываетесь, основной недостаток подобной структуры — очень низкая производительность базы данных в тот момент, когда нам нужно будет вычислить, ну например, всех клиентов из города «Москва». Для этого придётся базе данных распарсить каждое значение.
Чтобы структура осталось гибкой, но поменьше нагружать базу данных, объект разбивают на кусочки и выносят в отдельные таблицы. Например,
— Объекты: ID, обязательное поле 1, обязательное поле 2
— Значения: ID объекта, идентификатор аттрибута, значение
Можно пойти дальше и, без ограничения гибкости, разделить атрибуты разных типов по разным таблицам или колонкам. Подобная схема успешно применяется в приложении (вырезано) для обработки данных в несколько терабайт.
Ещё недостатки:
За гибкость нужно платить. Во-первых, слой работы с данными придётся писать самостоятельно. Во-вторых, возникает большое желание сэкономить и оставить для бизнес-логики API, который бы отражал структуру базы данных:
— дай объект ID такой-то
— дай аттрибут ID такой-то
— обнови значение
— запиши аттрибут ID такой-то объекта такой-то
— обнови версию объекта (+1)
Конечно, с точки зрения программиста generalized редактора данных очень удобно иметь методы вроде getAllAttributes(). Однако с точки зрения бизнес-логики это неудобно, особенно если нужно помнить все ID нужных атрибутов (они могут быть и числовыми).
Нужно отметить, однако, что API в общем случае не обязан совпадать со структурой базы данных. Главное — чтобы 80% действий выполнялись самым простым и очевидным способом. То есть если у нас в базе хранятся клиенты, получение имени клиента или его адреса должна быть одна строка кода вроде client.getAddress(). Однако для гибких структур написание таких оболочек может сильно подорвать производительность, во-вторых, структуры имеют обыкновение меняться…
Однако если такие оболочки не пишет тот, кто отвечает за написание процедур доступа к данным, будьте готовы, что через пару лет у вас будет столько оболочек «упрощённого» доступа к данным, сколько инициативных программистов работают со «стандартным» API.
Структуры с ограниченными возможностями
В этом разделе хочется рассказать ещё об одном подходе, которая используется в одной малоизвестной CMS.
С точки зрения кода доступ к атрибутам объекта осуществляется таким же образом, как и у гибких структур — через методы вроде getAttribute / getAllAttributes / etc. Однако для CMS, основная задача которой редактировать объекты по отдельности (без relations между объектами), а также просто вывести объект в XML для дальнейшей обработки — данного API вполне хватает.
Интересно то, что список типов данных хранится в некотором конфигурационном файле. Также в этом файле для каждого типа хранится список аттрибутов и их тип. На основании конфигурационного файла при запуске создаётся или обновляется структура таблиц. В дальнейшем «на лету» при изменении структуры данных таблицы обновляются.
Плюсы:
— очевидная модель данных для СУБД
— гибкость «на лету»
Минусы
— с точки бизнес-логики API слишком гибкий (см. предыдущий раздел)
— нужно писать свою систему доступа к данным, которая в настоящий момент, к сожалению, в отличии от системных объектов (пользователи, группы, etc) игнорирует транзакции, кеши и прочие прелести
Классификация… попытка
Хочу… идеальная для автора
Из предыдущего пункта легко выводятся требования к идеальной (с точки зрения автора) системе описания и оперирования моделями данных:
— описание структуры данных должно быть в базе данных, что позволит оперативно изменять описание модели, возможно — через само приложение
— сами данные при этом должны хранится в нормализованной (вплоть до 3-4 формы) базе данных, где каждому типу соответствует своя таблица данных. Система управления должна сама заботится о поддержании схемы базы данных в соответствии с мета-данными.
— доступ к данным должен осуществляться через стандартные интерфейсы JPA / EntityManager.
— с точки зрения бизнес-логики основные поля основных объектых типов должны быть доступны через простой API без дополнительного resolving / casting / narrowing (т.е. сразу после загрузки из EntityManager)
— но система должна также обеспечивать доступ к мета-данным. В том числе для конкретного объекта — получения списка всех полей.
В настоящее время автор занимается написанием подобной системы, используя:
— Hibernate — как драйвер доступа к данным
— CGLIB / ASM — для динамического конструирования классов на основе их описания, включая аннотации для Hibernate
— XML Schema — для описания типов данных и их атрибутов
Содержание, метаданные и контекст открытых данных
Результат публикации данных в свободном и бесплатном доступе напрямую зависит от их состава и качества. Чем более полными и корректными окажутся публичные данные, тем выше будет эффективность их использования и тем больше пользователей предпочтет поработать с ними. 
В отношении любых передаваемых данных, особенно публичных, необходимо всегда оценивать три их ключевых аспекта: состав (содержание), описание (метаданные) и окружение (контекст).
Настоящая публикация продолжает тему открытых, разделяемых и делегируемых данных и относится ко всем этим трем указанным категориям.
Организация данных
Первый важный аспект публичных данных связан с их содержимым и с их внутренней организацией.
Смысл
Всякие хорошие данные обладают некоторым полезным смыслом. Бессмысленная информацию в любом виде непригодна для последующей обработки и анализа в любом виде деятельности с помощью любых инструментов.
Цифровые данные, о которых идет речь в данной публикации, являясь первичными или даже вторичными, в той или иной мере отображают результат определенного сбора информации. Осуществляемый сбор информации позволяет записывать некоторые качественные и количественные значения свойств объектов, процессов, явлений, событий и т.п. Структурно-организованные регистрируемые сведения сохраняются как цифровые данные на соответствующих носителях. Очевидно, что таким образом полученные данные прямо (первичные) или косвенно (вторичные) определяют некий предметный смысл.
Учитывая тот факт, что на данные прямое и неотделимое влияние оказывает человеческий фактор, всегда можно говорить о том, что они описывают не объективную реальность, а некоторое понимание человеком той объективной реальности, о которой он целевым образом собирает сведения. Иными словами, данные всегда содержат некую долю субъективности в своем содержимом или в структуре и описывают воспринимаемую модель из заданной предметной области.
Именно тот факт, что данные в той или иной степени описывают некоторый смысл целевой модели, возможен последующий их анализ и выявление важных атрибутов такой модели.
Смысл, который содержат данные определяет необходимость и важность их публикации. Например, особый социальный и экономический смысл имеют государственные статистические данные – отсюда, очевидная задача их издания как в виде цифровых датасетов, так и в виде специальных переработанных сборников. Если данные не несут какой-то важный смысл для пользователей или вообще представляют собой бессмысленную регистрацию потока явлений и событий, то они не будут востребованы. Это утверждение наводит на определенную мысль о том, что публиковать стоит цифровые наборы с хорошо формализованным смыслом.
На то, какой смысл имеют данные влияет их уровень передела.
Наиболее ценными с этой точки зрения и обладающие неискаженным смыслом являются собранные первичные данные. Чем больше обработок было произведено с данными, тем больше смысл искажается и видоизменяется. Отсюда необходимость явно указывать количество и качество переделов данных.
Смысл содержащийся в данных накладывает свой отпечаток на их структуру.
Структура
В данных всегда можно выделить некие неделимые минимальные целостные единицы.
Причем такие неделимые целостные единицы всегда обладают смыслом большим, чем прямым. Например, символ (в простейшем виде) не несет никакое дополнительное значение, кроме того, что он представляет собой некую букву алфавита, цифру или специальное обозначение в тексте. С другой стороны, слово, кроме того, что представляет некий набор тех же символов, имеет смысловое понятийное значение и определяет некий объект (существительное), атрибут (прилагательное), действие (глагол) и т.д. Поэтому деление слова на символы – деление минимальной целостной единицы – приводит к потере его понятийного значения.
Выбор минимальной целостной и неделимой единицы является субъективным понятием в рамках заданной тематики и целей пользователя.
Например, для каких-то целей, может быть установлено, что неделимой единицей признается не отдельное слово, а целое предложение. В то же время даже некоторые форматы могут задавать особенности построения минимальных единиц данных. Например, в рамках электронных таблиц достаточно просто и удобно принимать за минимальную единицу данных содержимое отдельной ячейки. Однако во многом, выбор целостной единицы данных обусловлен совокупностью критериев предметной области данных и способом их записи.
После того, как задано понятие минимальной неделимой единицы данных, возникает и понятие структуры всей совокупности целевых данных. Так для электронной таблицы, единицы данных формируют наборы данных в виде строк или столбцов, а в последующем группируются в таблицы (листы) и наборы таблиц (книги).
Удобно выделять два уровня группировки целостных единиц данных:
Структуру данных необходимо иметь для возможности производить какую-либо осмысленную их обработку.
Операции с данными производятся непосредственно с неделимыми целостными единицами или с их группами. Причем даже есть возможность обрабатывать неделимые целостные единицы тем или иным образом создавая из них новые. Например, это позволяет делать функционал электронных таблицы: обрабатывать содержимое отдельной ячейки и разделять её на некие составные элементы, но при этом основной акцент в подобном приложении всё-таки сделан на обработке ячеек как на простейших обрабатываемых элементарных единицах.
Второй ключевой особенностью выделения в цифровых данных отдельных целостных единиц и последующей их группировки – это возможность идентификации.
Назначение уникального абсолютного или относительного имени как для неделимой части данных, так и для упорядоченного набора данных значительно расширяет функционал обработки. Адресация, реферирование, рекурсия, классификация и множество дополнительных простых или сложнейших операций применимы к именованным или идентифицированным элементам данных с последующим возвратам к первоисточнику (история ссылок).
Ещё одна полезная и важная особенность структуры данных, как производная от идентификации заключается в связывании отдельных элементов данных по тем или иным критериям или задачам. Связывание фактически приводит к появлению такого функционала как вторичное структурирование, нелинейное упорядочивание, гиперссылки, альтернативные пути обхода и т.п. Если сопроводить связь некоторыми дополнительными атрибутами, то можно выделить даже особый класс объектов-описателей и выстроить сложные зависимые структуры доселе невообразимых форм и сочетаний. Именно за счет связывания появляется некая динамика в данных.
Структурирование данных привносит значительный вклад в возможности их не только цифровой обработки, но и смысловой аналитики.
Моделирование правильных и эффективных структур цифровых данных достаточно сложная и ответственная компетенция которая может давать хороший результат только при совмещении знаний информационных технологий и предметной области. Удачно заданная структура позволяет удобно и результативно работать с данными как человеку, так и машине. Иными словами, правильный выбор структуры позволяет быстро распознавать упорядоченные данные непосредственно человеком или созданными алгоритмами.
Структура данных, как уже упоминалось, может зависеть от формата записи и хранения данных, но это ещё не сам формат. А значит она может трансформироваться. И значит в рамках одного и того же формата могут задаваться разные структуры. В подавляющих случаях на практике, для значительного упрощения и для большей эффективности, структура тесно взаимосвязана с форматом.
Формат
В контексте данной публикации «формат» – это способ сохранения данных в физической обособленной единице (файл, запись, таблица, поток) на заданном носителе.
Формат определяет возможности прочитать и принять данные в обработку как человеком, так и алгоритмом. Если структура задает содержательную организацию данных, то формат представляет собой техническую сторону их записи и хранения.
С учетом того, что цифровые данные неотъемлемы от машинных носителей, формат реализуется на трех машино-зависимых слоях, выбором соответствующего способа форматирования на каждом из слоев:
Кодировка символов – это достаточно понятная и урегулирования часть, которая в целом пришла к относительной теоретической и практической стабильности. Тем не менее даже в этом вопросе практика применения оставляет желать лучшего. Что уж говорить о нотации и схеме данных, особенно в применении к публичным данным. Множество факторов и противоречивых интересов, замешанных на свободных стандартах и платных мощных инструментах.
Ключевой фактор выбора нотации данных, как одного из уровней форматирования, состоит непосредственно в структуре данных.
Например, если структурирование данных сведено к таблице, то очевидно, что удобно будет её отформатировать, скорее, как CSV, чем как HTML. С другой стороны, задача может быть поставлена так, что выбор будет сделан в пользу XML. Кажется, совсем уж экзотическим, но вполне возможно нотировать таблицу данных и как последовательность команд INSERT (SQL) для каждой из строк.
Для публичных данных наиболее предпочтительным являются простые, свободные и распространенные форматы. Приоритетной, например, для открытых государственных данных выглядит связка: [Unicode + CSV|XML + custom_scheme]. Причем custom-схема данных часто описывается в «паспорте открытых данных».
Конечно же можно и нужно развивать форматы передаваемых и публикуемых данных. Но в большей степени новинки из этой области будут восприняты на частном уровне или при защищенном трансфере данных. Для публичных данных пока останутся более понятными и актуальными те форматы, которые получили массовое распространение и для работы, с которыми существует множество как платных, так и бесплатных инструментов, которыми привыкли пользоваться аналитики.
Вопрос повторного использования данных может быть неверно отнесен к особенностям их форматирования, но это скорее вопрос правильного их структурирования. Именно на уровне структуры цифровых данных появляется возможность связывания и организации ссылок. Формат лишь только определяет фактические правила записи и разрешения ссылок. В том числе формат может задавать или поддерживать «межформатные» правила ссылок, чтобы у пользователя появилась возможность сослаться в одном наборе или элементе данных на другой.
Описание данных
Второй аспект публичных данных – это их эффективное описание, которое в конечном итоге превращается в метаданные. Если для внутренних или защищаемых при передаче данных этот аспект может быть на какое-то время упущен из виду, то для данных, которые размещаются в сети открыто и бесплатно – это очень важно для их последующего эффективного использования.
Для целостной передачи публичных данных, самый лучший способ – это сохранять метаданные «внутри» самих данных. То есть таким образом записывать оригинальные цифровые данные, чтобы они параллельно сопровождались некоторыми атрибутами, а структура записи позволяла алгоритмам извлекать заложенные в неё метаданные.
Что достаточно хорошо можно делать, например, в рамках XML-нотации: где разметка уже определяет тип элемента (узел, атрибут, документ), а применение атрибутов и имен пространств открывает возможности для внедрения метаданных. Однако чтение данных совмещенных с их описанием, как минимум, требует овладения более сложными компетенциями и инструментами. Гораздо понятней и очевидней для большинства пользователей получать чистые данные с наименованием и заголовками. Но это в свою очередь вызывает свои проблемы в чтении и понимании данных. До выработки единых и понятных стандартов в этом направлении пока далеко.
Метаданные должны включать:
Как минимум, пользователю надо обозначить состав и назначение данных, а также дать указание на машинный формат их записи и хранения. Кроме того, хорошо, если метаданные включают оценку качества данных.
Для понимания того, что следует включать в метаданные, можно рассмотреть операции, в которых они фактически применяется или требуются к применению. Вот наиболее важные семь из них с точки зрения двух непосредственно взаимодействующих ролей в рамках public-схемы трансфера данных:
1. Идентификация данных
Качество публичных данных начинается с качества их метаданных.
Окружение данных
Особую роль в отдельных ситуациях начинает играть третий аспект публичных данных – окружение.
Это наиболее сложный из трех рассматриваемых (другие два – содержание и метаданные) – но он наиболее ценный для стратегического и тематического развития аналитики и поиска знаний, особенно с подключением смежной проблематики.
В пространстве публичных данных – контекстом для заданного набора будут являются все иные данные с которыми их смогут корректно связать аналитики по тем или иным основаниям.
Правильно указать контекст можно только если для основных данных правильно задана предметная область и их назначение.
Контекстные связываются с основными данные несколькими способами:
Постоянное разукрупнение анализируемого массива данных путем поиска и подключения к нему дополнительного окружения не может считаться нормой, если является самоцелью. Поэтому рациональным подходом можно назвать обстоятельную работу по тщательному планированию исследования данных в рамках которого обозначают и придерживаются ограниченного набора. Вопрос «а какие данные ещё нужны?» должен задаваться на ключевых этапах анализа в случаях, когда действительно требуется расширить смысловой фронт исследований.
Контекст редко принимается во внимание при публикации данных или при их использовании, либо воспринимается как некое само собой разумеющееся действие по увеличение массива данных. Однако именно неограниченная возможность расширения основы контекстом и многочисленные варианты комбинирования данных позволяют получить преимущество публичного использования данных перед закрытым. В этой связи приоритетным является развитие хранилищ общедоступных и общезначимых цифровых данных, которые составляют контекст для любых данных в заданной предметной области. Например, при работе с экономическими данными может оказаться крайне полезным иметь в свободном доступе общеприменимые справочники, классификаторы, каталоги (например ОКВЭД, КЛАДР, БИК, ЕГРЮЛ и т.п.)
В этих же целях крайне полезны создаваемые и развиваемые тематические «порталы» и «хабы» открытых данных.



