HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Какие существуют веб-архивы Интернета
Я знаю о трёх архивах веб-сайтов (если вы знаете больше, то пишите их в комментариях):
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».

Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:

В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
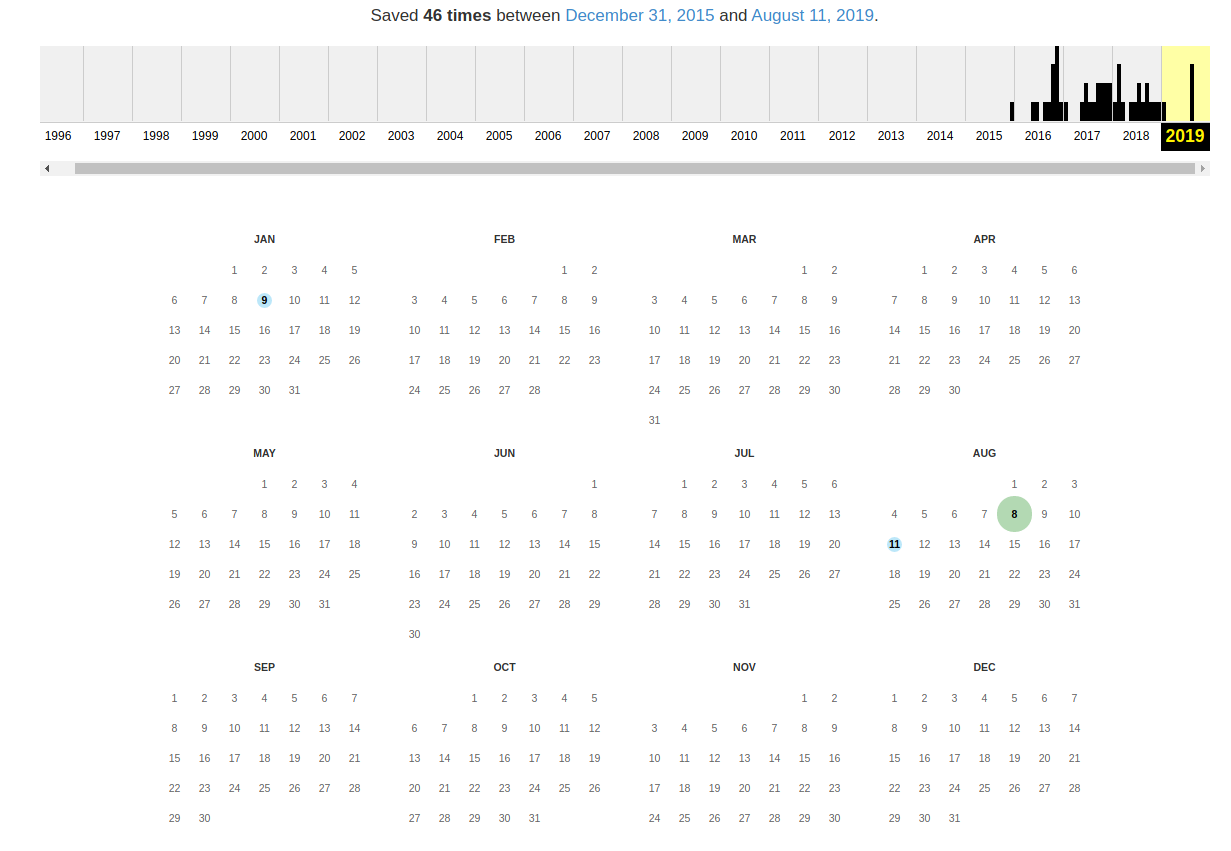
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
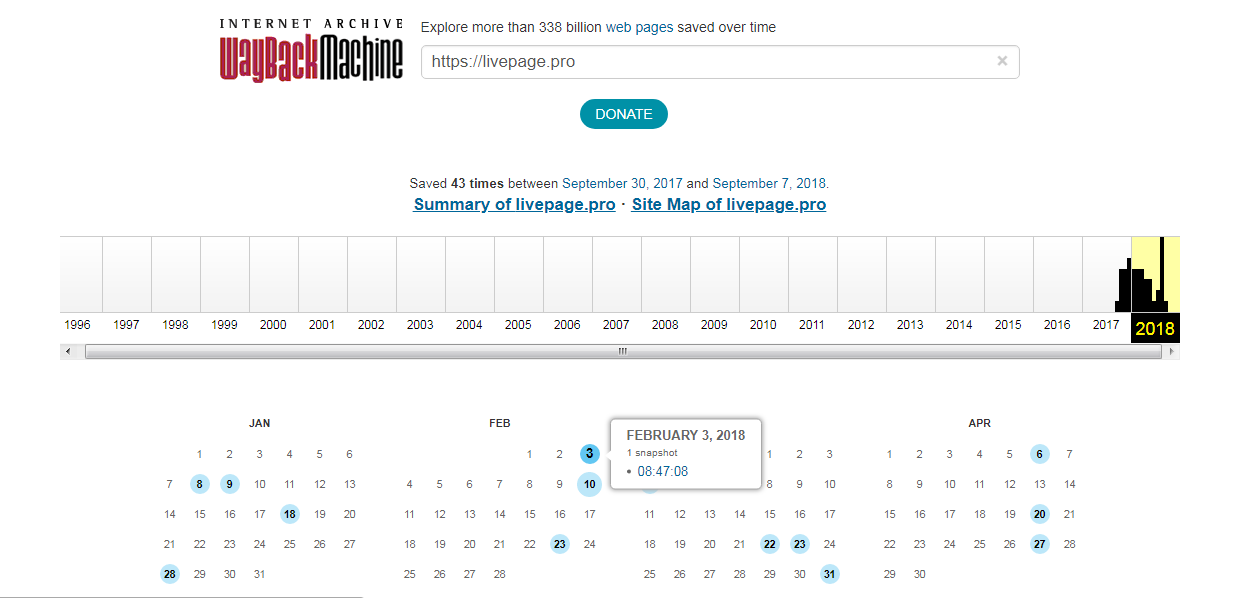
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.

При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:

Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
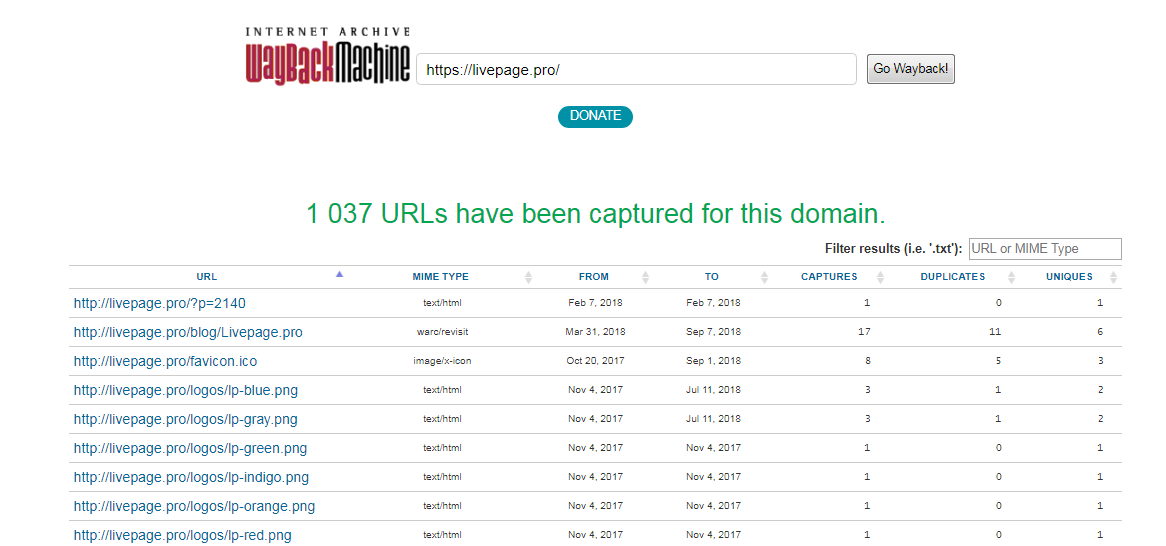
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
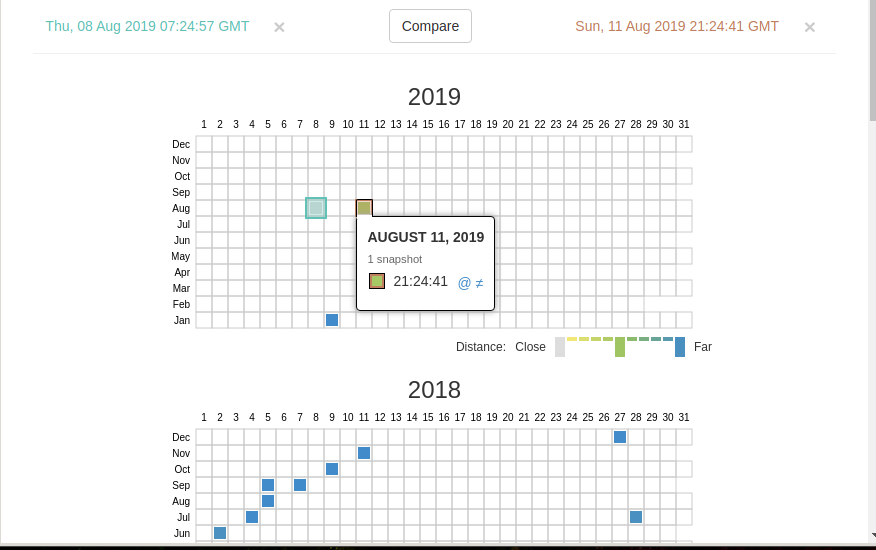
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
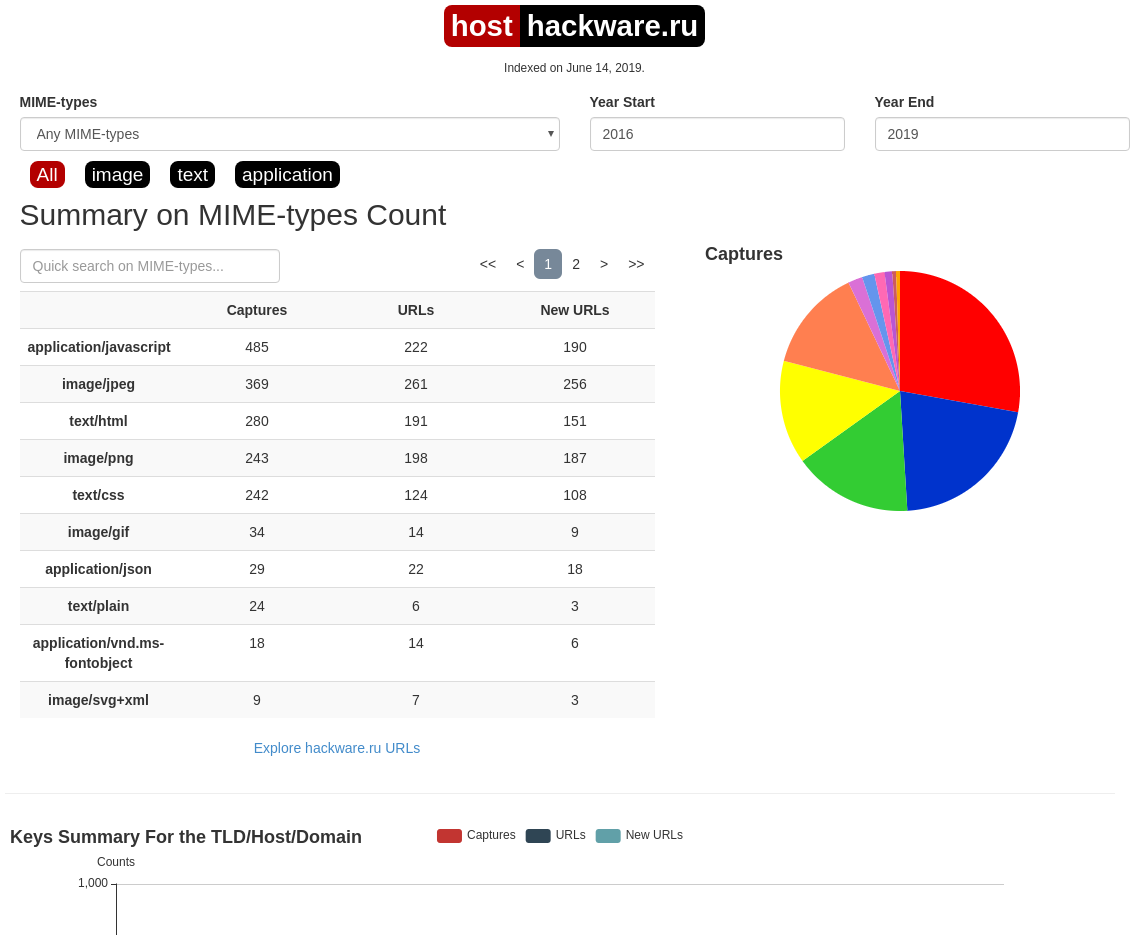
Summary
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Поиск по Интернет архиву
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
Данный сервис сохраняет следующие части страницы:
Не сохраняются следующие части веб-страниц:
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
Дату можно продолжить далее, указав часы, минуты и секунды:
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
Также возможно обратиться ко всем снимкам указанного URL:
Все сохранённые страницы домена:
Все сохранённые страницы всех субдоменов
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
web-arhive.ru
Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату.
На момент написания, этот сервис, вроде бы, нормально не работает («Database Exception (#2002)»). Если у вас есть по нему какие-то новости, то пишите их в комментариях.
Поиск сразу по всем Веб-архивам
Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах.

Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
Например, текстовый вид:
Как полностью скачать сайт из веб-архива
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.
Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx.
Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211
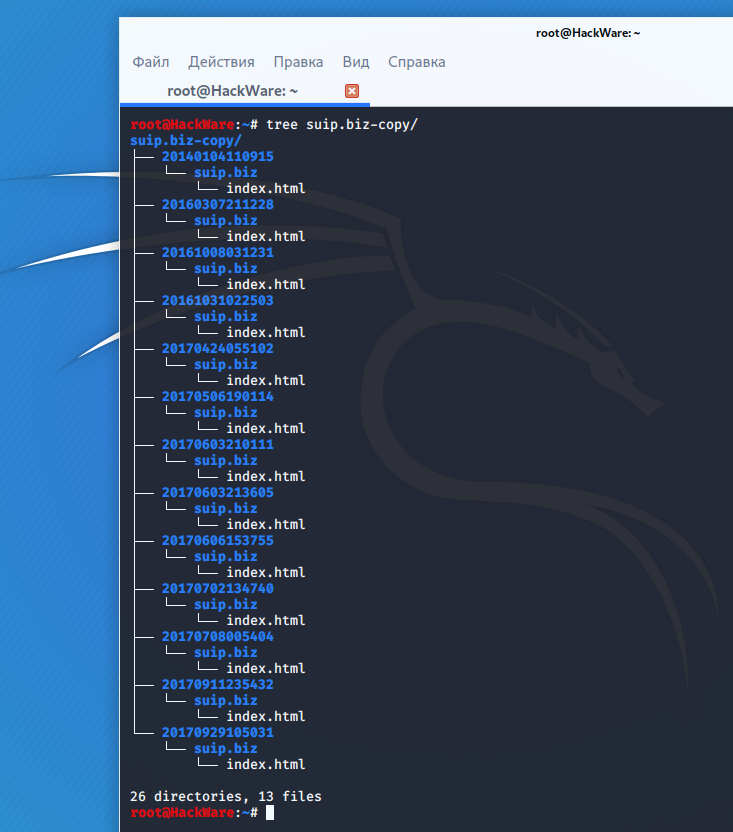
Пример скачивания полной копии сайта suip.biz из веб-архива:
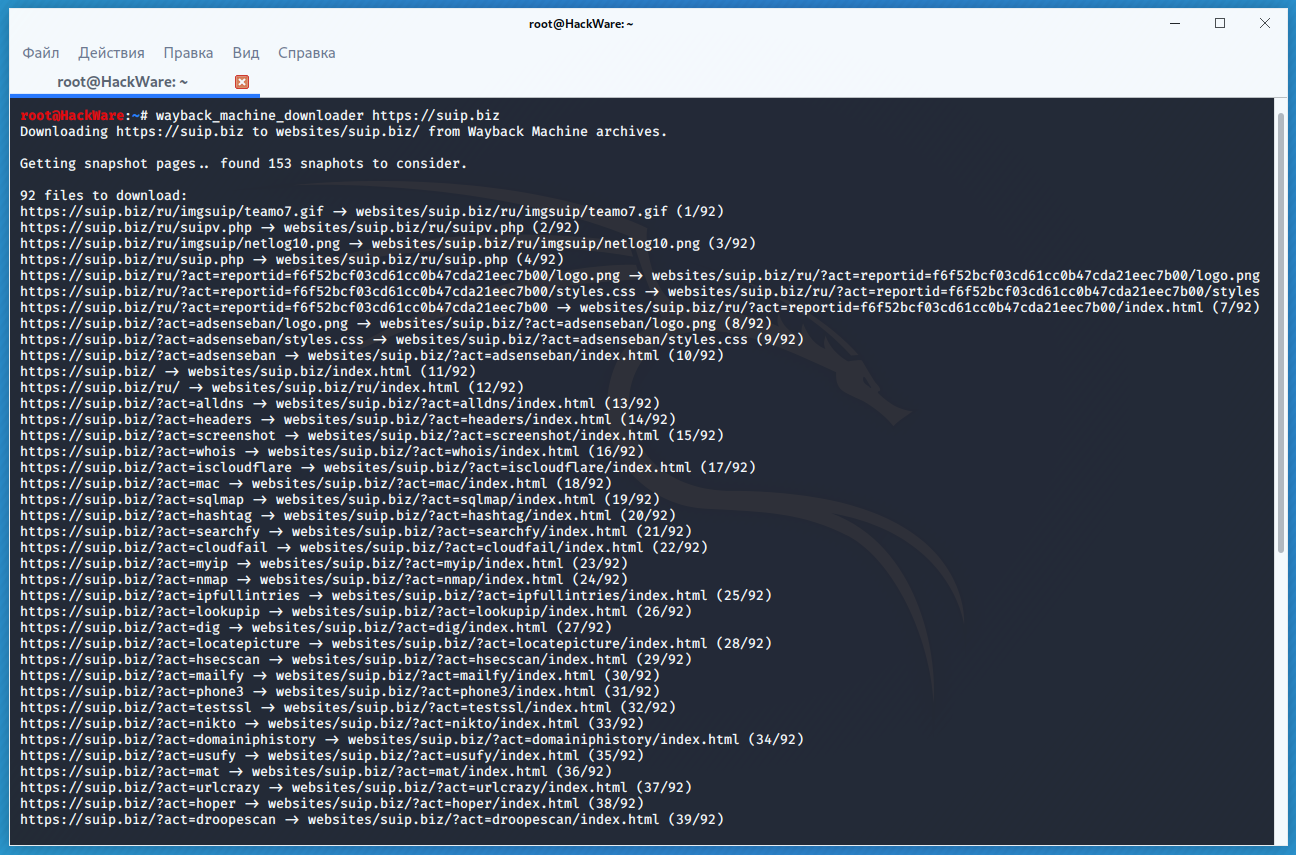
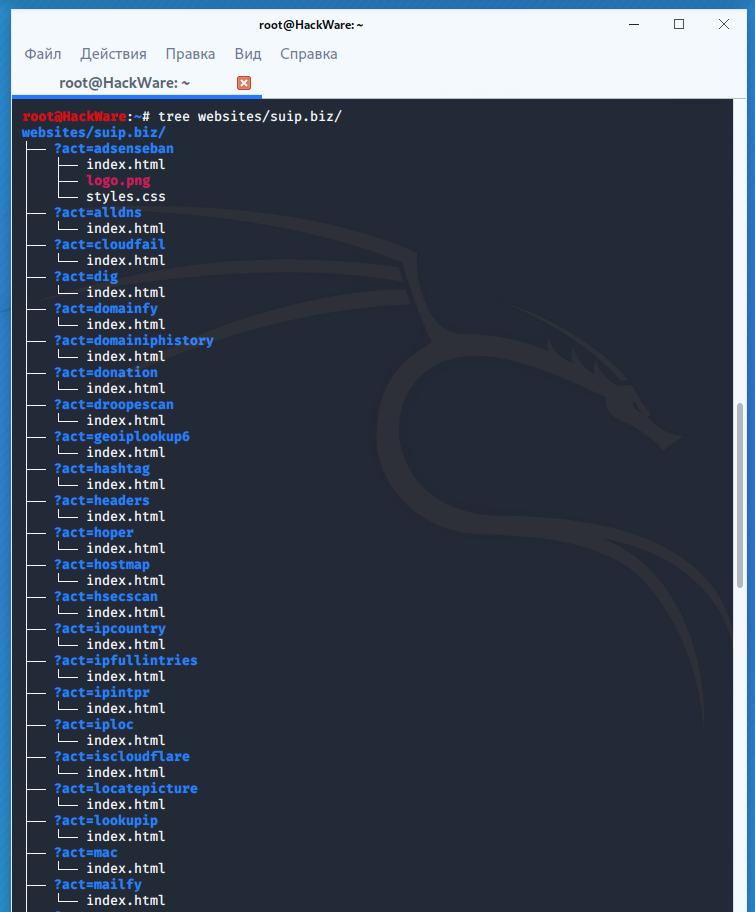
Структура скаченных файлов:
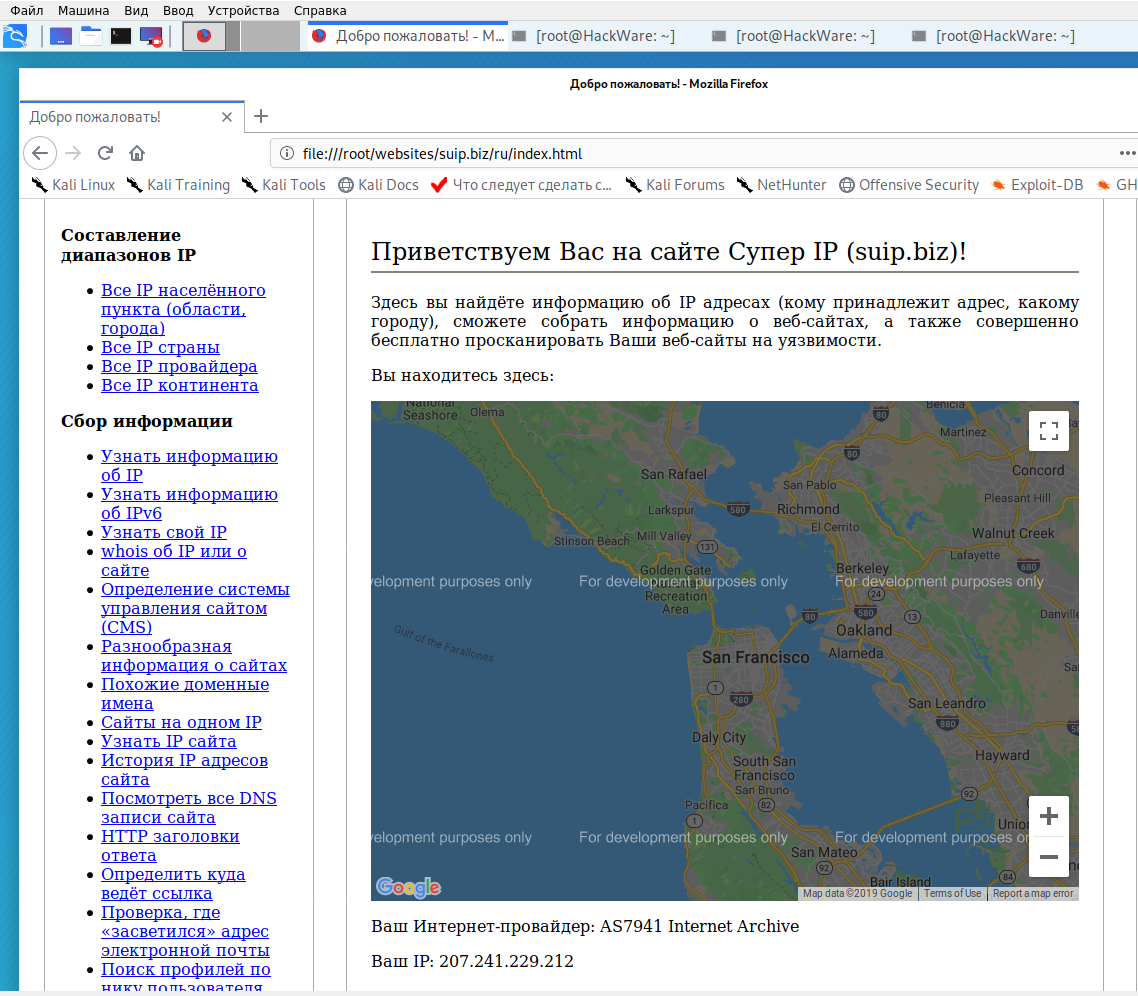
Локальная копия сайта, обратите внимание на провайдера Интернет услуг:
Как скачать все изменения страницы из веб-архива
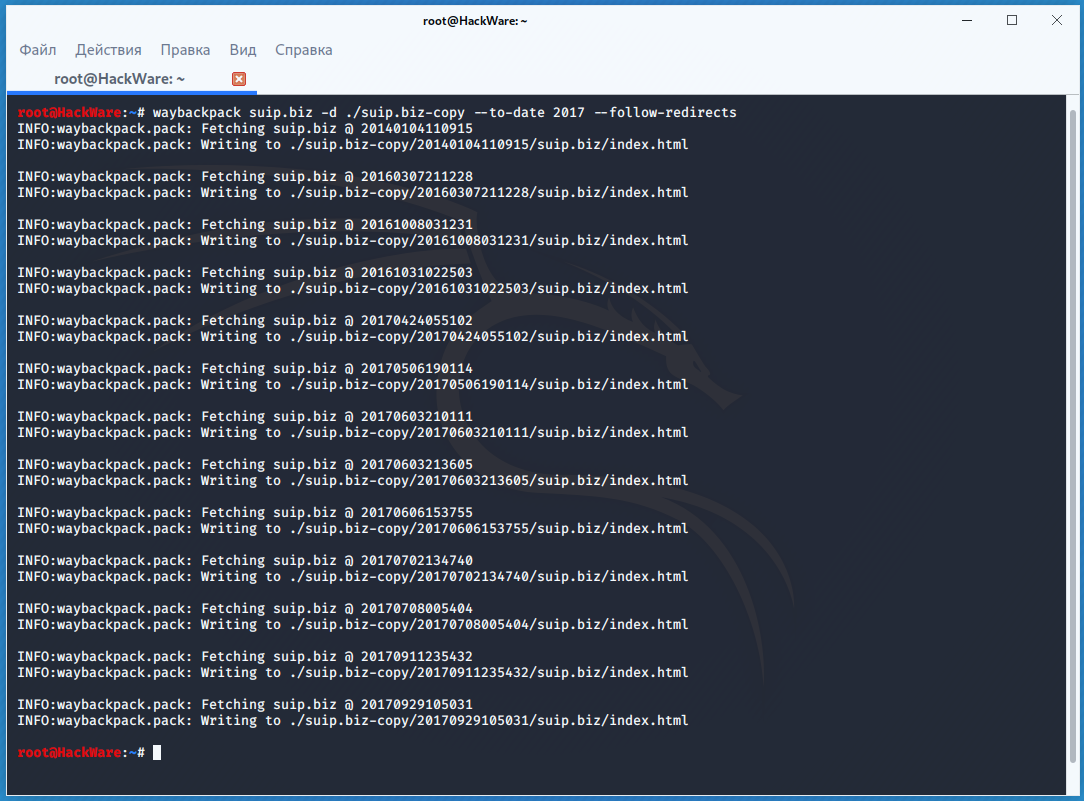
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
Как узнать все страницы сайта, которые сохранены в веб-архиве
Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls.
Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта.
Чтобы получить список всех страниц о которых знает Wayback Machine для домена suip.biz:
Заключение
Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ.
Ещё парочка программ, которые работают с архивом интернета:
Справочная: “Архив Интернета” — история создания, миссия и дочерние проекты

Вероятно, на Хабре не так много пользователей, кто никогда не слышал об «Архиве Интернета» (Internet Archive), сервисе, который занимается поиском и сохранением важных для всего человечества цифровых данных, будь то интернет-странички, книги, видео или информация иного типа.
Кто управляет Интернет-архивом, когда он появился и какова его миссия? Об этом читайте в сегодняшней «Справочной».
Зачем вообще нужен «Архив»?
Это далеко не только развлечение. Миссия организации — всеобщий доступ ко всей информации. «Интернет-архив» стремится бороться с монополией на предоставление информации со стороны как телекоммуникационных компаний (Google, Facebook и т.п.), так и государств.
При этом «Архив» является законопослушной организацией. Если по закону США какую-то информацию необходимо удалить, организация это делает.
«Архив Интернета» также служит инструментом работы ученых, спецслужб, историков (например, археографов) и представителей многих других сфер, не говоря уже об отдельных пользователях.
Когда появился «Интернет-архив»?
Создатель «Архива» — американец Брюстер Кейл, который создал компанию Alexa Internet. Оба его сервиса стали чрезвычайно популярными, оба они процветают и сейчас.
«Интернет-архив» начал архивировать информацию с сайтов и хранить копии веб-страниц, начиная с 1996 года. Штаб-квартира этой некоммерческой организации располагается в Сан-Франциско, США.
Правда, в течение пяти лет данные были недоступны для общего доступа — данные хранились на серверах «Архива», и это все, просмотреть старые копии сайтов могла лишь администрация сервиса. С 2001 года администрация сервиса решила предоставить доступ к сохраненным данным всем желающим.
В самом начале «Интернет-архив» был лишь веб-архивом, но затем организация начала сохранять книги, аудио, движущиеся изображения, ПО. Сейчас «Интернет-архив» выступает хранилищем для фотографий и других изображений НАСА, текстов Open Library и т.п.
На что существует организация?
Как работает «Архив»?
Большинство сотрудников заняты в центрах по сканированию книг, выполняя рутинную, но достаточно трудоемкую работу. У организации три дата-центра, расположенных в Калифорнии, США. Один — в Сан-Франциско, второй — Редвуд Сити, третий — Ричмонде. Для того, чтобы избежать опасности потери данных в случае природной катастрофы или других катаклизмов, у «Архива» есть запасные мощности в Египте и Амстердаме.
«Миллионы людей потратили массу времени и усилий, чтобы разделить с другими то, что мы знаем в виде интернета. Мы хотим создать библиотеку для этой новой платформы для публикаций», — заявил основатель Архива интернета Брюстер Кале (Brewster Kahle)
Насколько велик сейчас “Архив”?
У «Интернет-архива» есть несколько подразделений, и у того, которое занимается сбором информации с сайтов, есть собственное название — Wayback Machine. На момент написания «Справочной» в архиве хранилось 339 миллиардов сохраненных веб-страниц. В 2017 году в «Архиве» хранилось 30 петабайт информации, это примерно 300 млрд веб-страниц, 12 млн книг, 4 млн аудиозаписей, 3,3 млн видеороликов, 1,5 млн фотографий и 170 тыс. различных дистрибутивов ПО. Всего за год сервис заметно «прибавил в весе», теперь «Архив» хранит 339 млрд веб-страниц, 19 млн книг, 4,5 млн видеофайлов, 4,7 млн аудиофайлов, 3,2 млн изображений разного рода, 381 тыс. дистрибутивов ПО.
Как организовано хранение данных?
Информация хранится на жестких дисках в так называемых «дата-нодах». Это серверы, каждый из которых содержит 36 жестких дисков (плюс два диска с операционными системами). Дата-ноды группируются в массивы по 10 машин и представляют собой кластерное хранилище. В 2016 году «Архив» использовал 8-терабайтными HDD, сейчас ситуация примерно такая же. Получается, что одна нода вмещает около 288 терабайт данных. В целом, еще используются жесткие диски и других размеров: 2, 3 и 4 ТБ.
В 2016 году жестких дисков было около 20 000. Дата-центры «Архива» оснащены климатическими установками для поддержания микроклимата с постоянными характеристиками. Одно кластерное хранилище из 10 нод потребляет около 5 кВт энергии.
Структура Internet Archive представляет собой виртуальную «библиотеку», которая поделена на такие секции, как книги, фильмы, музыка и т.п. Для каждого элемента есть описание, внесенное в каталог — обычно это название, имя автора и дополнительная информация. С технической точки зрения элементы структурированы и находятся в Linux-директориях.
Общий объем данных, хранимых «Архивом» составляет 22 ПБ, при этом сейчас есть место еще для 22 ПБ. «Потому, что мы параноики», — говорят представители сервиса.

Посмотрите на скриншот содержимого директории — там есть файл с названием, оканчивающимся на «_files.xml». Это каталог с информацией обо всех файлах директории.
Что будет с данными, если выйдет из строя один или несколько серверов?
Ничего страшного не произойдет — данные дублируются. Как только в библиотеке «Архива» появляется новый элемент, он тут же реплицируется и размещается на различных жестких дисках на разных серверах. Процесс «зеркалирования» контента помогает справиться с проблемами вроде отключения электричества и сбоях в файловой системе.
Если выходит из строя жесткий диск, его заменяют на новый. Благодаря зеркалируемой и редуплицируемой структуре данных новичок сразу же заполняется данными, которые находились на старом HDD, вышедшем из строя.
У «Архива» есть специализированная система, которая отслеживает состояние HDD. В день приходится заменять 6-7 вышедших из строя накопителей.
Что такое Wayback Machine?
Это лишь один из сервисов «Интернет-архива», который специализируется на сохранении веб-страниц. У сервиса есть собственный «паук», который регулярно обследует все доступные в сети сайты и сохраняет их на специализированных серверах. Чем популярнее веб-сайт, тем чаще робот копирует его содержимое. Если администратор ресурса не желает, чтобы информация сайта копировалась ботом, достаточно прописать запрет в файле robots.txt.
Популярные ресурсы копируются часто — практически ежедневно. Wayback Machine индексирует даже социальные сети, включая Twitter, Facebook
В 2017 году «Архив» запустил обновленный сервис Wayback Machine, пообещав более удобный доступ к сохраненным веб-страницам. Сервис был написан если не с нуля, то здорово переработан. Теперь он поддерживает ряд форматов файлов, которые ранее просто не сохранялись В том же 2017 году организация заявила, что каждую неделю ее сервера сохраняют около 1 млрд веб-страниц.
Так выглядел Twitter в 2007 году
Что еще можно найти в базе «Интернет-архива»?
Книги. Коллекция организации огромна, она включает оцифрованные книги, как распространенные, так и очень редкие издания. Книги сохраняются не только англоязычные, но и на многих других языках. У «Архива» есть специализированные центры по сканированию книг, всего таких центров 33, расположены они в пяти странах по всему миру.
В день сотрудники центров сканируют около 1000 книг. В базе сервиса содержатся миллионы изданий, работа по их оцифровке финансируется как обычными людьми, так и различными организациями, включая библиотеки и фонды.
С 2007 года «Интернет-архив» сохраняет в своей базе общедоступные книги из Google Book Search. После запуска, база книг быстро разрослась — в 2013 году насчитывалось уже более 900 тысяч книг, сохраненных из сервиса Google.
Один из сервисов «Архива» также предоставляет доступ к книгам, которые полностью открыты, таковых насчитывается уже более миллиона. Называется этот сервис Open Library.
Видео. Сервис хранит 4,5 млн роликов. Они разбиты по тематикам и имеют самую разную направленность. На серверах «Архива» хранятся фильмы, документальные фильмы, записи спортивных соревнований, ТВ-шоу и многие другие материалы.
В 2015 году «Архив» дал начало масштабному проекту — оцифровке видеокассет. Сначала речь шла о 40 тысячах кассет из архива Мэрион Стоукс, женщины, которая в течение многих десятилетий записывала на кассеты новости. Затем добавились и другие видеокассеты, которые присылали «Архиву» поклонники идеи оцифровки данных, важных для человечества.
Аудио. Аналогично видео, «Архив» хранит и аудиофайлы, которые также разбиты по тематикам. В прошлом году «Архив» начал реализовывать свой новый проект — расшифровку шеллачных пластинок, старейшего формата аудиозаписей. Звук сохранялся на пластинках из шеллака — природной смолы, которую выделяют самками червецов. Всего в архиве Great 78 Project несколько сотен тысяч пластинок.
Программное обеспечение. Конечно, хранить все созданное человечеством ПО просто невозможно, даже для «Архива». На серверах хранится винтаж — например, программы для Macintosh, ПО под DOS и прочий софт. В 2016 году сотрудники «Архива» выложили 1500+ программ под Windows 3.1, работать можно прямо в браузере. В 2017 Internet Archive выпустил архив софта для первых Macintosh.
Игры. Да, «Архив» предоставляет доступ к огромному количеству игр. В некоторые из них можно поиграть в среде браузерного эмулятора. Игры хранятся самые разные, в том числе, и с портативных аналогово-цифровых приставок. Есть игры под MS-DOS и консольные игры для Atari и ColecoVision.
Впервые архив старых игр организация выложила еще в 2013 году. Речь идет о тайтлах 30–40 летней давности, в которые можно было играть прямо в браузере. Это игры для приставок Atari 2600 (1977 года выпуска), Atari 7800 (1986 г.), ColecoVision (1982 г.), Philips Videopac G7000 (1978 г.) и Astrocade (1983 г.). Самое интересное, что Internet Archive добился того, что играть можно вполне легально. Сейчас коллекция насчитывает уже более 3400 игр и продолжает пополняться.
Web Archive: как посмотреть, как выглядел сайт раньше?


Интернет в привычном для нас виде появился 36 лет назад — за это время он развивался семимильными шагами, а сайты тысячи раз меняли свой дизайн и контент. Web archive представляет собой своеобразную машину времени, которой может воспользоваться каждый пользователь.
Что такое Web Archive?
Это бесплатный сервис, где собраны истории многих интернет ресурсов — их архивные копии. Причем речь идет не о скриншотах, а о полноценных страницах с изображениями, рабочими ссылками и стилевым оформлением.
Получение информации о том или ином домене предполагает не только интересное времяпровождение с отслеживанием эволюции веб-проекта, но еще и возможность:
История создания архива интернета
Wayback Machine является одним из двух главных проектов archive.org. Этот некоммерческий сервис был создан в 1996 году Брюстером Кейлом. Машина времени сайтов имеет четкую цель: сбор и хранение копий ресурсов вместе со всем контентом для возможности свободного просмотра несуществующих или неподдерживающихся страниц в будущем. С 1999-го робот стал фиксировать еще и аудио, видео, иллюстрации, программное обеспечение.
База современного архива собиралась в течение 20 лет, у нее не существует аналогов. Статистика впечатляет: на сегодняшний день в сервисе находится 279 миллиардов страниц, 11 миллионов книг и статей, 100 тысяч программ и миллион картинок.
А знаете ли вы? Веб-архив сайтов часто имеет проблемы на законодательном уровне из-за нарушения авторских прав. По требованию правообладателей библиотека удаляет материалы из публичного доступа.
Как пользоваться веб-архивом?
Сервис очень удобный в применении. Пошаговая инструкция такова:

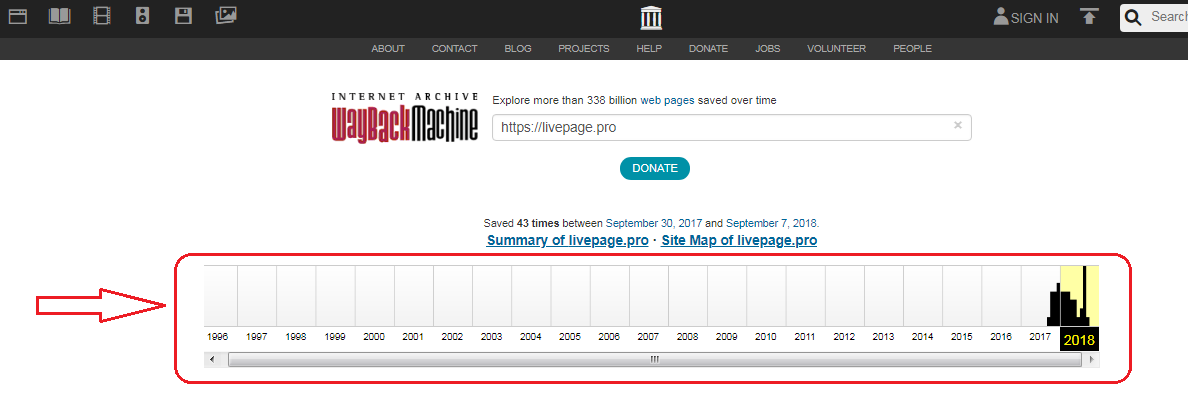
Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!
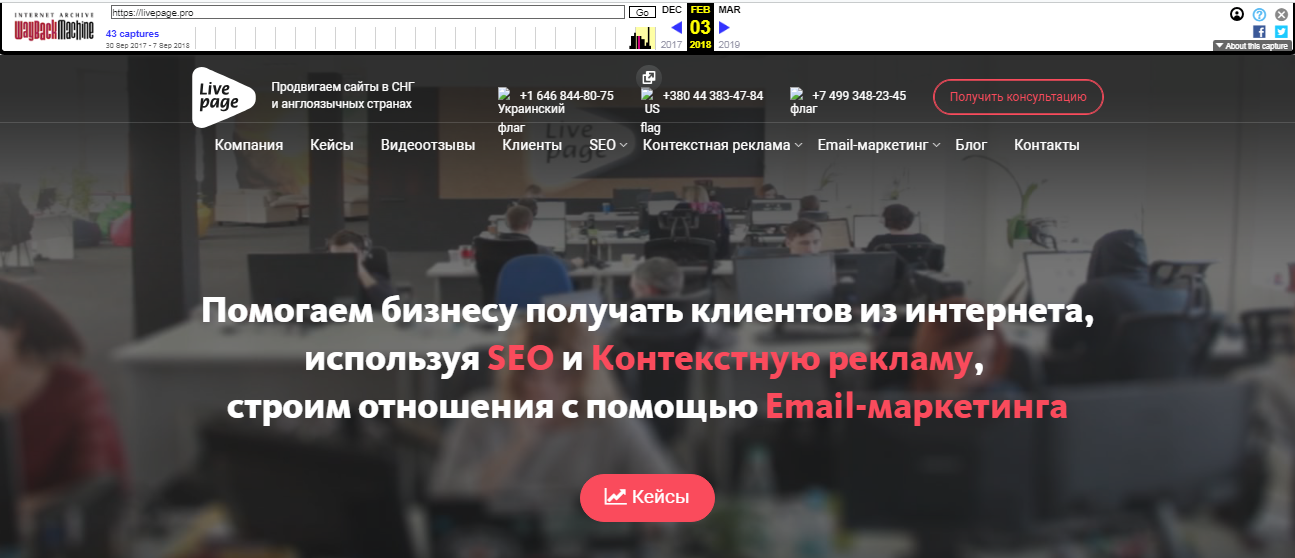
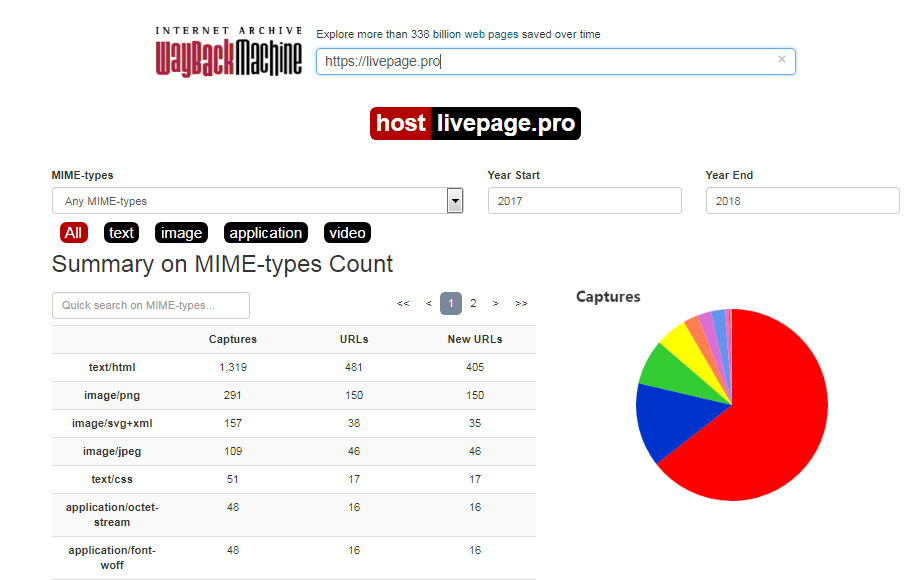
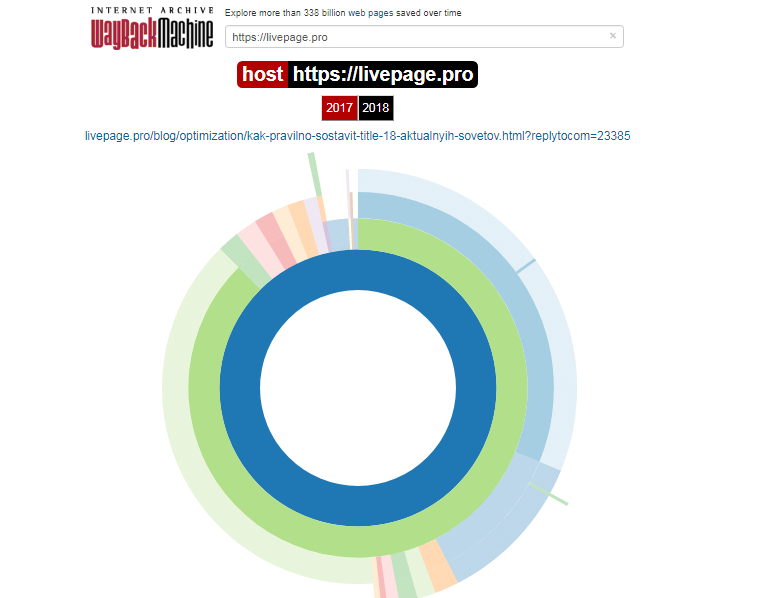
Алгоритм действий можно сократить. Для работы с сервисом напрямую, введите в строке своего браузера
В нашем случае это
Как восстановить сайт из веб-архива?
Плохая новость для тех, кто планирует просто найти архив сайта и скачать его привычным способом: страницы имеют вид статических html-файлов, к тому же их слишком много для того, чтобы заниматься этим вручную. Решить проблему можно при помощи специальных программ, к примеру, приложения на ruby. Необходимо лишь установить все на сервер и запустить восстановление страниц.
apt-get install ruby

gem install wayback_machine_downloader

Для удобства можно указать отметку снапшота — утилита определит число страниц и выведет выкачиваемые файлы на консоль. После скачивания и сохранения мы получим набор статических данных.

Как восстановить сайт без бэкапа?
Вернуть ресурс из небытия можно даже без резервного копирования.
Войдите в режим расширенного поиска и укажите имя сайта. Получив результаты, кликайте по ссылкам «cached» или «копия».
Учтите!
Нужный вам проект может и не входить в архив сайтов интернета. Если вы его не нашли в библиотеке — значит, правообладатель потребовал удаления копий или же ресурс закрыли в соответствии с законом о защите интеллектуальной собственности. Возможен и другой вариант: через файл robots.txt был банально внесен соответствующий запрет.
Как найти уникальный контент из веб-архива для вашего сайта?
Статьи, расположенные на заброшенных ресурсах, обычно не представляют никакой ценности для их бывших владельцев. А ведь в мир иной ежедневно уходят десятки сайтов. И среди кучи хлама, выброшенного на помойку истории, можно найти настоящие самородки — приличные тексты, которые достанутся вам бесплатно.
Поисковики хорошо относятся к любому актуальному и уникальному контенту — можно не бояться попасть в их немилость только из-за того, что статьи взяты из веб-архива чужого сайта.
Итак, последовательность действий следующая:
При разумном подходе такой способ пополнения сайта контентом можно поставить на поток. Поиски материалов на мертвых блогах оправданы экономией времени на написание текстов и денег, которые бы вам пришлось заплатить авторам.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива?
Если вы дорожите контентом и не хотите видеть свою онлайн-площадку в электронной библиотеке, пропишите запретную директиву в файле robots.txt:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
После изменения в настройках веб-сканер перестанет создавать архивные копии вашего сайта, к тому же удалит уже сделанные слепки. Однако учтите, что ваш запрет действует лишь до тех пор, пока доступен robots.txt — когда закончится срок регистрации доменного имени, машина времени сайтов станет демонстрировать статьи всем желающим.
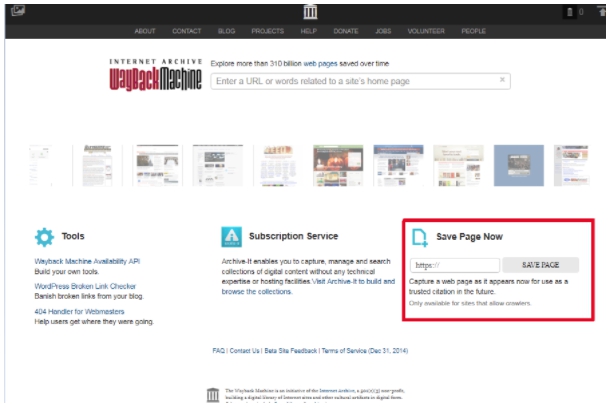
Важно! Если вы, наоборот, желаете активно пользоваться веб-архивом, введите соответствующий запрос на главной странице сервиса. Просто укажите адрес проекта в разделе Save Page Now, после чего нажмите кнопку Save Page. Повторяйте процедуру после внесения любых правок.
Аналоги Webarchive
Альтернативой рассматриваемой в обзоре электронной библиотеке может стать:



