Контроль за информацией, или Три веселые буквы – DLP
Для начала небольшое введение, как и положено, скучное и формальное. Информация правит миром. Информация дороже золота. Какую бы еще избитую мысль привести, чтобы подтвердить тезис, в котором и так никто не сомневается?
Любая информация имеет особенность утекать. Причем обычно к конкурентам. Чтобы ваша информация оставалась при вас, ее надо защищать. Перечислим три основных способа защиты, посмотрим на плюсы и минусы. Ну а чтобы вы могли на равных разговаривать с вашим начальником службы ИТ-безопасности, добавим порцию умных слов, описывающих эти методы профессиональными терминами.
Первый способ. Можно построить стену, в стене прорубить калитку, у калитки поставить часового, и он будет совать нос в каждый документ, который пытаются вынести за пределы стены. Если документ похож на секретный, калитка захлопывается и вызывается начальник охраны.
Умные слова. Такой способ называется граничным DLP (Border DLP). Понятно, почему граничным: мы же запрещаем документам покидать границы нашей организации. Аббревиатура DLP расшифровывается как Data Leak Prevention – предотвращение утечек данных. Документы определяются как секретные либо по имени файла (способ простой, но ненадежный, ибо переименовать файл очень просто), либо по его содержимому. Вычисляется так называемая сигнатура – бинарная последовательность, которая будет уникальной для каждого исходного документа. Когда документ пытается покинуть пределы организации каким-либо путем – по сети, через USB-диск (флешку), по почте и так далее, определяется его сигнатура и сравнивается с базой защищаемых документов. Если сигнатура в базе найдена, операция блокируется, а ИТ-безопасность уведомляется.
Плюсы. Сделать такую систему достаточно просто, поэтому на рынке их много и стоят они относительно недорого.
Минусы. Не обязательно выносить документ из организации по сети или по почте. Есть и альтернативные способы. Во-первых, его можно прочитать и запомнить. Во-вторых, сделать снимок экрана и отправить по почте. В-третьих, сфотографировать документ, открытый на экране монитора. В-четвертых, вообще изменить документ, теперь он не будет совпадать с сигнатурой, а значит, система ничего не заметит.
Выводы. Стоит ли платить за такую систему – решайте сами. В качестве дополнения она, может, и сгодится. Проблема только в том, что зачастую две однотипные, но по-разному работающие системы имеют свойство конфликтовать.
Второй способ.Стену можно не строить (к чему такие строгости?), зато приставить к каждому работнику по сотруднику тайной службы, чтобы ходил следом да приглядывал, какие документы тот пытается прочитать. И только он захочет открыть запрещенный документ, как его хвать за рукав, секретный документ назад на полку, а нарушителя режима – куда следует.
Умные слова.Такой вариант DLP называется агентским (Agent DLP). На каждый компьютер в организации устанавливается агент, отслеживающий всякую попытку работы с любыми документами (открытие, копирование, удаление, печать и т. д.). При каждой такой попытке он вычисляет сигнатуру документа, сравнивает ее с базой сигнатур. Если документ защищен, определяется пользователь, пытающийся с ним работать, и есть ли у этого пользователя права на выполнение этой операции. Если права есть, операция выполняется, если нет, блокируется и уведомляется служба безопасности.
Плюсы. С помощью данного способа действительно можно эффективно защитить документы. Их невозможно будет даже открыть, а если нельзя открыть, то нельзя и ознакомиться с содержимым. Хотя, если основной задачей стоит именно запрет на открытие документов, здесь достаточно стандартного механизма разграничения прав доступа к файлам Windows.
Минусы. Как ни странно, тут их предостаточно. Во-первых, на каждом компьютере в сети работает агент, что отнюдь не сказывается положительно на общей производительности компьютера. Страдает также производительность сети, ведь каждый компьютер периодически обращается к базе сигнатур документов (нет, она, конечно же, сохраняется локально на компьютерах, но ведь ее надо периодически обновлять). Во-вторых, перед открытием, копированием, печатью каждого документа происходят вычисление его сигнатуры, сравнение и прочие действия, что в случае среднего компьютерного «железа» может обеспечить 1–5-секундные задержки (а то и больше) между запуском операции и ее выполнением. В-третьих, систему нужно настроить, указав все файлы, которые нужно защищать, и права доступа к ним для разных пользователей. Ну и наконец – деньги. Лицензия на каждый агент стоит недешево – 50–100 американских долларов, причем ближе к 100, чем к 50. При этом лицензию купить нужно на каждый компьютер, в противном случае можно сесть за незащищенную машину и получить доступ к файлам.
Выводы. Неплохой подход, если минусы для вас несущественны. Работает с любыми документами, но эффективен не во всех ситуациях.
Третий способ.Можно и стен не строить, и на соглядатаев не тратиться. Просто зашифровать документы. Что толку от документа, который прочесть невозможно? А хочешь прочесть, обратись в хранилище ключей, там твою личность проверят и дадут ключик. Но даже с ключиком ты не всесилен, если он не разрешает документ печатать или вносить в него изменения.
Умные слова.Каждая компания называет эту технологию по-разному. Но есть и общее название – DRM (Digital Rights Management), управление цифровыми правами. Данная технология реализуется путем встраивания механизма шифрования / дешифрации в стандартные программы для просмотра и редактирования документов. Для Microsoft это большинство программ, входящих в Office: Word, Excel, PowerPoint, Outlook; для Adobe – Acrobat и Acrobat Reader. Клиентская часть при попытке открытия документа обращается с информацией о документе и открывающем его пользователе к серверу ключей, который хранит сведения о правах различных пользователей на доступ к различным документам. Если право на доступ есть, отправляется ключ, с помощью которого клиент незаметно для пользователя расшифровывает документ и дает возможность выполнить разрешенные операции. То есть если в правах задано «Только просмотр», то напечатать документ уже не получится.
Плюсы. Защищенные письма в Outlook открываются заметно медленнее обычных, но в целом данная технология имеет хорошие показатели по скорости работы и мало нагружает компьютер и сеть.
Минусы. Я не зря сказал, что все компании называют эту технологию по-своему. Каждая компания еще и реализует эту технологию по-своему. Для защиты документов Microsoft Office используется программное обеспечение от Microsoft (причем желательно, чтобы Office был определенной версии), для защиты Adobe PDF – да, угадали, программное обеспечение от Adobe. Причем если захотите открыть документ с рабочего ноутбуку, который унесли домой, позаботьтесь, чтобы сервера были доступны извне вашей организации.
Вывод.Решение в целом неплохое, но весьма нишевое. Нужно в тех случаях, когда есть небольшое количество документов, которые надо защитить. Документы в едином формате, клиентское программное обеспечение одной и той же версии установлено у всех сотрудников, которые с этими документами будут работать (например, высшее руководство компании). Но для массового применения решение достаточно тяжелое и неэффективное.
Что такое DLP система?
DLP-система (от англ. Data Leak Prevention) это специализированное ПО, которое защищает организацию от утечек данных. Данная технология – это не только возможность блокировать передачу конфиденциальной информации по различным каналам, но и инструмент для наблюдения за ежедневной работой сотрудников, который позволяет найти слабые места в безопасности до наступления инцидента.
Зачем нужна DLP и как она работает?
Часто в компаниях больше внимание уделяют внешним угрозам: спаму и фишинг-атакам типа «отказ в обслуживании», вирусам (троянскому ПО, червям), подмене главных страниц интернет-ресурсов, шпионскому и рекламному программному обеспечению, социальному инжинирингу. Но на самом деле внутренние угрозы способны причинить компании куда более серьезный ущерб, чем злоумышленники за ее пределами.
В принципе любой работник компании может являться потенциальным инсайдером и поставить информационную безопасность под угрозу. От злого умысла или банальной оплошности не застрахован никто: от низшего звена и до топ-менеджмента.
Принцип работы DLP-системы прост и заключается в анализе всей информации: исходящей, входящей и циркулирующей внутри компании. Система при помощи алгоритмов анализирует, что это за информация и в случае, если она критичная и отправляется туда куда ей не положено — блокирует передачу и/или уведомляет об этом ответственного сотрудника.
Основа DLP — набор правил. Они могут быть любой сложности и касаться разных аспектов работы. Если кто-то их нарушает, то ответственные лица получают уведомление.
Так, например, в компании Х выявили сотрудника, который занимался майнингом криптовалют. Это было обнаружено при использовании модуля активности пользователей – отчёт показал, что рабочая станция не отключалась на ночь. После просмотра запущенных процессов выяснилось, что сотрудник перед уходом запускал процесс майнинга.
Система отслеживает не только время работы и активные программы на компьютере, но и любую другую работу с информацией, — ввод данных с клавиатуры, переписку и передачу файлов по почте, в соцсетях и мессенджерах, отправляемые на печать документы, время простоя, SIP-телефонию, активность на сайтах и многое другое.
Способы перехвата данных
Для того, чтобы анализировать данные — DLP-система сперва должна их получить.
Есть два основных способа перехвата — серверный и агентский. В первом случае система контролирует сетевой траффик на сервере, через который компьютеры «общаются» с внешним миром. Во втором случае специальные небольшие программы — агенты — устанавливаются на все компьютеры организации и передают с каждой машины данные для анализа.
Агентский перехват является более распространённым, ведь с его помощью можно получить гораздо больше данных из различных каналов коммуникации, а значит и надежнее предотвратить возможные утечки.
Нужна ли DLP вашей организации?
Если ответить кратко – да, конечно.
У каждой компании есть информация, которая имеет ценность, а значит притягивает злоумышленников, не только снаружи, но и изнутри. Это может быть клиентская база, особенности технологических процессов, чертежи, даже банальный список адресов для пресс-релиза несет ценность, которую не хочется просто так дарить конкурентам.
Как выбрать DLP?
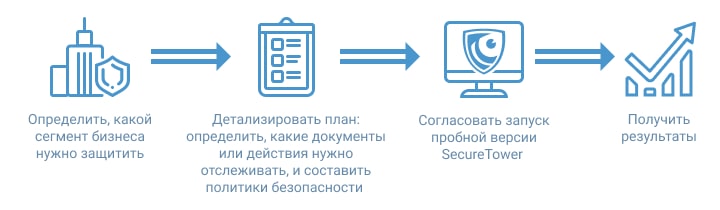
Если вы убедились, что система защиты данных вам необходима, возникает вопрос, как ее выбрать исходя из разнообразия, представленного на рынке. Для начала задайте себе несколько вопросов:
Какие каналы передачи информации она должна контролировать
Будет ли использоваться система в расследованиях или работать только на перехват
Какой бюджет и оборудование будут выделены на систему
Чтобы максимально полно ответить на эти вопросы лучше всего запросить демо-версию продукта. Большинство разработчиков предоставляет DLP на некоторое время, чтобы вы могли посмотреть, как она работает. Во время тестового периода можно понять, насколько хорошо выбранный программный комплекс закрывает задачи, а также сравнить с другими.
DLP-системы и законодательство
Сама DLP-система, а также процедура ее внедрения при правильном исполнении соответствует требованиям законодательства. Достаточно отметить, что система мониторит исключительно рабочий процесс, а не частную жизнь человека.
Неочевидные способы использования DLP-системы
Казалось бы, система, созданная для контроля утечки данных, больше ничем не может быть полезна. Однако современные DLP имеют и другие возможности, неочевидные на первый взгляд.
• Анализ загруженности персонала
Многие DLP-системы способны вести учет рабочего времени сотрудников. Рабочий процесс каждого пользователя можно представить в виде статистики, которая позволяет проанализировать, насколько сотрудник вовлечен в трудовой процесс.
• Обеспечение юридической поддержки
Задача DLP состоит не только в том, чтобы предотвратить утечки, но еще и при наличии судебного разбирательства, предоставить доказательства злоумышленной деятельности.
• DLP как инструмент мотивации
Когда сотрудники осознают, что их трудовая деятельность находится под мониторингом, появляется большая ответственность за рабочий процесс. И это в свою очередь приводит к улучшению климата в коллективе.
DLP-технология гарантирует сохранность всей информации, поскольку содержит в своём архиве все коммуникации сотрудников, к которым в случае необходимости можно будет обратиться.
Что такое DLP-система, как она видит ваши данные и почему они – кладезь информации для управления бизнесом
DLP-системы (Data Leakage Prevention) давно используются не только для защиты от утечек данных. Экспансивное развитие технологий сменилось интенсивным. DLP начали расти вглубь, улучшая качество анализа и перехвата контента. Благодаря этому данные из DLP становятся бесценны для принятия любых управленческих решений. Это позволяет превратить информационную безопасность в сервис для других подразделений компании — от HR до экономической безопасности
Зачем анализировать данные
Первая задача, которую призван решить анализ данных, – это предотвращение утечек. Без технологий анализа утечки тоже можно предотвращать, но придётся применять слишком много административных мер и по сути всем всё запретить (это способы низкобюджетной безопасности, мы писали о них здесь). Если компания достаточно большая, это может навредить бизнес-процессам. Мы этого не хотим! Поэтому нужно блокировать данные избирательно, а выбирать, что блокировать и для какого пользователя, помогают технологии анализа.
Вторая задача – разметка перехваченного архива. Архив перехвата без разметки – это большая куча данных, работать с которой можно только с помощью полнотекстового поиска, но и он не всегда помогает. Яркий пример – это нормальная форма в текстовых объектах InfoWatch Traffic Monitor. Например, у вас есть номер кредитной карты из 16 цифр. Этот номер в переписке может быть записан в любом формате: все цифры слитно, группы по 4 цифры с различными разделителями и т.д. Полнотекстовым поиском в архиве перехвата такой номер карты найти практически невозможно. Но тут на помощь приходит нормальная форма. В Traffic Monitor есть текстовый объект «Кредитная карта», который отлавливает кредитки вне зависимости от форматирования. После чего выделяет нормальную форму, снимая любое форматирование. Нормальная форма сохраняется в базе данных (БД) с привязкой к перехваченному объекту. Далее при поиске номер карты можно задать в любом формате, от неё также будет получена нормальная форма и уже по ней будет произведён поиск.
Анализ цепочек событий
Ещё одно применение разметки архива событий – это анализ цепочек событий. На основе такого анализа появляются продукты класса UBA (User Behavior Analytics), например, InfoWatch Prediction. Они анализируют поведение пользователя – тот набор событий в информационной среде, который пользователь генерирует. Хорошо размеченные события показывают, что же на самом деле делает пользователь: от нарушения различных политик безопасности до анализа обычных жизненных ситуаций. Отправка резюме, посещение сайта поиска работы или сайта оценки работодателей – система выстраивает подобные события в цепочку и помогает понять, есть ли вероятность увольнения. А, может быть, кто-то из сотрудников аффилирован с компанией-подрядчиком? InfoWatch Prediction умеет выявлять и такие риски. Как это работает? Можно искать аномалии в поведении, направленные аномалии – такие, как аномальное количество скопированных файлов, говорящее о накоплении информации для будущего слива. Можно отслеживать цепочки событий, применять Machine Learning и прогнозировать риски, можно искать сбои и «затыки» в бизнес-процессах и вовремя корректировать их с пользой для бизнеса. InfoWatch Prediction сейчас развивается в этом направлении.
Какие данные бывают в компании
В современном мире очень много способов представить данные. Это оправдано и помогает улучшать качество программных продуктов. Например, архивы помогают сэкономить время пересылки и место для хранения информации. Офисные форматы хранят текст, изображения, разметку текста и другую метаинформацию в одном файле. Быстро к этой информации доступ получить затруднительно, нужно знать формат хранения данных. А ИБ – это область быстрого реагирования. Поэтому в DLP-системе существует богатый набор экстракторов. Их задача получить примитивы информации из всех поддерживаемых в компании форматов (текст, изображения, векторная графика и др.).
Разумеется, текст – самый простой и удобный для анализа примитив информации. Даже изображения DLP-системы стараются привести к тексту с помощью технологии OCR (Optical Character Recognition). С изображениями работают современные методы computer vision, в т.ч. нейронные сети, которые уже могут много «рассказать» об изображении. Надеемся, в будущем технологии разовьются до такой степени, что можно будет получить полнотекстовое описание изображения (такие наработки есть уже сейчас). Не так давно из разряда бинарных в отдельный примитив информации перешли векторные изображения, т.к. мы научились их анализировать как структурированные данные.
Анализировать данные можно в трёх направлениях: смысловом, формальном и содержательном. Для смыслового поиска информации обычно используется классификатор. Данный подход позволяет при утечке из перехваченной информации извлечь тематику, не имея точного образца для поиска. При формальном анализе интересует в первую очередь то, как информация оформлена, и уже во вторую, чем она является. Яркий пример такого анализа – регулярные выражения. А вот поиском по образцу как раз и занимаются содержательные виды анализа. Для их работы необходимо иметь эталон или несколько эталонов, с которыми и сравнивается анализируемая информация.
Какие есть технологии анализа
Классификация может быть применена к данным с признаками, по которым мы можем определять некие группы или тематики данных. Довольно долго классификация не применялась к изображениям, но computer vision и увеличение вычислительных мощностей позволили классифицировать и этот вид данных. Вообще, основные критерии при создании технологий – это, конечно, максимум качества за минимум времени работы. При анализе данных «на лету» важно делать это быстро, иначе ИБ-специалист узнает о нарушении слишком поздно. DLP-система перехватывает миллионы событий ежедневно. Задержки при анализе такого огромного количества перехваченных объектов могут быть критичны для бизнеса. В нашей практике были случаи, когда в ходе пилотного внедрения DLP прямо на одной из встреч с заказчиком специалист по безопасности получил уведомление об утечке критичных данных и буквально сорвался с места, чтобы заняться этим инцидентом.
Для работы классификатора необходима обучающая коллекция. Это должна быть размеченная коллекция, т.е. каждый документ в ней должен быть отнесён к одному из представленных классов. Самая простая аналогия – это директории с документами на жёстком диске. Далее из представленных документов выделяются признаки (ключевые точки для изображений и термины для текстов), которые с привязкой к категориям отправляются в математическое ядро, а оно обучается на их основе. После того, как классификатор обучен, в него можно подавать документы. Процесс анализа схож с обучением. После перехвата из документа извлекаются признаки и подаются в математическое ядро для классификации, в результате работы классификатор возвращает принадлежность анализируемых данных к одной или нескольким категориям. Заранее настроить классификатор для любой компании чаще всего не представляется возможным. Даже одна и та же тематика у компаний, работающих на одном рынке, может выражаться разными наборами терминов. Поэтому при установке DLP производится тонкая настройка классификаторов для повышения качества их работы. В процессе эксплуатации необходимо так же понадобится донастройка классификаторов, т.к. меняются категории или их признаки.
Например, при настройке DLP в отделе кадров было старое, «больное» МФУ. Категория «Паспорт РФ» была дообучена на сканах с этого МФУ. Через полгода в отделе кадров появилось новое модное МФУ с очень высоким качеством сканирования. С его сканов стали снимать больше ключевых точек, плюс перераспределились старые, а также не стало царапин на стекле сканера, которые давали ключевые точки. В такой ситуации качество классификации упадет, хотя и не критично. Однако этому можно противостоять, дообучив классификатор – предъявив ему новые примеры отсканированных паспортов.
Кроме изображений мы классифицируем и тексты. Для классификации текстов можно использовать много подходов из машинного обучения, InfoWatch использует два: косинусную меру (т.н. БКФ — База Контентной Фильтрации) и логистическую регрессию, с применением которой у нас скоро выйдет очередной релиз. Для текста признаками являются слова. Слова практически в любом языке имеют формы, при этом конечный смысл текста, в котором эти формы используются, меняется не радикально. Поэтому, в наших классификаторах используется морфология слова. Мы используем морфологические словари для нескольких языков (сейчас их 18), приводя все слова к нормальной форме, что помогает повысить качество классификации. Для тех языков, для которых у нас нет словарей, классификаторы работают на точное совпадение. Для поднятия точности есть еще технология исправления опечаток, которая выделенные слова сравнивает с известными терминами и может исправить одну опечатку.
Для формального анализа используются регулярные выражения, в Traffic Monitor они представлены в технологии текстовые объекты.
Данный вид анализа можно описать как поиск кусков эталонов в анализируемых данных. В InfoWatch Traffic Monitor таких анализов несколько. Все они работают по схожим принципам: в систему загружаются эталонные документы, которых может быть много. В нашей практике был заказчик, который загрузил в качестве эталонов все свои документы, и их было около 90 000! Дальше каждый перехваченный кусок информации сравнивается с эталоном. Каждый анализ решает свою задачу и обычно работает только с одним примитивом данных.
Есть классический копирайтный анализ для текстов. В качестве эталонов он принимает текст (так или иначе извлечённый из разных форматов) и анализирует только текстовые примитивы. В результате DLP-система видит релевантность, т.е. сколько процентов эталона содержит анализируемый документ и разметку этих кусков, это позволяет подсветить их в интерфейсе пользователя. Копирайтный анализ для бинарных данных работает по тем же принципам, но возвращает только релевантность. Поскольку возможности данной технологии все же ограничены, мы решили пойти дальше в их развитии.
Для растровых графических данных тоже есть копирайтный анализ. При создании данной технологии анализа мы искали золотую середину между скоростью и функциональными возможностями. В итоге у нас получилось сделать алгоритм, сравнимый по скорости с текстовым копирайтным анализом (в т.ч. получилось избавиться от зависимости скорости анализа и количества эталонных изображений, что для компьютерного зрения редкость), не зависящий от формата и разрешения изображения, но зависящий от ориентации. Т.е. мы не могли детектировать, например, повёрнутое на 90 градусов изображение. Но из этой ситуации нашелся выход. Так как мы практически не зависим от числа эталонов, то в эталоны можем добавить все варианты поворота эталонного изображения.
Следующий копирайтный анализ был реализован для векторных изображений. Здесь мы выделяем графические примитивы и смотрим на их взаимное расположение в эталоне, что позволяет перехватывать в том числе и куски векторных изображений.
Далее коротко о специализированных видах копирайтного анализа. Они были созданы для решения узких, но очень частых задач заказчиков. Например, детектор эталонных бланков. Его цель детектировать заполненные анкеты. В качестве эталона подаются пустые анкеты, алгоритм снимает поля формы. При этом надо понимать, что полем эталонной формы считается кусок текста, в конце которого находится один из заданных разделителей: перевод строки, три пробела, три подчёркивания. Разделители можно дополнять в недрах системы для более точной настройки. В итоге полями формы считаются не только настоящие поля, но и обрамляющий анкету текст. Далее при анализе из текстового примитива выделяются поля, которые совпадают с полями эталонной анкеты, затем проверяется их порядок, и в конце мы смотрим, а есть ли какие-то символы между полями. И если символы есть, то мы считаем поле заполненным. Дальше считаем количество найденных полей и их позиции в анализируемом тексте, а также количество заполненных полей. Незаменимая вещь для компаний, для которых анкетные данные – один из главных цифровых активов бизнеса.
Еще один специализированный вид – анализ выгрузок из БД. Почему именно выгрузки, а не сами базы данных? Ответ лежит в области видимости информации и её представлении. Видимость данных – это про то, кто какую информацию видит. Доступ непосредственно к БД обычно есть только у администраторов. Во-первых, их обычно не так много, а, во-вторых, с ними можно бороться и административными методами. Большинство же пользователей сами базы данных никогда не видели и не увидят, потому что работают в программах, которые собственно и делают некие выгрузки из БД, с результатами выполнения SQL-запросов. И теперь мы плавно переходим к представлению информации. Зачастую, в БД информация не хранится в прямом виде: та же зарплата может быть разбита на количество отработанных часов, часовой ставки или процент надбавки и т.д. А бухгалтер видит табличку «ФИО, зарплата». И, скорее всего, именно в таком виде данные будут утекать. Поэтому, если бы мы начали защищать именно БД, то нам в любом случае пришлось бы как-то понимать, в каком виде информация из неё доходит до конечного пользователя. К тому же в БД хранится ещё очень много вспомогательной информации, которая вряд ли встретится в потоке. Умножьте это все на большое разнообразие баз данных, на их структуру и т.д.
Еще буквально пару слов про технологии, и переходим к выводам
Немаловажный фактор корректной работы DLP с выгрузками – условия срабатывания. Это про то, какая информация из выгрузки должна встретиться в анализируемых данных. Например: выгрузка должна сработать, когда будет найдено 10 и более строк, содержащих данные из столбцов № 1, 2 и 3. Условий срабатывания может быть несколько, они все имеют уникальное имя, поэтому можно настроить разную реакцию системы на них. Для кого-то это более критично, для кого-то менее.
Осталось два копирайтных анализа, и они оба графические. Первый – это детектор эталонных печатей. Позволяет в качестве эталонов задать круглые или треугольные печати и в дальнейшем ищет их в анализируемых изображениях, т.е. задача на скане или фото листа А4 найти эталонную печать.
Второй, имеет название «поиск картинки в картинке», широкой же публике известен как детектор кредитных карт. Если смотреть широко на данную технологию, то она в качестве эталона принимает изображение и затем пытается найти его на всех анализируемых изображениях. Узкое применение – поиск логотипов платёжных систем. В InfoWatch Traffic Monitor эта технология представлена графическим объектом «Кредитная карта». В широкое применение мы не выпускаем данную технологию, т.к. скорость её работы зависит от количества эталонных документов, в то время как скорость работы технологий, описанных выше, практически не деградирует из-за добавления в них большого количества эталонных документов. Естественно, оперативная память от этого страдает, но её можно докупить, в отличие от времени. Наверное, будет лишним пояснять, насколько эффективна эта технология против воровства данных платежных карт, которыми хотят завладеть слишком многие.
Как видите, DLP – сложные системы с широкими возможностями, и успешность их эксплуатации во многом зависит от того, насколько грамотно вендор произвел тонкие настройки у заказчика. Рынку DLP-решений уже около 20 лет. Он считается сформированным, и иногда можно услышать мнение, что отрасль DLP зашла в тупик. Но это далеко не так. Задачи заказчиков постоянно эволюционируют, меняются каналы передачи, тематики, документы и данные, которые нужно защищать и др.
Чего стоил один массовый переход на удаленку в этом году и необходимость обеспечивать кибербезопасность и защиту от утечек в условиях удаленной работы. Реальные нарушения, критичные для непрерывности бизнеса и поддержания его эффективности, как правило, лежат на периферии. С помощью технологий можно анализировать взаимодействие с партнерами или конкурентами, строить графы связей, выявлять подозрительные паттерны или просто паттерны, определять группы неформальных лидеров, вовремя и грамотно реагировать на риски и др.
За эти годы технологии анализа в DLP сделали прорыв. Из них вырастают новые сервисы, которые способны решать широкий спектр бизнес-задач, выходящих далеко за пределы информационной безопасности. Подробнее о технологиях анализа и бизнес-задачах, которые не относятся напрямую к ИБ, но решаются с помощью DLP, мы рассказывали на вебинаре «Ваши данные глазами DLP». Его можно посмотреть в записи здесь.
Автор Сергей Рябов, руководитель группы научно-исследовательской разработки ГК InfoWatch



