Байесовское машинное обучение
Что даёт Байесовский подход
Бейсовский подход — это наиболее академичный взгляд на машинное обучение. Это и хорошо и плохо.
Хорошо тем, что даёт чёткое математическое описание обучения и численные оценки достоверности гипотез. Тогда как обычные подходы, чаще всего, выдают только одну гипотезу, как достоверную. Например, в результате обучения получается вполне определённая нейронная сеть (набор весов). И у нас нет надёжной оценки того, на сколько эта сеть лучше какой-либо другой. Мы даже не можем сказать, действительно ли она — лучшая.
Плохо тем, что в реальной жизни не всегда можно реализовать безупречную математическую модель. Но с помощью математической модели всё равно можно получить определённую оценку качества обучения.
Обобщённый взгляд на машинное обучение
На самом деле, любые подходы к машинному обучению делают одно и тоже. У нас всегда есть две основных вещи:
Во-вервых, это набор гипотез. Это может быть набор функций, или набор весов для нейронов нейронной сети, или набор всевозможных решающих деревьев… Что угодно. Зависит от конкретного подхода.
Во-вторых, у нас есть набор обучающих данных.
Наша задача всегда сводится к одному: определить, какая же из наших моделей наиболее адекватна нашим обучающим данным.
Байесовский подход даёт точный численный критерий для решения этой задачи.
Классическая вероятность
С классической вероятностью мы часто имеем дело в физических и инженерных задачах. Тут всё просто, надо поставить много экспериментов и поделить количество «успехов» на количество экспериментов.
Это частотное понимание вероятности.
Скажем, если вы бросили монетку 100 раз и 49 раз выпал «орёл», то можно говорить, что вероятность выпадания «орла» близка к 49% (чем больше экспериментов, тем точнее мы оценим вероятность).
То есть тут у нас есть модель и мы хотим подсчитать вероятность какого-либо исхода. Это прямая задача.
Модель «монетка» очень проста: у неё две стороны и она не может встать на ребро.
Но в компьютерном обучении чаще встречаются совсем другие задачи: когда вы не знаете модель и по известному поведению надо построить модель. Вернее, строго говоря, определить, какая из моделей наиболее вероятна, так как точно ответить вы обычно не можете.
Но, давайте обо всём по-порядку.
Пример обратной задачи со скрытой переменной и вероятностный подход к моделям
Чтобы показать, как это работает, давайте просто рассмотрим конкретную задачу.
Пусть у нас есть корзина с яблоками. Яблоки бывают красные и зелёные. Мы берём из корзины N яблок и видим R красных яблок и G зелёных. Естественно, R+G=N.
Конечно, этот наш опыт может быть повторен несколько раз. Но давайте ограничимся одним. Это упростит наши рассуждения и совсем не ограничит общность изложения.
Теперь мы хотим узнать, каков процент зелёных яблок, а каков красных. В корзине.
Переведём это на язык машинного обучения: у нас есть
А в терминах Байесовского подхода, мы должны теперь рассчитать вероятности получения наших обучающих данных при условии реализации каждой гипотезы. Гипотеза, которая окажется наиболее вероятной и победит в битве гипотез.
Это ключевая идея всего подхода. Остальное — детали.
Теорема Байеса
Теорема Байеса очень проста. Она является очевидным тождеством, однако, это не умаляет её важность.
Теорема Байеса является следствием очевидного утверждения
Естественно p(b) должно быть больше 0, но это и понятно, если b является невероятным событием, то и p(a|b) тоже невероятно.
Применим теорему Байеса к машинному обучению
Давайте обозначим наши данные — D, а наши гипотезы — h. Тогда нам надо найти вероятность гипотезы для наших данных p(h|D), которая по теореме Байеса равна:
Нас интересует только соотношение вероятностей, поэтому мы можем выкинуть из этого выражения p(D) (D не зависит от h) и p(h) (будем считать, что все гипотезы равновероятны; строго говоря, это не всегда так, мы ещё вернёмся к этому вопросу, но во многих случаях это справедливо).
Получается, что нам надо найти такую гипотезу h, для которой максимально p(D|h).
Говоря математическим языком, мы должны для каждой гипотезы вычислить её апостериорную вероятность и выбрать гипотезу, для которой эта вероятность максимальна.
Этот подход называется maximum a posteriori probability (MAP). Если строго следовать ему, то вы получите лучшую гипотезу. И это математически доказано.
К сожалению, полное следование MAP возможно далеко не всегда. Например, данных слишком много. Или решение надо дать быстро. Поэтому, в реальной жизни используются различные модификации MAP, но мы не будем в это вдаваться.
Вернёмся к нашему примеру
Пока у нас нет ни конкретных данных, ни множества гипотез. Давайте же придумаем их.
Пусть мы вынули N=3 яблок: R=1 красных и G=2 зелёных.
Давайте выдвинем две гипотезы:
Теперь нам просто надо рассчитать, какова вероятность получения наших данных в каждой их этих гипотез.
Немного комбинаторики
Обозначим количество красных и зелёных яблок в корзине: R₀ и G₀. Сколькими способами можно взять R яблок из R₀?
Это, знакомый многим, биномиальный коэффициент. То есть, если у нас есть 3 яблока, то мы можем вынуть из них 2 яблока тремя способами: ●●○, ●○●, ○●●. С(3,2)=3!/(1!·2!)=(1·2·3)/((1)·(1·2))=3. Если вы не знакомы с этой формулой — ничего страшного. Она не относится к Байсовскому подходу, а нужна лишь для решения нашей конкретной задачм.
Искомая вероятность тогда равна
Осталось применить это к нашим гипотезам:
Видно, что побеждает первая гипотеза.
Расширяем набор гипотез: переобученность
Давайте не будем ограничиваться двумя гипотезами. Рассмотрим любые сочетания R₀ и G₀. (R и G оставим прежними).
У нас получится табличка:
Здесь видны даже две проблемы.
Меньшая: многие гипотезы имеют одинаковую вероятность (например (R₀=1, G₀=5) и (R₀=2 и G₀=5)). На больших данных этой проблемы обычно нет.
Но самая большая проблема: мы получили, что наилучшее решение — (R₀=1, G₀=2). Это решение столько же точно, сколь и бесполезно.
То есть машина нам сказала: раз вы вынули из корзины одно красное яблока и два зелёных, то, скорее всего, там и были одно красное и два зелёных.
Это действительно так. При этом раскладе у вас просто нет шанса вытащить из корзины что-то другое.
Машина права. Но нужен ли нам такой ответ? Очевидно, это не то, что мы ожидали.
Это и есть переобученность. Наш искусственный интеллект «зазубрил» обучающие данные. Скорее всего, он не в состоянии качественно решать задачи, но на все обучающие вопросы он безупречно выдаёт точный обучающий ответ.
Происходит это по двум основным причинам:
Первая, — у нас очень мало обучающих данных. Увеличение обучающего массива может дать положительный результат. Но этот ресурс не бесконечен. При достижении определённого размера, дальнейшее наращивание становится бессмысленным. Начинают играть роль шумы или просто неоднородность условий, при которых были собраны данные (ведь в реальной жизни ничто не вечно).
Вторая, — мы выбрали слишком широкий спектр гипотез. Мы решили, что возможно всё.
Мы можем сузить спектр гипотез. Фактически, это есть p(h), которую мы выкинули в начале. Чтобы сделать цифры наглядней, я не буду здесь использовать именно вероятность, но фактически, я сделаю именно этот учёт.
Допустим, мы откуда-то знаем, что в корзине можем быть только 6, 7 или 8 яблок. Вероятность других гипотез — 0. Тогда наша табличка принимает вид:
Видно, что при этом условии выигрывает гипотеза (R₀=2, G₀=4). Так же видно, что (R₀=2, G₀=5) лишь чуть менее правдоподобна.
Это уже неплохой результат!
Подводные камни MAP-обучения
Итак, казалось бы, у нас есть универсальный и математически точный инструмент выбора гипотезы, то есть, — машинного обучения. Необходимо минимальное человеческое вмешательство чтобы выбрать правдоподобный спектр гипотез, а дальше машина сделает оптимальный выбор.
На самом деле, всё не совсем так радужно.
Обозначу только самые фундаментальные проблемы.
Во-первых. Честное Байесовское обучение предполагает, что вы вычислите вероятности всех возможных гипотез для всех обучающих данных. То есть, если у вас 1000 гипотез и 1000 обучающих патернов, то вам придётся рассчитать 1000000 апостериорых вероятностей. В реальной жизни, обычно, числа больше на порядки. Выполнить полный рассчёт просто невозможно.
Тут есть разные подходы. В некоторых случая можно доказать, что полный перебор не нужен, и действовать более направленно. В большинстве же случаев применяют различные статистические методы. Или приближённые методы. Даже самые грубые упрощения (так называемый наивный байесовский классификатор или idiot Bayes model) позволяют создать очень неплохие спам фильтры и другие системы классификации.
Вторая важная проблема возникает при создании классификаторов на основе Байесовского обучения. Не вдаваясь в математику рассмотрим простой пример. Мы хотим решить: мужчина перед нами, или женщина. У нас есть 4 гипотезы. Их вероятности распределяются так:
Если мы выберем MAP-гипотезу, то это будет h₄. И она скажет нам, что перед нами мужчина. Однако, сумма остальных гипотез — 0.6, что больше, чем 0.4. То есть, следовало бы ответить, что перед нами женщина.
Проблема не в том, что Байесовсое обучение плохо. Просто в данном случае мы должны рассматривать не отдельные гипотезы, а все возможные сочетание гипотез. Тогда мы получим идеальный Байесовский классификатор. Основная его проблема даже не в том, как его получить, а уже в том, как его использовать. Ведь даже имея идеальный классификатор, чтобы им воспользоваться вам надо вычислить некую идеальную комбинацию всех гипотез! На помощь приходят различные статистические подходы. Такие как классификатор Гиббса.
Но обо всех этих вещах я, возможно, напишу отдельно.
Наивный байесовский в машинном обучении
Дата публикации Nov 6, 2017
Теорема Байеса находит много применений в теории вероятностей и статистике. Существует небольшой шанс, что вы никогда не слышали об этой теореме в своей жизни. Оказывается, эта теорема нашла свой путь в мир машинного обучения, чтобы сформировать один из высоко украшенных алгоритмов. В этой статье мы узнаем все об Наивном алгоритме Байеса, а также о его вариациях для различных целей машинного обучения.
Как вы уже догадались, это требует от нас взглянуть на вещи с вероятностной точки зрения. Как и в случае машинного обучения, у нас есть атрибуты, переменные ответа и прогнозы или классификации. Используя этот алгоритм, мы будем иметь дело с распределениями вероятностей переменных в наборе данных и прогнозирования вероятности того, что переменная отклика будет принадлежать определенному значению с учетом атрибутов нового экземпляра. Начнем с рассмотрения теоремы Байеса.
Теорема Байеса
Это позволяет нам исследовать вероятность события на основе предшествующего знания любого события, связанного с предыдущим событием. Так, например, вероятность того, что цена дома высока, может быть лучше оценена, если мы знаем объекты вокруг нее, по сравнению с оценкой, сделанной без знания местоположения дома. Теорема Байеса делает именно это.

Выше уравнение дает основное представление теоремы Байеса. Здесь A и B два событияа также,
P (A | B): условная вероятность того, что событие A произойдет, учитывая, что B произошло. Это также известно как апостериорная вероятность.
P (A) и P (B): вероятность A и B без учета друг друга.
P (B | A): условная вероятность того, что событие B произойдет, учитывая, что A произошло.
Теперь давайте посмотрим, насколько это хорошо подходит для целей машинного обучения.
Возьмите простую задачу машинного обучения, где нам нужно изучить нашу модель из заданного набора атрибутов (в учебных примерах), а затем сформировать гипотезу или отношение к переменной ответа. Затем мы используем это отношение, чтобы предсказать ответ, учитывая атрибуты нового экземпляра.Используя теорему Байеса, можно построить учащегося, который предсказывает вероятность того, что переменная отклика принадлежит некоторому классу, учитывая новый набор атрибутов.
Р (А | В): условная вероятность того, что ответная переменная принадлежит определенному значению с учетом входных атрибутов.Это также известно как апостериорная вероятность.
Р (А):Априорная вероятность переменной ответа.
P (B): вероятность обучения данных или доказательств.
P (B | A): это известно как вероятность обучения данных.
Следовательно, вышеприведенное уравнение можно переписать как

Наивный байесовский алгоритм
Сложность вышеуказанного байесовского классификатора должна быть уменьшена, чтобы он был практичным.Наивный алгоритм Байеса делает это, делая допущение об условной независимости от обучающего набора данных.Это резко снижает сложность вышеупомянутой проблемы до 2n.
Предположение об условной независимости гласит, что для заданных случайных величин X, Y и Z мы говорим, что X условно не зависит от Y, заданного Z, тогда и только тогда, когда распределение вероятностей, управляющее X, не зависит от значения Y, заданного Z.
Другими словами, X и Y условно независимы, учитываяZесли и только если, учитывая, чтоZпроисходит, знание того,Икспроисходит не предоставляет информацию о вероятностиYпроисходит, и знание того,Yпроисходит не предоставляет информацию о вероятностиИкспроисходит.
Это предположение делает алгоритм Байеса наивным.
Учитывая, n различных значений атрибута, вероятность теперь можно записать как

Максимизация апостериори
Что нас интересует, так это нахождение апостериорной вероятности или P (Y | X) Теперь для нескольких значений Y нам нужно вычислить это выражение для каждого из них.
Для нового экземпляра Xnew нам нужно вычислить вероятность того, что Y примет любое заданное значение, учитывая наблюдаемые значения атрибута Xnew и учитывая распределения P (Y) и P (X | Y), оцененные по данным обучения.
Итак, как мы будем предсказывать класс переменной ответа, основываясь на различных значениях, которые мы достигаем для P (Y | X).Мы просто берем наиболее вероятные или максимальные из этих значений. Следовательно, эта процедура также известна как максимизация апостериори.
Максимизация вероятности
Если предположить, что переменная ответа равномерно распределенаТо есть с равной вероятностью получит любой ответ, тогда мы сможем еще больше упростить алгоритм. С этим предположением априори или P (Y) становится постоянным значением, которое составляет 1 / категории ответа.
Поскольку априорные данные и данные в настоящее время не зависят от переменной отклика, их можно удалить из уравнения. Следовательно, максимизация апостериорной сводится к максимизации проблемы правдоподобия.
Распределение функций
Как видно выше, нам нужно оценить распределение переменной отклика из обучающего набора или предположить равномерное распределение. По аналогии,Чтобы оценить параметры для распределения объекта, необходимо принять распределение или сгенерировать непараметрические модели для объектов из обучающего набора., Такие предположенияизвестные как модели событий, Различия в этих допущениях порождают разные алгоритмы для разных целей.Для непрерывных распределений гауссовский наивный байесовский алгоритм является алгоритмом выбора.Для дискретных функций, полиномиальные и Бернулли распределения как популярные, Подробное обсуждение этих вариаций выходит за рамки данной статьи.
Наивные байесовские классификаторы действительно хорошо работают в сложных ситуациях, несмотря на упрощенные предположения и наивность.Преимущество этих классификаторов состоит в том, что они требуют небольшого количества обучающих данных для оценки параметров, необходимых для классификации.Это алгоритм выбора для классификации текста.Это основная идея наивных байесовских классификаторов, что вам нужно начать экспериментировать с алгоритмом.
Если вам понравилась эта статья, обязательнопоказать свою поддержку, хлопаядля этой статьи ниже, и если у вас есть какие-либо вопросы,Оставить комментарийи я сделаю все возможное, чтобы ответить.
Для того, чтобы быть более осведомленным о мире машинного обучения,Подписывайтесь на меня, Это лучший способ узнать, когда я пишу больше подобных статей.
5 минут на машинное обучение

Теорема и наивный классификатор Байеса
Наивный классификатор Байеса — это набор простых и эффективных алгоритмов машинного обучения для решения различных задач классификации и регрессии. Эта статья может стать хорошим 5-минутным введением для тех, кто пропускал занятия по статистике, кому при слове «байесовский» становится некомфортно. На примере расчета вероятности посещения фитнес-зала я собираюсь в течение 5 минут объяснить теорему Байеса, а затем и алгоритм наивного классификатора Байеса. Кроме того, в моем GitHub есть пример простого кода на Python с использованием Scikit-learn. Итак, начинаем!
Краткое введение в теорему Байеса
Перед объяснением принципа работы алгоритма наивного классификатора Байеса, сначала следует разобраться с теоремой Байеса. В ее основе лежит условная вероятность (рис. 1). Фактически теорема Байеса — это всего лишь альтернативный или обратный способ вычисления условной вероятности (conditional probability). Когда сложно вычислить совместную вероятность P(A∩B) или легче вычислить обратную или байесовскую P(B | A), тогда можно применить теорему Байеса.
Теперь быстро определим отдельные термины из теоремы Байеса:
· Класс prior или априорная вероятность (prior probability): вероятность того, что событие А произойдет до того, как мы узнаем что-либо о событии В.
· Предварительный прогноз (Predictor prior) или обоснование: то же, что и предыдущий класс, но для события B.
· Апостериорная вероятность (Posterior probability): вероятность события A после получения информации о событии B.
· Возможность (Likelihood): обратная апостериорная вероятность.
В чем разница между теоремой и наивным классификатором Байеса?
Какое все это имеет отношение к наивному классификатору Байеса? Следует понимать, что различие между теоремой Байеса и наивным классификатором Байеса состоит в том, что наивный классификатор предполагает условную независимость, тогда как теорема Байеса ее не предполагает. Это означает, что между всеми входными свойствами классификатора нет взаимозависимости.
Возможно это не очень удачное предположение, но именно поэтому этот алгоритм называют «наивным» (naive). В этом также одна из причин ускоренной работы алгоритма. Несмотря на то, что алгоритм «наивен», он все же может превзойти сложные модели. Поэтому не позволяйте названию вводить вас в заблуждение.
Далее рассмотрим разницу в обозначениях между теоремой и наивным классификатором Байеса. Но сначала обратимся к одному из примеров использования теоремы Байеса, касающегося посещения тренажерного зала.
Пошаговое применение теоремы Байеса
Далее приведен простой пример, применимый для решения подобных задач. Администрация хочет получить прогноз посещаемости тренажерного зала с учетом погодных условий: P (присутствие = да | погода).
Шаг 1. Оценка ситуации или сбор исходных данных
У нас есть данные, где каждая строка представляет собой посещаемость тренажерного зала с учетом погоды. Так, наблюдение 3 — это участник, который посещал тренажерный зал в пасмурную погоду.
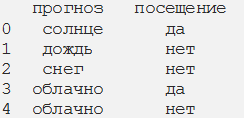
Шаг 2. Преобразуем набор данных в таблицу частотности
При этом мы получим суммарную посещаемость, исходя из погодных условий.
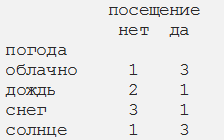
Шаг 3. Суммирование по строкам и столбцам для получения вероятностей

Если посмотреть на априорную вероятность класса (вероятность посещения), в среднем вероятность посещения тренажерного зала составляет 53%. К сведению, это типичное значение для большинства тренажерных залов: часто люди записываются, но ходят не регулярно. Однако задача заключается в получении вероятности посещения тренажерного зала с учетом погодных условий.
Шаг 5. Применение вероятностей из таблицы частотности к теореме Байеса
На рисунке 2 показана наша задача в представлении теоремы Байеса. Присвоим каждой из вероятностей на этом рисунке значение из приведенной выше таблицы частотности, а потом запишем уравнение так, чтобы оно стало более понятным.
Возможность (Likelihood): P (солнце | да) = 3/8 или 0,375 (общее количество солнца И да, деленное на общее количество да)
Априорная вероятность класса: P (да) = 8/15 или 0,533
Априорная вероятность предиктора: P(солнце) = 4/15 или 0,267
Согласно рисунку 3, любой участник посещает спортзал с вероятностью 75%, если будет солнечная погода. Это значение превышает среднюю посещаемость 53%! С другой стороны, вероятность посещения тренажерного зала в снежную погоду составляет всего 25% (0,125 ⋅ 0,533 / 0,267).
Поскольку этот пример из двоичной логики (посещать или не посещать), а P (да | солнечно) = 0,75 или 75 %, то обратное значение P (нет | солнечно) равно 0,25 или 25 %, так как сумма вероятностей должна составлять 1 или 100 %.
Вот так следует использовать теорему Байеса, чтобы найти апостериорную вероятность для систематизации. Алгоритм наивного классификатора Байеса похож на показанный далее пример. Следует обратить внимание на одну очевидную проблему в этом примере. Она заключается в том, что для погодных условий мы применяем одинаковую вероятность ко всем участникам, что не совсем логично. Но это был просто занимательный пример. Теперь обсудим дополнительные свойства и использование наивного классификатора Байеса.
Использование наивного классификатора Байеса с множеством свойств
Почти во всех случаях у вас в модели будет несколько свойств (features). Примерами свойств для тренажерного зала могут быть: возраст, тип членства, пол и т. д. Рассмотрим, как включить эти свойства в теорему и в наивный классификатор Байеса.
На рисунке 4 показана теорема Байеса, упрощенная до наивного алгоритма Байеса, включающего несколько свойств. В теореме Байеса вы должны вычислить единую условную вероятность с учетом всех свойств (вверху). С помощью наивного классификатора Байеса мы все упрощаем, вычисляя для каждого свойства условную вероятность, а затем перемножая их. Именно поэтому он и называется «наивным», поскольку условные вероятности всех свойств вычисляются независимо друг от друга. Алгоритм наивного классификатора Байеса серьезно упрощается за счет независимости и отбрасывания знаменателя. Вы можете повторить описанные выше шаги из теоремы Байеса, чтобы применить эти, теперь уже простые вычисления и, следовательно, корреляцию между теоремой и наивным классификатором Байеса.
Заключение
В этом коротком 5-минутном введении в теорему и наивный классификатор Байеса использован пример с прогнозированием посещаемости тренажерного зала с помощью теоремы Байеса. Мы выяснили разницу между теоремой и наивным классификатором Байеса, показали упрощенные обозначения и объяснение “наивности” через предположение о независимости. К этому можно еще много чего добавить, но, надеюсь, что все изложенное дает базовое понимание теоремы и наивного алгоритма Байеса и позволит включать последний в ваши новые проекты.



