Индексная страница сайта
Индексная страница — это файл, который соответствует каталогу, запрашиваемому пользователем. Допустим пользователь через браузер запрашивает страницу http://www.сайт.ru/, сервер обрабатывает запрос и выдает страницу в таком виде http://www.сайт.ru/index.html, так как по данному адресу настроена индексная страница index.html.
Если в запрашиваемом каталоге нет соответствующего файла, сервер выдаст ошибку 403.
В некоторых CMS обычно используются следующие индексные файлы:
На нашем хостинге используются стандартные индексные файлы (index.php, index.htm, index.html), поэтому дополнительных действий по изменению индексных страниц, при использовании нашего хостинга, не требуется.
Индексный файл нужен для того, чтобы направить пользователя на нужную страницу.
Как поменять индексные страницы?
Для того, чтобы изменить индексные файлы, требуется открыть раздел «WWW-домены», выбрать нужный домен и нажать кнопку «Изменить». Выбрать поле «Индексная страница» и изменить индексные файлы. Список имён индексных файлов указывается через пробел в порядке убывания значимости. Важно знать, сервер открывает файлы в порядке очереди от более значимых до менее значимых.

Web-сервер будет искать данные файлы, если URL указан без имени файла. Если список пуст, то значения будут использованы из глобальных настроек Web-сервера.
Что такое индексный файл index.html
Когда вы создаёте веб-страницы в редакторе кода, таком как Visual Studio Code, Sublime Text, вам необходимо создать index.html, потому что эта страница выполняет важную работу. Создание первой страницы index.html считается лучшим методом веб-разработки.
Итак, что такое страница index.html и почему она имеет значение? В этой статье рассказывается о index.html и о том, почему вы всегда должны создавать эту страницу при создании веб-сайта.
Что такое index.html?
Index.html — это первая HTML-страница, которую вы создаёте при создании веб-сайта. HTML (язык разметки гипертекста) помогает структурировать текст и другие элементы на веб-странице. Страница index.html — это страница по умолчанию, которую видит посетитель веб-сайта, если не указана другая страница, которую часто называют «домашней страницей».
Например, если вы вводите URL-адрес, такой как https://careerkarma.com, вы не указали какую-либо конкретную страницу, которую сервер должен доставить клиенту (компьютеру или мобильному телефону). Во многих случаях вы увидите страницу по умолчанию или страницу index.html.
Если вы знаете точный адрес страницы, которую хотите просмотреть, например https://careerkarma.com/blog, то сервер направит вас на эту страницу, а не на страницу index.html.
index.html легко распознаётся на большинстве серверов как страница по умолчанию, поэтому многие разработчики предпочитают использовать index.html в качестве имени страницы по умолчанию.
Как создать страницу index.html
Теперь вы понимаете, что такое страница index.html и почему она важна. Давайте посмотрим, как именно мы можем создать страницу index.html с помощью Visual Studio Code (или VS Code), редактора кода.
Если у вас не установлен VS Code, ознакомьтесь с этим полезным руководством по началу работы с Visual Studio Code.
Начнём с создания нового файла.
На главной панели инструментов VS Code создайте новый файл. 
Затем вам будет показан пустой файл кода с таким именем, как «Без названия» или «Без названия-1». 
Затем перейдите в «Файл», «Сохранить как» и сохраните имя файла как «index» с типом файла «html». 
Теперь вы увидите «index.html» в качестве имени вашего файла. 
По умолчанию в файле index.html должно быть несколько элементов. К ним относятся HTML-теги, такие как,и. Вы также должны объявить тип документа, используя «DOCTYPE HTML». 
Индексные файлы и их использование.
Дата добавления: 2013-12-23 ; просмотров: 4328 ; Нарушение авторских прав
Программистам хорошо известно, что упорядоченность является мощным инструментом эффективной обработки данных. В условиях многоцелевого использования данных возникает естественная потребность иметь для одной таблицы несколько видов ее упорядоченного представления. Хранить несколько копий таблицы, по-разному упорядоченных, и поддерживать их адекватность – не самый лучший вариант решения этой проблемы. Типовой метод – использование индексных файлов.
Индексный файл – создается для фиксированной пары: таблица данных, ключ упорядочения. Ключ упорядочения обычно задается списком полей таблицы и определяет порядок – по неубыванию ключа.
§ количество строк в индексном файле совпадает с их количеством файле данных;
§ индексный файл упорядочен по неубыванию ключа.
Индексный файл обеспечивает эффективный доступ к строке таблицы данных по заданному ее ключу (упорядочения):
§ сначала логарифмический поиск в индексном файле по ключу;
§ потом доступ к строке таблицы данных по ее номеру (эффективность этого доступа обеспечивают физические устройства хранения данных).
Реальное представление индексного файла может быть и другим. Сегодня чаще всего используются В-деревья сортировки. Кроме того, ускорение поиска достигается за счет предпочтительной буферизации индексного файла в основной памяти. Индексный файл не обязательно представляется в виде отдельного физического файла.
В современных СУБД индексные файлы широко используются, как для внутренних целей, так и в качестве инструмента, предоставляемого программистам напрямую.
SQL-ориентированные СУБД, в частности InterBase:
§ создают и используют индексные файлы для внутренних целей, в частности для объявленных ключей – уникальных (UNIQUE), первичных (PRIMARY KEY), дочерних (FOREIGN KEY);
§ позволяют явно создавать индексные файлы
CREATE [UNIQUE] [ASC | DESC] INDEX ИмяИндексФайла
ON ИмяТаблицыДанных (ИмяКолонки. )
§ поддерживают индексные файлы – обеспечивают их соответствующую корректировку при внесении изменений в данные таблиц;
§ допускают прямое использование индексных файлов программистами через посредников, предоставляющих Record-ориентированные средства обработки БД.
Использование индексных файлов в Delphi. Свойства и методы объекта типа TTable позволяют:
¨ Установить логический порядок строк в таблице.
§ property IndexName: String;
Устанавливает логический порядок, соответствующий указанному имени индексного файла.
§ property DefaultIndex: Boolean;
Устанавливает логический порядок по умолчанию, действующий только при пустом IndexName. Если DefaultIndex=TRUE и таблица имеет первичный ключ, то он и определяет логический порядок, иначе используется физический порядок.
Отметим, что ранее рассмотренные First, Next, Eof. выполняются в соответствии с текущим установленным логическим порядком.
¨ Выполнить поиск по ключу.
(const KeyValues: array of const): Boolean;
FindKey выполняет поиск строки по ее ключу, заданное значение ключа (значение KeyValues) должно соответствовать текущему логическому порядку. Если строка была найдена, то она становится текущей и FindKey возвращает TRUE.
¨ Установить операционную связь (Master-Detal).
В операционной связи участвуют две таблицы Ведущая (Master) и Ведомая (Detal), любое перемещение маркера текущей строки в ведущей таблице вызывает перемещение в ведомой на соответствующую строку. Операционная связь определяется (и реализуется) с помощью двух ключей:
§ Для Detal-таблицы (ведомой) надо установить логический порядок (индексный файл), его ключ упорядочения используется в качестве Detal-ключа.
§ Для Master-таблицы (ведущей) надо указать Master-ключ (список полей Master-таблицы).
§ В операционной связи Detal-таблица автоматически позиционируется на строке, у которой Detal-ключ равен Master-ключу текущей строки Master-таблицы.
Для установления связей с объектами – источниками данных в Delphi используются объекты специального классаTDataSource. Мы рассмотрим только одно свойство объектов этого класса property DataSet: TDataSet. Оно позволяет указать на объект типа TTable – источник данных.
Операционная связь устанавливается в объекте типа TTable, управляющем Detal-таблицей:
§ property IndexFieldNames: String;
§ property MasterSource: TDataSource;
Эта ссылка на объект типа TDataSource, у которого свойство DataSet ссылается на объект типа TDataSet, приводит к Master-таблице.
§ property MasterFields: string;
ПРИМЕР. Решение задачи «о крупных поставках».
СХЕМА СВЯЗЕЙ ОБЪЕКТОВ

результата решения задачи>
PstTable(Master) 1000) THEN
WHILE NOT PstsTable.EOF AND
procedure TForm1.N3Click(Sender: TObject);
WHILE NOT PstTable.EOF DO
IF (PstTable.FieldByName(‘KDet’).Value=1010) AND
так. функцию можно вызвать как процедуру,
по крайней мере иногда.>
procedure TForm1.N4Click(Sender: TObject);
WHILE NOT PstTable.EOF DO
IF (PstTable.FieldByName(‘KDet’).Value=1010) AND
Средства обработки БД в СУБД FoxPro.DBL(FOX).doc
4. Теоретические основы реляционной модели баз данных.
4.1. Перечислимые отношения и способы их задания: алгоритмический, алгебраический и логический подходы.
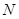 = <0,1,2. >натуральный ряд.
= <0,1,2. >натуральный ряд. 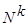 — множество всех векторов длины k с элементами из N. Отношение RÍ, R: FILE OF RECORD x1,x2. xk: Natural END
— множество всех векторов длины k с элементами из N. Отношение RÍ, R: FILE OF RECORD x1,x2. xk: Natural END
В теории рассматриваются в том числе и бесконечные отношения-файлы. Дело в том что задачи «Вычислить y=f(x)» и «Перечислить отношение <(x,y)/y=f(x)>» сводимы друг к другу (по крайней мере для xÎN).
§ ничего не вводит, только выводит;
§ Фиксируется конечный набор базовых отношений.
§ Фиксируется конечный набор операций над отношениями O: R1. Rк ® R.
§ R перечислимо относительно R1. Rк – имеется аналогичное выражение, в котором дополнительно к базовым можно использовать отношения R1. Rк.
Один из вариантов такой алгебраической системы:
§ Mult: (x,y,z)ÎMult Û x*y=z
§ Группа теоретико-множественных операций: È, Ç и – (дополнение).
§ Группа операций явного преобразования.
Пусть RÍ, I1. Ik Î <1,2. n>È<#d/ dÎN>.
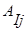
Примеры важных (для последующего материала) операций. Пусть k=8.
· Выборка по значению компонента.
· Выборка по равенству значений двух компонентов.
· Перестановка (переименование) компонентов.
· Цилиндрификация – декартово умножение на N.
для каждого dÎN такого, что (d £ di), имеет место (d1. d. dk)ÎR>
имеется dÎN такое, что (d £ di) и (d1. d. dk)ÎR>
§ Проекция ($-квантификация неограниченная).
имеется dÎN такое, что
(d1. 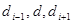 . dk)ÎR>
. dk)ÎR>
Перечислимое отношение – можно получить проекциями из подходящего конструктивно определимого отношения.
4.2. Реляционная алгебра.
Ниже используются обозначения:
Базовый набор операций над файлами.
Ø Естественное соединение R*S=
Ø Переименование полей [A1®B1,A2®B2. ](R). A1,A2. должны быть именами полей файла R, а поля B1,B2. должны иметь соответствующий тип. Результат операции будет содержать те же записи, что и файл R, но поля A1,A2. будут соответственно переименованы на B1,B2.
Ø Проекция [имя_поля. ](R) = файл записей из R, в которых удалены все поля, кроме перечисленных в операции.
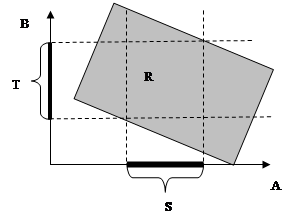
ПРИМЕР. Решение вышерассмотренной задачи «о крупных поставках» описывается реляционным выражением:
4.3. Реляционное исчисление кортежей.
Базовые (элементарные) формулы:
· 
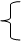 r.A операция s.B
r.A операция s.B
константа сравнения константа
имеет смысл «поле A записи r (или константа) имеет значение больше (меньше, равно. ), чем поле B записи s (или константа)».
· логики предикатов «$: если F формула, то «rÎR F и $rÎR Fтоже формулы.
· формула «rÎR F истинна, если формула F истинна для любой записи r из файла R
· формула $rÎR F истинна, если формула F истинна хотя бы для одной записи r из файла R.
· каждой формуле соответствует файл записей, на которых эта формула истинна;
· формуле «rÎR F соответствует файл F¸R;
· формуле $rÎR F соответствует проекция файла F по полям, которые отсутствуют в rÎR.
· найти запись r в файле R, s в файле S. такие что на этом наборе записей истинна формула F;
ПРИМЕР. Вышеприведенный рисунок, иллюстрирующий операцию деления T=(R¸S), соответствует запросу T=НАЙТИ
ПРИМЕР. Решение вышерассмотренной задачи «о крупных поставках» описывается запросом реляционного исчисления кортежей:
(r.KPst=s.KPst)&(s.KDet=1010)&(s.Kol>1000)
ПРИМЕР. Найти имена поставщиков, которые поставляют все красные детали.
Индексные файлы
Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не всегда удается найти соответствующую функцию, поэтому при организации доступа по первичному ключу широко используются индексные файлы. В некоторых коммерческих системах индексными файлами называются также и файлы, организованные в виде инвертированных списков, которые используются для доступа по вторичному ключу. Мы будем придерживаться классической интерпретации индексных файлов и надеемся, что если вы столкнетесь с иной интерпретацией, то сумеете разобраться в сути, несмотря на некоторую путаницу в терминологии. Наверное, это отчасти связано с тем, что область баз данных является достаточно молодой областью знаний, и несмотря на то, что здесь уже выработалась определенная терминология, многие поставщики коммерческих СУБД предпочитают свой упрощенный сленг при описании собственных продуктов. Иногда это связано с тем, что в целях рекламы они не хотят ссылаться на старые, хорошо известные модели и методы организации информации в системе, а изобретают новые названия при описании своих моделей, тем самым пытаясь разрекламировать эффективность своих продуктов. Хорошее знание принципов организации данных поможет вам объективно оценивать решения, предлагаемые поставщиками современных СУБД, и не попадаться на рекламные крючки.
Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно физическое совмещение этих двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс. Но нам удобнее рассматривать эти две части совместно, так как именно взаимодействие этих частей и определяет использование механизма индексации для ускорения доступа к записям.
Мы предполагаем, что сначала идет индексная область, которая занимает некоторое целое число блоков, а затем идет основная область, в которой последовательно расположены все записи файла.
В зависимости от организации индексной и основной областей различают 2 типа файлов: с плотным индексом и с неплотным индексом. Эти файлы имеют еще дополнительные названия, которые напрямую связаны с методами доступа к произвольной записи, которые поддерживаются данными файловыми структурами.
Файлы с плотным индексом называются также индексно-прямыми файлами, а файлы с неплотным индексом называются также иидексно-последовательными файлами. Смысл этих названий нам будет ясен после того, как мы более подробно рассмотрим механизмы организации данных файлов.
Физические модели баз данных
Организация стратегии свободного замещения
При этой стратегии файловое пространство не разделяется на области, но для каждой записи добавляется 2 указателя: указатель на предыдущую запись в цепочке синонимов и указатель на следующую запись в цепочке синонимов. Отсутствие соответствующей ссылки обозначается специальным символом, например нулем. Для каждой новой записи вычисляется значение хэш-функции, и если данный адрес свободен, то запись попадает на заданное место и становится первой в цепочке синонимов. Если адрес, соответствующий полученному значению хэш-функции, занят, то по наличию ссылок определяется, является ли запись, расположенная по указанному адресу, первой в цепочке синонимов. Если да, то новая запись располагается на первом свободном месте и для нее устанавливаются соответствующие ссылки: она становится второй в цепочке синонимов, на нее ссылается первая запись, а она ссылается на следующую, если таковая есть.
Если запись, которая занимает требуемое место, не является первой записью в цепочке синонимов, значит, она занимает данное место «незаконно» и при появлении «законного владельца» должна быть «выселена», то есть перемещена на новое место. Механизм перемещения аналогичен занесению новой записи, которая уже имеет синоним, занесенный в файл. Для этой записи ищется первое свободное место и корректируются соответствующие ссылки: в записи, которая является предыдущей в цепочке синонимов для перемещаемой записи, заносится указатель на новое место перемещаемой записи, указатели же в самой перемещаемой записи остаются прежние.
После перемещения «незаконной» записи вновь вносимая запись занимает свое законное место и становится первой записью в новой цепочке синонимов.
Механизмы удаления записей во многом аналогичны механизмам удаления в стратегии с областью переполнения. Однако еще раз кратко опишем их.
Если удаляемая запись является первой записью в цепочке синонимов, то после удаления на ее место перемещается следующая (вторая) запись из цепочки синонимов и проводится соответствующая корректировка указателя третьей записи в цепочке синонимов, если таковая существует.
Если же удаляется запись, которая находится в середине цепочки синонимов, то производится только корректировка указателей: в предшествующей записи указатель на удаляемую запись заменяется указателем на следующую за удаляемой запись, а в записи, следующей за удаляемой, указатель на предыдущую запись заменяется на указатель на запись, предшествующую удаляемой.
Вопросы для самостоятельной работы
Индексные файлы
Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не всегда удается найти соответствующую функцию, поэтому при организации доступа по первичному ключу широко используются индексные файлы. В некоторых коммерческих системах индексными файлами называются также и файлы, организованные в виде инвертированных списков, которые используются для доступа по вторичному ключу. Мы будем придерживаться классической интерпретации индексных файлов и надеемся, что если вы столкнетесь с иной
Мы предполагаем, что сначала идет индексная область, которая занимает некоторое целое число блоков, а затем идет основная область, в которой последовательно расположены все записи файла.
В зависимости от организации индексной и основной областей различают 2 типа файлов: с плотным индексом и с неплотным индексом.Эти файлы имеют еще дополнительные названия, которые напрямую связаны c методами доступа к произвольной записи, которые поддерживаются данными файловыми структурами.
Файлы с плотным индексом называются также индексно-прямыми файлами, а файлы с неплотным индексом называются также индексно-последовательными файлами. Смысл этих названий нам будет ясен после того, как мы более подробно рассмотрим механизмы организации данных файлов.
Файлы с плотным индексом, или индексно-прямые файлы
Рассмотрим файлы с плотным индексом.В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура индексной записи в них имеет следующий вид:
Здесь значение ключа — это значение первичного ключа, а номер записи — это порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в них не может быть двух записей, имеющих одинаковые значения первичного ключа. В индексных файлах с плотным индексом для каждой
записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном пространстве.
где N — число элементов.
Однако в нашем случае является существенным только число обращений к диску при поиске записи по заданному значению первичного ключа. Поиск происходит в индексной области, где применяется двоичный алгоритм поиска индексной записи, а потом путем прямой адресации мы обращаемся к основной области уже по конкретному номеру записи. Для того чтобы оценить максимальное время доступа, нам надо определить количество обращений к диску для поиска произвольной записи.
На диске записи файлов хранятся в блоках. Размер блока определяется физическими особенностями дискового контроллера и операционной системой. В одном блоке могут размещаться несколько записей. Поэтому нам надо определить количество индексных блоков, которое потребуется для размещения всех требуемых индексных записей, а потому максимальное число обращений к диску будет равно двоичному логарифму от заданного числа блоков плюс единица. Зачем нужна единица? После поиска номера записи в индексной области мы должны еще обратиться к основной области файла. Поэтому формула для вычисления максимального времени доступа в количестве обращений к диску выглядит следующим образом:
Давайте рассмотрим конкретный пример и сравним время доступа при последовательном просмотре и при организации плотного индекса.
Допустим, что мы имеем следующие исходные данные:
Длина записи файла ( LZ ) — 128 байт. Длина первичного ключа ( LK ) — 12 байт. Количество записей в файле ( KZ ) — 100000. Размер блока ( LB ) — 1024 байт.
Рассчитаем размер индексной записи. Для представления целого числа в пределах 100000 нам потребуется 3 байта, можем считать, что у нас допустима только четная адресация, поэтому нам надо отвести 4 байта для хранения номера записи, тогда длина индексной записи будет равна сумме размера ключа и ссылки на номер записи, то есть:
Определим количество индексных блоков, которое требуется для обеспечения ссылок на заданное количество записей. Для этого сначала определим, сколько индексных записей может храниться в одном блоке:
Теперь определим необходимое количество индексных блоков:
Мы округлили в большую сторону, потому что пространство выделяется целыми блоками, и последний блок у нас будет заполнен не полностью.
А теперь мы уже можем вычислить максимальное количество обращений к диску при поиске произвольной записи:
Логарифм мы тоже округляем, так как считаем количество обращений, а оно должно быть целым числом.
Следовательно, для поиска произвольной записи по первичному ключу при организации плотного индекса потребуется не более 12 обращений к диску. А теперь оценим, какой выигрыш мы получаем, ведь организация индекса связана с дополнительными накладными расходами на его поддержку, поэтому такая организация может быть оправдана только в том случае, когда она действительно дает значительный выигрыш. Если бы мы не создавали индексное пространство, то при произвольном хранении записей в основной области нам бы в худшем случае было необходимо просмотреть все блоки, в которых хранится файл, временем просмотра записей внутри блока мы пренебрегаем, так как этот процесс происходит в оперативной памяти.
Количество блоков, которое необходимо для хранения всех 100 000 записей, мы определим по следующей формуле:
И это означает, что максимальное время доступа равно 12500 обращений к диску. Да, действительно, выигрыш существенный.
Рассмотрим, как осуществляются операции добавления и удаления новых записей.
При операции добавления осуществляется запись в конец основной области. В индексной области необходимо произвести занесение информации в конкретное место, чтобы не нарушать упорядоченности. Поэтому вся индексная область файла разбивается на блоки и при начальном заполнении в каждом блоке остается свободная область (процент расширения) (рис. 9.7):
После определения блока, в который должен быть занесен индекс, этот блок копируется в оперативную память, там он модифицируется путем вставки в нужное место новой записи (благо в оперативной памяти это делается на несколько порядков быстрее, чем на диске) и, измененный, записывается обратно на диск.
Определим максимальное количество обращений к диску, которое требуется при добавлении записи, — это количество обращений, необходимое для поиска записи плюс одно обращение для занесения измененного индексного блока и плюс одно обращение для занесения записи в основную область.
Естественно, в процессе добавления новых записей процент расширения постоянно уменьшается. Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны два решения: либо перестроить заново индексную область, либо организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную область записи. Однако первый способ потребует дополнительного времени на перестройку индексной области, а второй увеличит время на доступ к произвольной записи и потребует организации дополнительных ссылок в блоках на область переполнения.
Именно поэтому при проектировании физической базы данных так важно заранее как можно точнее определить объемы хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
При удалении записи возникает следующая последовательность действий: запись в основной области помечается как удаленная (отсутствующая), в индексной области соответствующий индекс уничтожается физически, то есть записи, следующие за удаленной записью, перемещаются на ее место и блок, в котором хранился данный индекс, заново записывается на диск. При этом количество обращений к диску для этой операции такое же, как и при добавлении новой записи.



