Архитектура кластера
Основные возможности кластера серверов
Общая схема клиент-серверного варианта работы
В клиент-серверном варианте работы клиентское приложение взаимодействует с кластером серверов, который, в свою очередь, осуществляет взаимодействие с сервером баз данных.
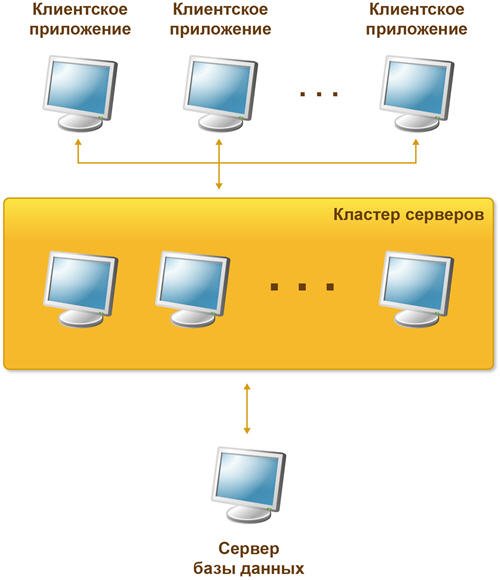
Один из компьютеров, входящих в состав кластера серверов, является центральным сервером кластера. Центральный сервер, помимо обслуживания клиентских соединений, управляет работой всего кластера и хранит реестр кластера.
Для клиентского соединения кластер адресуется по имени центрального сервера и номеру сетевого порта. Если используется стандартный сетевой порт, то достаточно указания одного имени центрального сервера.
При установке соединения клиентское приложение обращается к центральному серверу кластера. Центральный сервер, на основе анализа статистики загруженности рабочих процессов, направляет клиентское приложение к конкретному рабочему процессу, который будет его обслуживать. Этот процесс может находиться как на центральном сервере, так и на любом рабочем сервере кластера.
Рабочий процесс выполняет аутентификацию пользователя и обслуживает соединение до окончания сеанса работы клиента с данной информационной базой.
Состав простейшего кластера серверов
Простейший кластер серверов может располагаться на одном компьютере и содержать один рабочий процесс:
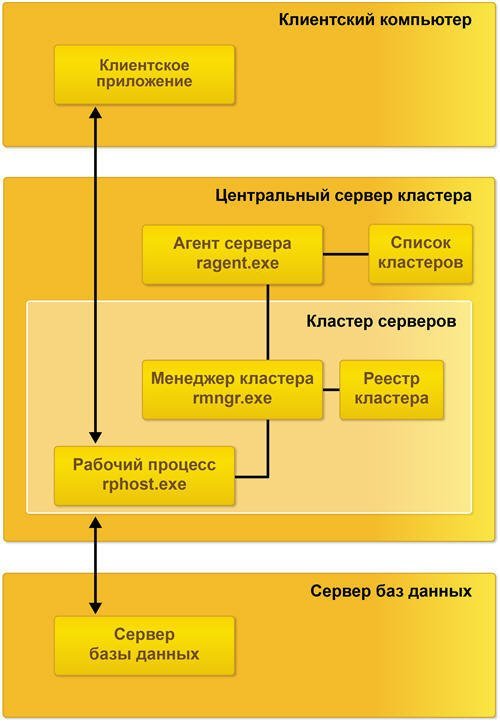
Функционирование компьютера в составе кластера обеспечивается процессом ragent.exe, который называется агентом сервера. Соответственно компьютер, на котором запущен агент сервера, называется рабочим сервером. Одной из функций агента сервера является ведение списка кластеров, расположенных на данном рабочем сервере.
Агент сервера и список кластеров не входят в состав кластера серверов, а лишь обеспечивают работу сервера и кластеров, которые расположены на нем.
Создание кластера серверов 1C

Когда в компании ПО от 1С использует всего несколько человек, достаточно одного хорошего и правильно настроенного сервера для комфортной работы. А если количество пользователей больше сотни, стоит предпринять меры по снижению нагрузки на оборудование. И в этом поможет кластер.
Когда требуется создание кластера серверов 1C? В тех случаях, когда нужно решить любую из этих проблем:
Для установки кластера серверов не нужно разбираться в принципах работы серверного оборудования. Благодаря нашей инструкции создание кластера станет простейшей процедурой. Проверить эффективность работы кластера вы можете с помощью теста Гилёва, но он полезен далеко не во всех случаях.
Итак, как создать кластер серверов 1C? Рассказываем на примере версии 1C:8.3.
Шаг 1. Создаём центральный сервер
В кластер 1С можно добавить минимум два сервера приложений. Предположим, что у нас нет ни одного. Давайте создадим кластер из двух серверов 1C. Для этого заходим в консоль администрирования 1C:8.3, находим там Central 1C:Enterprise 8.3 server (название раздела может меняться в зависимости от версии вашей платформы).
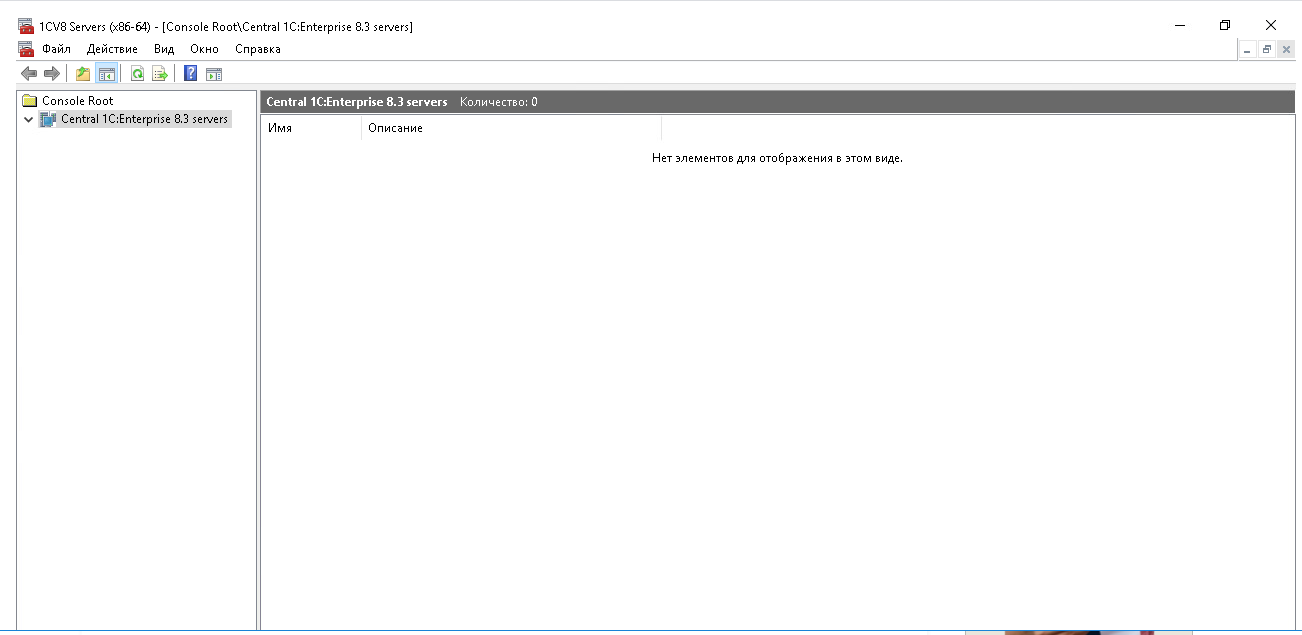
Нажимаем на него правой кнопкой мыши и выбираем «Создать» — «Центральный сервер 1C:Предприятия 8.3».
Присваиваем имя серверу. Пусть будет, например, 1cAppServer. Остальные поля оставляем без изменений.
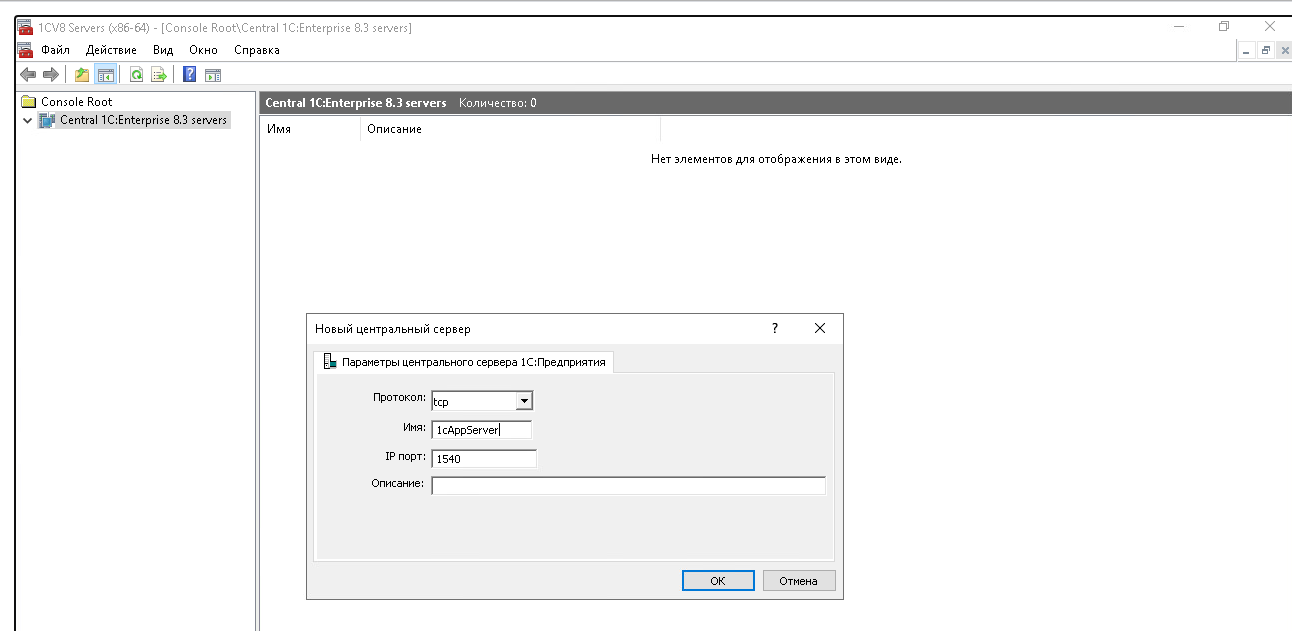
Если всё сделано правильно, в консоли появится центральный сервер.
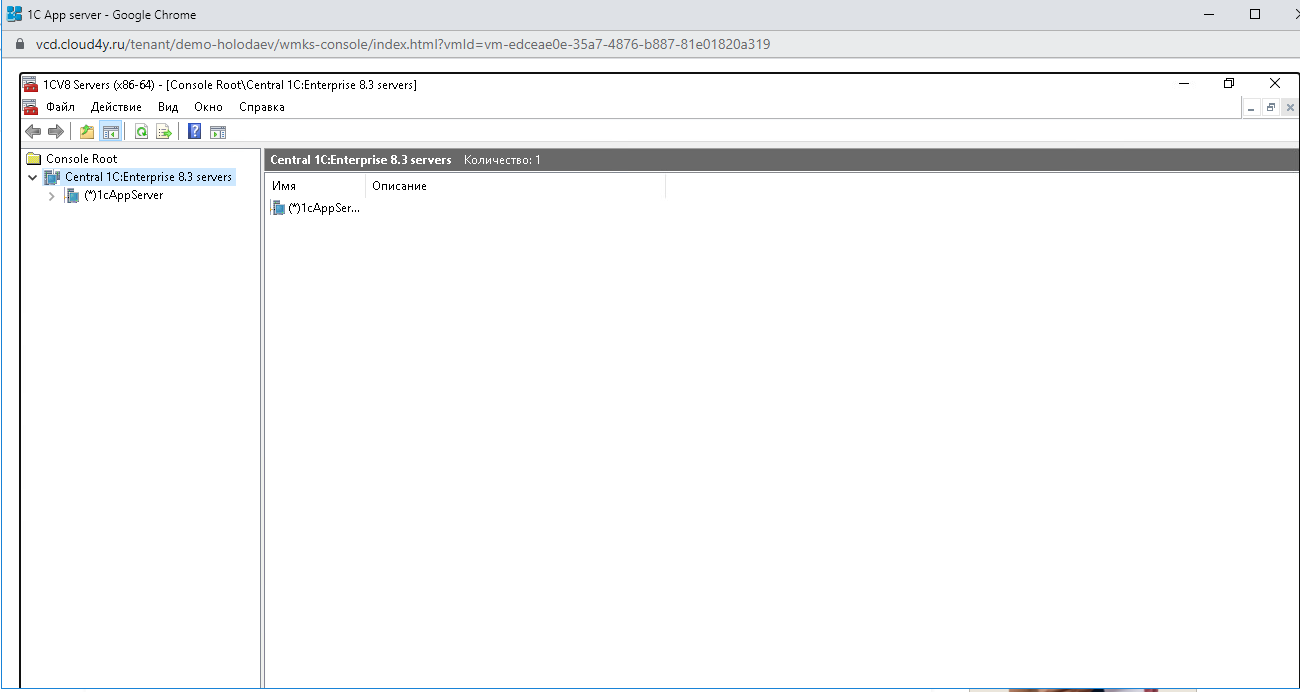
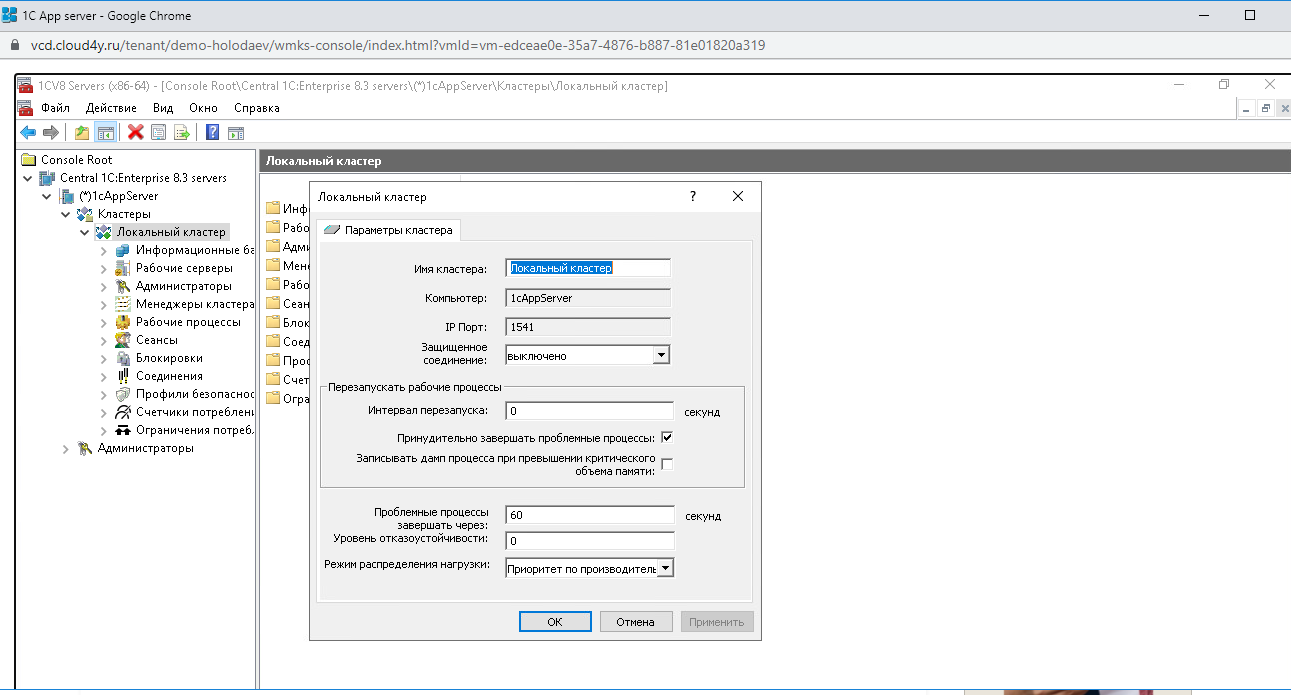
Шаг 2. Переименовываем локальный кластер
Раскрываем вкладку 1cAppServer и находим там «Кластеры» — «Локальный сервер».
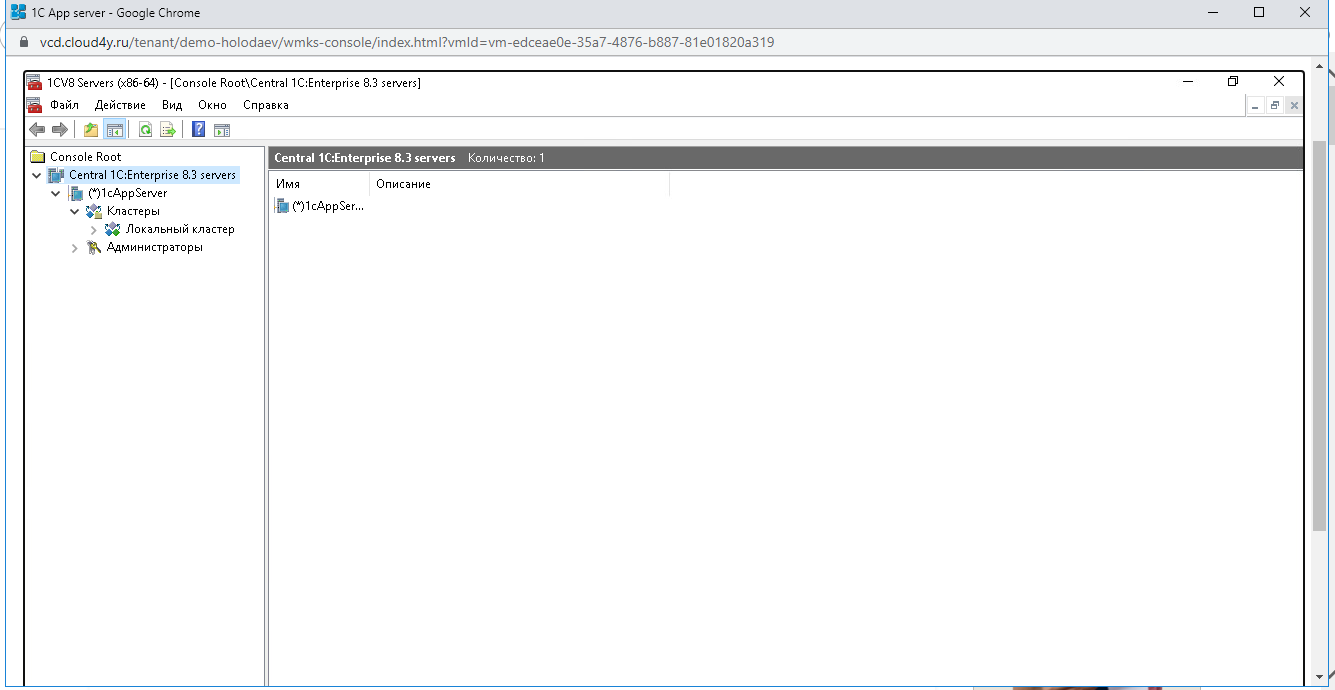
Нажимаем на него правой кнопкой мыши, выбираем «Свойства».
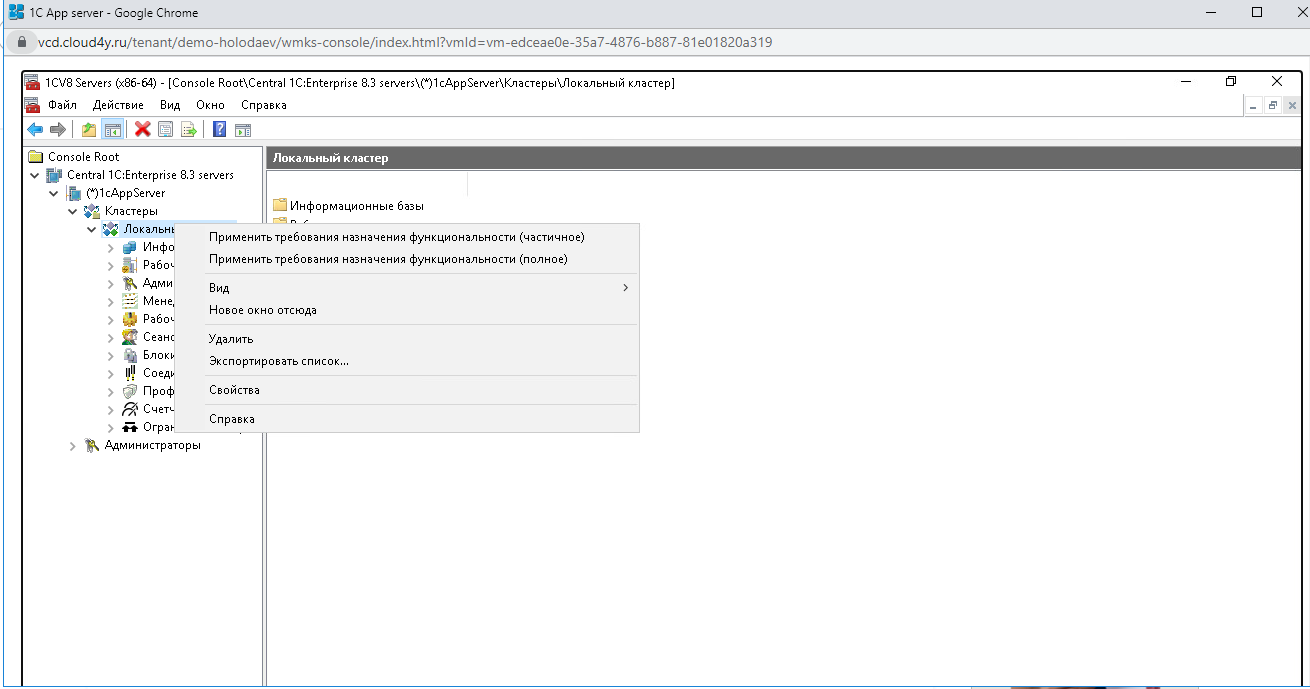
Переименовываем в Cluster 1C.
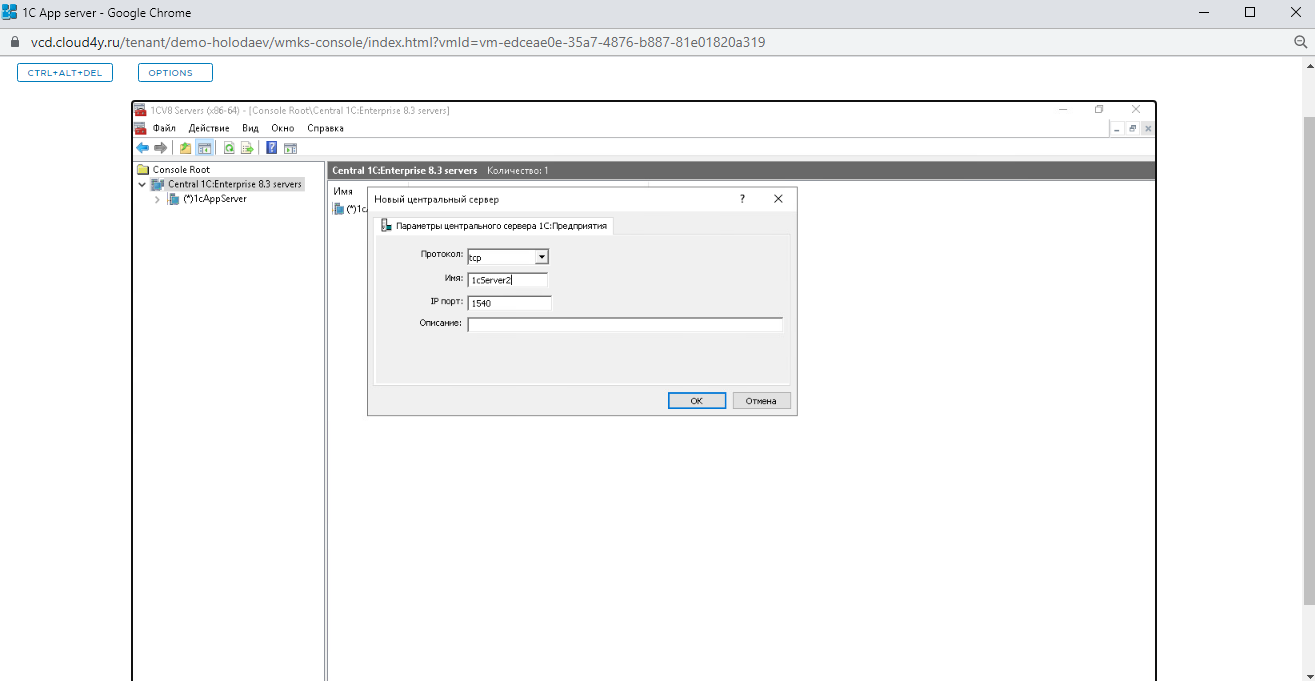
Шаг 3. Создаём второй центральный сервер
По схеме из первого шага создаём второй центральный сервер и называем его 1cServer2
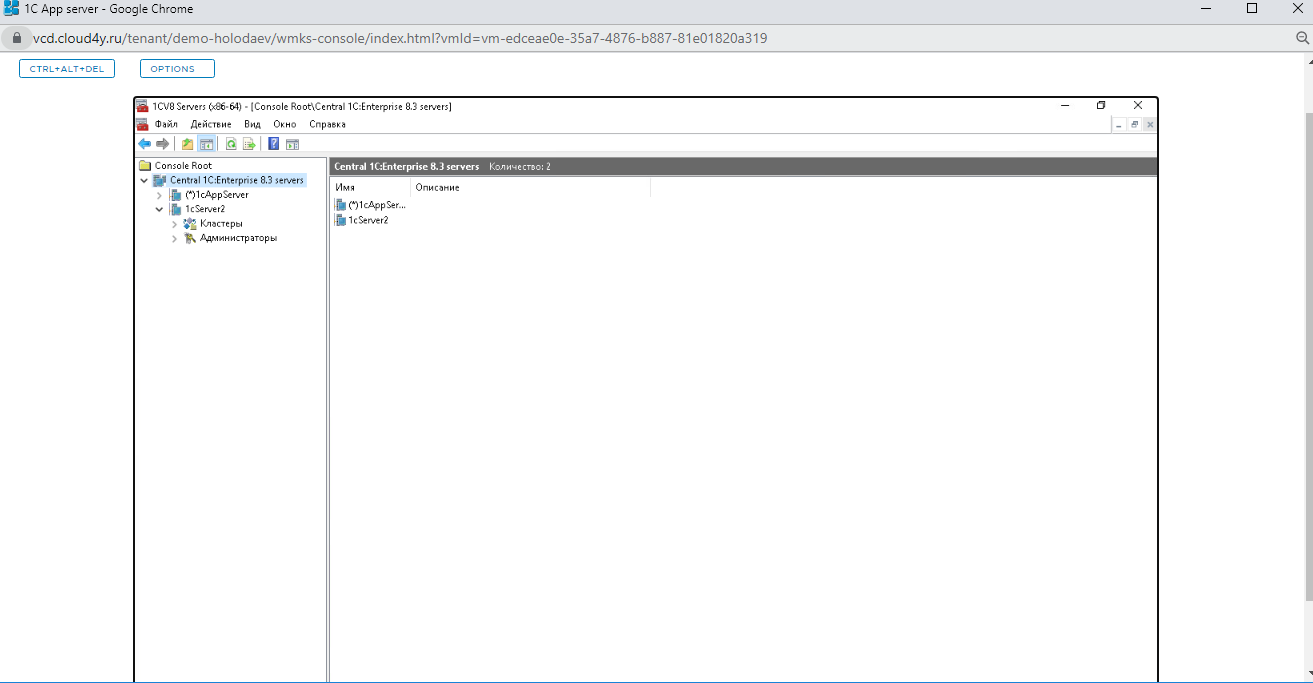
В консоли теперь отображается два сервера.
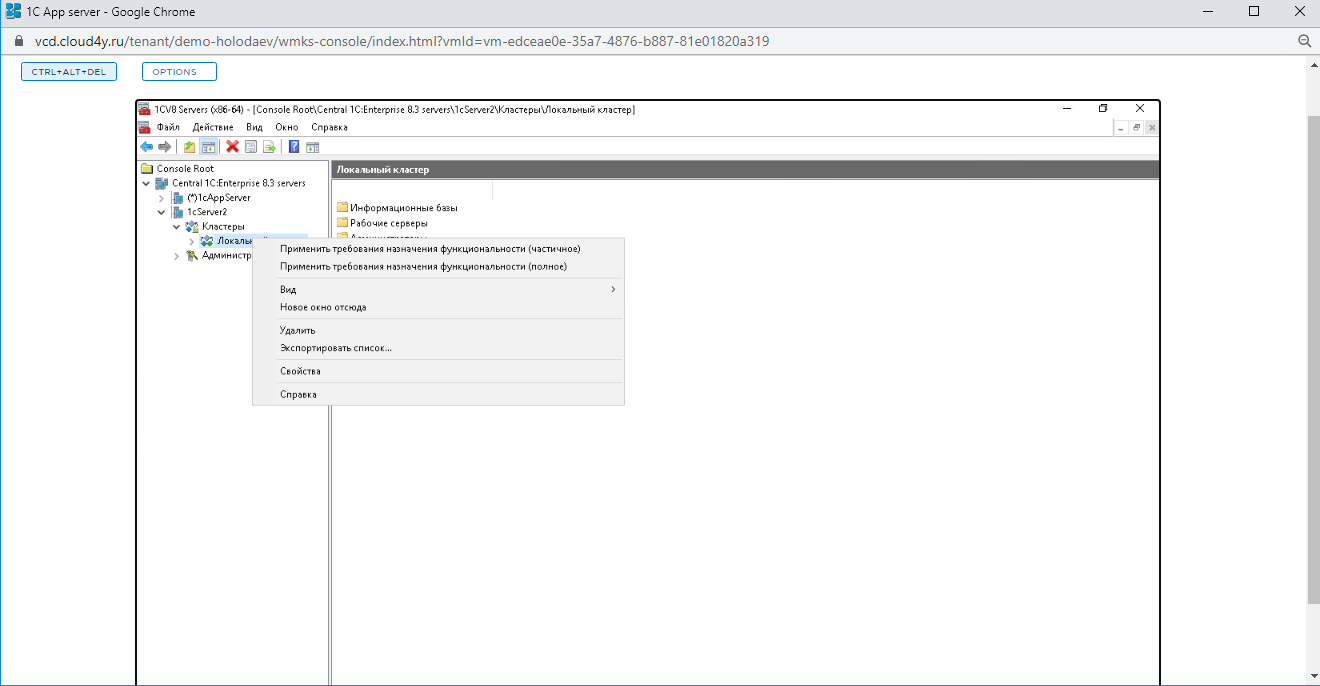
Шаг 4. Убираем лишнее
В разделе «Кластеры» в 1cServer2 открываем локальный кластер и удаляем его. Он создаётся автоматически, но нам не требуется.
Шаг 5. Подготавливаем кластер
Открываем 1cAppServer — «Кластеры» — Cluster 1C.
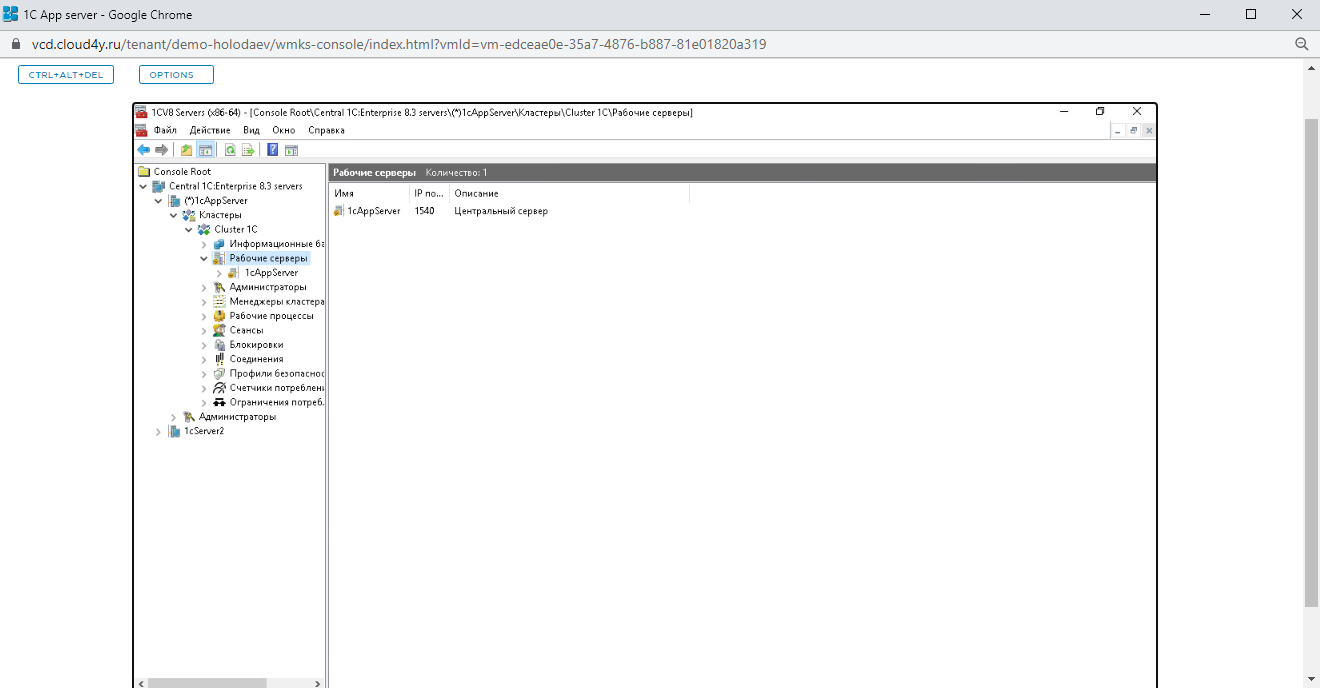
Выбираем «Рабочие серверы» — «Создать» — «Рабочий сервер».
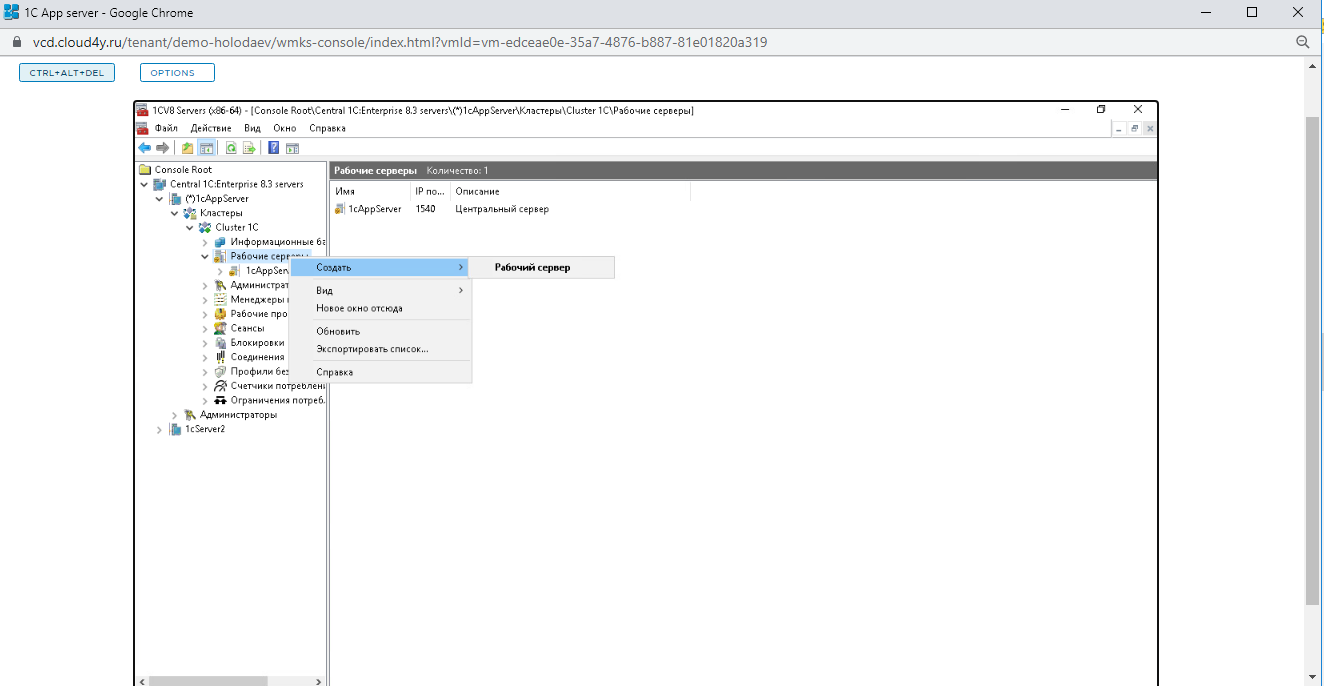
Присваиваем имя 1cServer2, указываем то же самое в поле «Компьютер» — это будет его сетевое описание. Остальные поля не меняем.
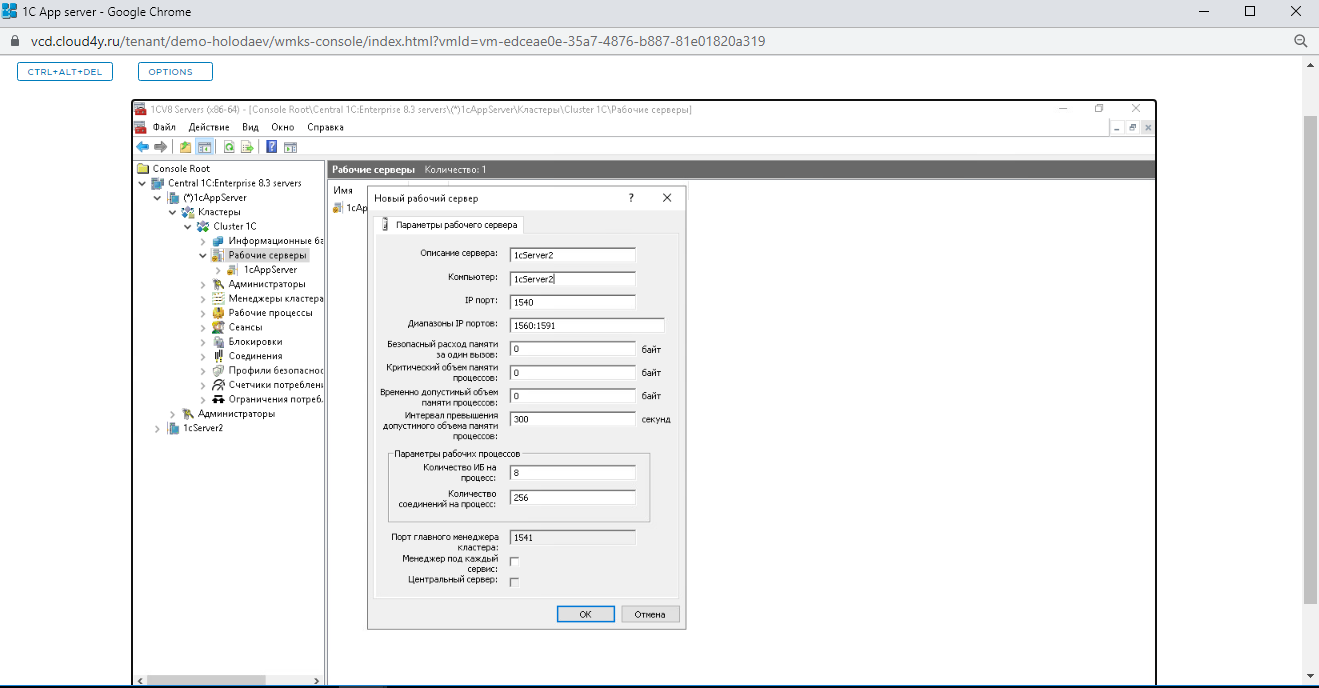
Шаг 6. Формируем кластер 1C
Вы видите, что в консоли есть два рабочих сервера. Нажмите правой кнопкой мыши на 1cServer2 — «Свойства» и отметьте чекбокс «Центральный сервер». Сохраните изменения.
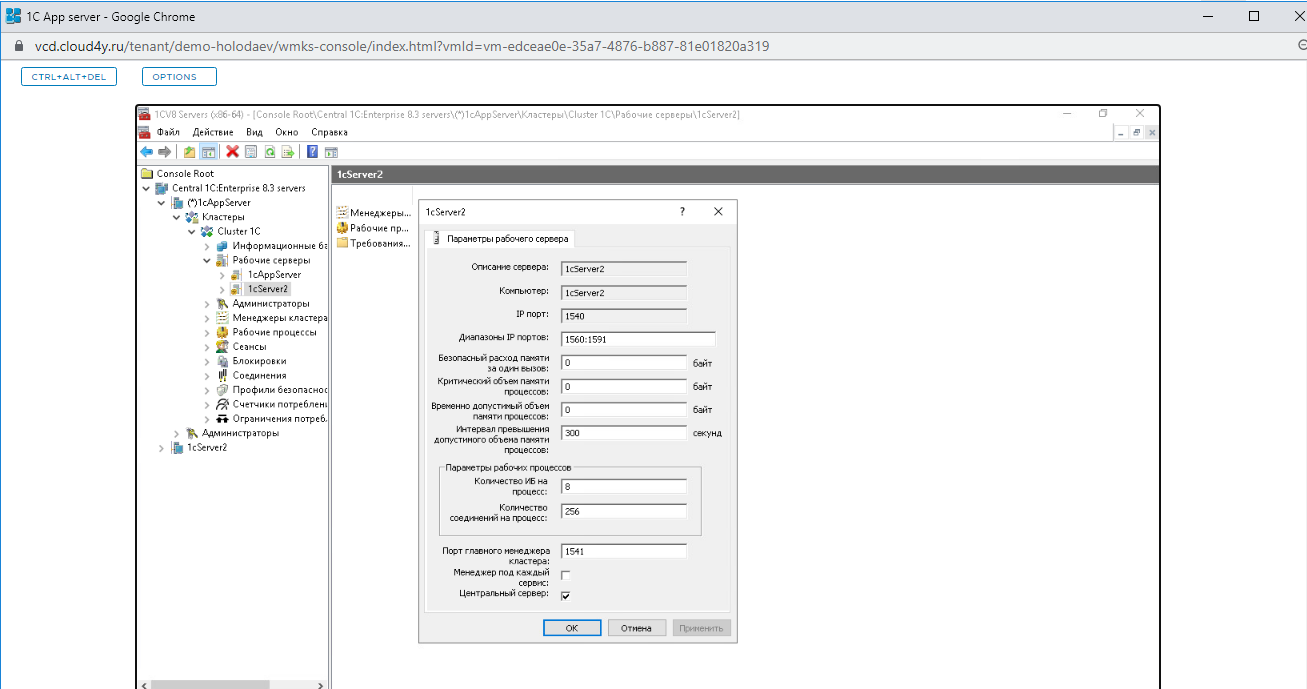
Шаг 7. Проверка
Во вкладке 1cServer2 — «Разделы» должен появиться Cluster 1C. Если вы его не видите, нужно перезагрузить консоль администрирования 1C. Закройте её и откройте заново — кластер будет отображаться.
Инструкция по настройке рабочих серверов с Технологической Платформой 1С:Предприятие
Ниже приводится инструкция по настройке рабочих серверов с Технологической Платформой 1С:Предприятие.
Рекомендуется при настройке рабочего сервера пройти указанный ниже сheck-лист и продумать, нужна ли указанная ниже настройка в вашем конкретном случае.
Если такая настройка нужна, то выполнить её. Важно на каждом пункте сознательно принимать решение о том, как именно вы хотите настроить рабочий сервер.
1. Определить, сколько информационных баз будут использоваться в кластере для работы пользователей
Существует несколько вариантов развертывания:
Наибольшие требования с точки зрения доступности информационной системы будут в случае развертывания в продуктивной и подготовительной зонах.
В этих случаях желательно все нерабочие информационные базы вынести в отдельный кластер на отдельные серверы.
Возможно, возникнет желание сделать копию рабочей информационной базы и развернуть в том же кластере в продуктивной среде, например, для того, чтобы восстановить определенные данные за прошлые сутки. Стоит перебороть это желание и проследить, чтобы
Для восстановления данных за предыдущие сутки не стоит использовать продукционный кластер, а получать необходимые данные с подготовительной зоны информационной системы.
Рекомендуется в продуктивной зоне настраивать кластер с минимальным числом необходимых баз, чтобы снизить возможное влияние тестовых баз на работу пользователей.
В тестовой зоне и зоне разработки ограничений по числу информационных баз в кластере условно нет.
2. Определить, сколько пользователей будет работать одновременно
Число одновременно работающих пользователей информационной базы является одним из основных параметров, определяющих нагрузку на информационную систему.
Этот параметр также необходим для корректного расчета конфигурации оборудования, который выполняется исходя из
3. Настроить профили пользователей ОС, от которых будут запускаться процессы кластера
Необходимо определиться, будут ли процессы кластера серверов работать от имени различных пользователей информационной системы.
Это может быть необходимо для того, чтобы код, который выполняется в rphost точно не мог обратиться к каким-либо определенным данным на рабочем сервере или выполнить операцию с административными правами.
Для того, чтобы создать профили пользователей ОС достаточно один раз войти от их имени в ОС Windows.
4. Настроить логирование и дампы
Для этого необходимо настроить:
Хорошей практикой будет настроить сбор WER для rmngr и ragent, но не указывать rphost.
5. Проверить настройки операционной системы
5.1. Настроить рабочий сервер
5.2. Настроить рабочий сервер
Необходимо настроить рабочий сервер в соответствии с инструкцией, которая позволяет избежать ошибки «An operation on a socket could not be performed because the system lacked sufficient buffer space or because a queue was full»
5.3. Убедиться, что брадмауэр операционной системы настроен таким образом, что не запрещает процессам кластера взаимодействовать корректно.
Информация по клиент-серверному варианту работы здесь;
Обратите внимание на используемые порты, которые указываются в параметрах центрального сервера,

в свойствах кластера серверов,

и рабочих серверов кластера.

5.4. Убедиться, что на рабочих серверах кластера одновременно не используется IPv4 и IPv6.


5.6. Убедиться, что установлены компоненты Microsoft Data Access Components
Этот пункт нужен для настройки с СУБД MS SQL Server.
В противном случае будете получать ошибку вида: «Компоненты OLE DB провайдера не найдены».
Скачать MDAC можно с официальных ресурсов microsoft.
6. Необходимо настроить сетевой стек для обеспечения возможности обработки большого числа подключений
Настройки, которые необходимо выполнить (в дополнение к настройке 5.2. Настроить рабочий сервер в соответствии с инструкцией):
7. Настроить кластер серверов
7.1. Необходимо добавить рабочие серверы в кластер
Информация по работе со списком серверов кластера тут: http://its.1c.ru/db/v837doc#bookmark:cs:TI000000157
7.2. Настроить условия перезапуска
Настроить условия перезапуска по превышению порога памяти.
7.3. Настроить расположение каталога кластера
Необходимо убедиться, что

7.4. Настроить число соединений и информационных баз на процесс
Настройку необходимо выполнить с учетом конфигурации системы
Постарайтесь выполнять настройку таким образом, чтобы она не приводила к запуску 100 процессов rphost, т.к. значительное число процессов rphost приводит к неэффективному использованию памяти процессами кластера.
Не стоит просто так уменьшать параметр «Число соединений на процесс» или «Число информационных баз на процесс».
Если у вас нет технического обоснования, почему именно так лучше, рекомендуем оставить значения по умолчанию

7.5. Выполнить настройки для случая нескольких рабочих серверов в кластере.
8. Первый запуск
На этом этапе следует выполнить следующие шаги:
9. Отказоустойчивость
В случае необходимости настройки отказоустойчивого кластера, выполните следующие шаги.
9.1. Проверить лицензии.
Убедитесь, что на рабочих серверах, которые должны выполнять роль Центральных серверов достаточно лицензий для работы всех пользователей в информационной системе при отсутствии одного из Центральных серверов в случае возможного (теоретически) отказа.
9.2. Установить флаг «Центральный сервер».
Установить флаг как на рисунке ниже.

9.3. Установить флаг «Уровень отказоустойчивости»
Установить параметр, пример на рисунке ниже.
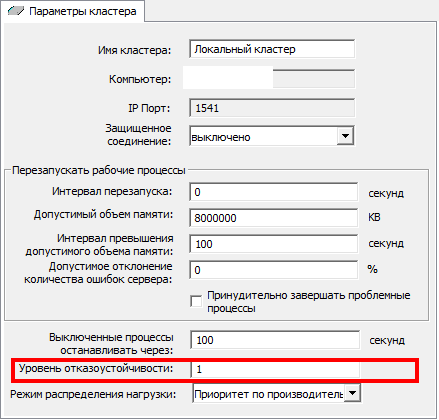
Подробную информацию про уровень отказоустойчивости вы можете прочитать в статье
Обратите внимание, что не нужно просто так указывать максимально возможный уровень отказоустойчивости, т.к. это приведет к избыточным накладным расходам.
9.4. Скорректировать строку соединения
Необходимо скорректировать строку соединения с информационной базой.
Имеется возможность указания списка резервирования с помощью строки соединения с информационной базой или в соответствующем поле свойств информационной базы.
Список указывается в формате Server1, Server2:Port, Server3.
10. Замечания
10.1. Не настраивайте exec backup (или аналогичные утилиты) на директории кластера серверов
Причина в том, что в этих директориях могут располагаться хранилища с сеансовыми данными, выполнять backup которых не нужно, а создание backp-а которых будет приводить к избыточным накладным расходам.
10.2. Не настраивайте сжатие данных дисков с директорией кластера

10.3. Не забывайте про периодическое выполнение дефрагментации дисков ОС Windows.
10.4. Настроить защиту от вирусов.
В случае расположения рабочих серверов кластера в зоне, к которой доступ строго ограничен, не имеет смысл настраивать антивирусные решения на рабочих серверах.
Настройка антивирусных решений на таких серверах будет оказывать существенное влияние на производительность при практическом отсутствии выигрыша с точки зрения защиты.
При этом, стоит обеспечить защиту антивирусными решениями те пользовательские компьютеры, с которых выполняется доступ к рабочим серверам кластера и сетевым директориям.
Про кластер серверов 1С
Кластер — это разновидность параллельной
или распределённой системы, которая:
1. состоит из нескольких связанных
между собой компьютеров;
2. используется как единый,
унифицированный компьютерный ресурс
Дано: есть бизнес-приложение (например, ERP-система), с которым работают одновременно тысячи (возможно, десятки тысяч) пользователей.
К желаемому результату мы пришли не сразу.
В этой статье расскажем о том, какие бывают кластеры, как мы выбирали подходящий нам вид кластера и о том, как эволюционировал наш кластер от версии к версии, и какие подходы позволили нам в итоге создать систему, обслуживающую десятки тысяч одновременных пользователей.

Как писал автор эпиграфа к этой статье Грегори Пфистер в своей книге «In search of clusters», кластер был придуман не каким-либо конкретным производителем железа или софта, а клиентами, которым не хватало для работы мощностей одного компьютера или требовалось резервирование. Случилось это, по мнению Пфистера, ещё в 60-х годах прошлого века.
Традиционно различают следующие основные виды кластеров:
Для тех, кто не в курсе, коротко расскажу, как устроены бизнес-приложения 1С. Это приложения, написанные на предметно-ориентированном языке, «заточенном» под автоматизацию учётных бизнес-задач. Для выполнения приложений, написанных на этом языке, на компьютере должен быть установлен рантайм платформы 1С:Предприятия.
1С:Предприятие 8.0
Первая версия сервера приложений 1С (еще не кластер) появилась в версии платформы 8.0. До этого 1С работала в клиент-серверном варианте, данные хранились в файловой СУБД или MS SQL, а бизнес-логика работала исключительно на клиенте. В версии же 8.0 был сделан переход на трехзвенную архитектуру «клиент – сервер приложений – СУБД».
Сервер 1С в платформе 8.0 представлял собой СОМ+ сервер, умеющий исполнять прикладной код на языке 1С. Использование СОМ+ обеспечивало нам готовый транспорт, позволяющий клиентским приложениям общаться с сервером по сети. Очень многое в архитектуре и клиент-серверного взаимодействия, и прикладных объектов, доступных разработчику 1С, проектировалось с учетом использования СОМ+. В то время в архитектуру не было заложено отказоустойчивости, и падение сервера вызывало отключение всех клиентов. При падении серверного приложения СОМ+ поднимал его при обращении к нему первого клиента, и клиенты начинали свою работу с начала – с коннекта к серверу. В то время всех клиентов обслуживал один процесс.
1С:Предприятие 8.1
В следующей версии мы захотели:
Так в версии 8.1 появился первый кластер. Мы реализовали свой протокол удаленного вызова процедур (поверх ТСР), который по внешнему виду выглядел для конечного потребителя-клиента практически как СОМ+ (т.е. нам практически не пришлось переписывать код, отвечающий за клиент-серверные вызовы). При этом сервер, реализованный нами на С++, мы сделали платформенно-независимым, способным работать и на Windows, и на Linux.
На смену монолитному серверу версии 8.0 пришло 3 вида процессов – рабочий процесс, обслуживающий клиентов, и 2 служебных процесса, поддерживающих работу кластера:
Клиент на протяжении сессии работал с одним рабочим процессом, падение рабочего процесса означало для всех клиентов, которых этот процесс обслуживал, аварийное завершение сессии. Остальные клиенты продолжали работу.
1С:Предприятие 8.2
В версии 8.2 мы захотели, чтобы приложения 1С могли запускаться не только в нативном (исполняемом) клиенте, а ещё и в браузере (без модификации кода приложения). В связи с этим, в частности, встала задача отвязать текущее состояние приложения от текущего соединения с рабочим процессом rphost, сделать его stateless. Как следствие возникло понятие сеанса и сеансовых данных, которые нужно было хранить вне рабочего процесса (потому что stateless). Был разработан сервис сеансовых данных, хранящий и кэширующий сеансовую информацию. Появились и другие сервисы — сервис управляемых транзакционных блокировок, сервис полнотекстового поиска и т.д.
В этой версии также появились несколько важных нововведений – улучшенная отказоустойчивость, балансировка нагрузки и механизм резервирования кластеров.
Отказоустойчивость
Поскольку процесс работы стал stateless и все необходимые для работы данные хранились вне текущего соединения «клиент – рабочий процесс», в случае падения рабочего процесса клиент при следующем обращении к серверу переключался на другой, «живой» рабочий процесс. В большинстве случаев такое переключение происходило незаметно для клиента.
Механизм работает так. Если клиентский вызов к рабочему процессу по какой-то причине не смог исполниться до конца, то клиентская часть способна, получив ошибку вызова, этот вызов повторить, переустановив соединение с тем же рабочим процессом или с другим. Но повторять вызов можно не всегда; повтор вызова означает, что мы отправили вызов на сервер, а результата не получили. Мы стараемся повторить вызов, при этом при выполнении повторного вызова мы оцениваем, каков результат на сервере был у предшествующего вызова (информация об этом сохраняется на сервере в данных сеанса), потому что если вызов успел там «наследить» (закрыть транзакцию, сохранить сеансовые данные и т.п.) – то просто так повторять его нельзя, это приведет к рассогласованию данных. Если повторять вызов нельзя, клиент получит сообщение о неисправимой ошибке, и клиентское приложение придется перезапустить. Если же вызов «наследить» не успел (а это наиболее частая ситуация, т.к. многие вызовы не меняют данных, например, отчеты, отображение данных на форме и т.п., а те, которые меняют данные – пока транзакция не зафиксирована или пока изменение сеансовых данных не отправлено в менеджер – следов вызов не оставил) — его можно повторить без риска рассогласования данных. Если рабочий процесс упал или произошел обрыв сетевого соединения – такой вызов повторяется, и эта «катастрофа» для клиентского приложения происходит полностью незаметно.
Балансировка нагрузки
Задача балансировки нагрузки в нашем случае звучит так: в систему заходит новый клиент (или уже работающий клиент совершает очередной вызов). Нам надо выбрать, на какой сервер и в какой рабочий процесс направить вызов клиента, чтобы обеспечить клиенту максимальное быстродействие.
Это стандартная задача для кластера с балансировкой нагрузки. Есть несколько типовых алгоритмов её решения, например:
Запрос от нового клиента адресуется на наиболее производительный на данный момент сервер.
Запрос от существующего клиента в большинстве случаев адресуется на тот сервер и в тот рабочий процесс, в который адресовался его предыдущий запрос. С работающим клиентом связан обширный набор данных на сервере, передавать его между процессами (а тем более между серверами) – довольно накладно (хотя мы умеем делать и это).
Запрос от существующего клиента передается в другой рабочий процесс в двух случаях:
Резервирование кластеров
Мы решили повысить отказоустойчивость кластера, прибегнув к схеме Active / passive. Появилась возможность конфигурировать два кластера – рабочий и резервный. В случае недоступности основного кластера (сетевые неполадки или, например, плановое техобслуживание) клиентские вызовы перенаправлялись на резервный кластер.
Однако эта конструкция была довольно сложна в настройке. Администратору приходилось вручную собирать две группы серверов в кластеры и конфигурировать их. Иногда администраторы допускали ошибки, устанавливая противоречащие друг другу настройки, т.к. не было централизованного механизма проверки настроек. Но, тем не менее, этот подход повышал отказоустойчивость системы.
1С:Предприятие 8.3
В версии 8.3 мы существенно переписали код серверной части, отвечающий за отказоустойчивость. Мы решили отказаться от схемы Active / passive кластеров ввиду сложности её конфигурирования. В системе остался только один отказоустойчивый кластер, состоящий из любого количества серверов – это ближе к схеме на Active / active, в которой запросы на отказавший узел распределяются между оставшимися рабочими узлами. За счет этого кластер стал проще в настройке. Ряд операций, повышающих отказоустойчивость и улучшающих балансировку нагрузки, стали автоматизированными. Из важных нововведений:
Главная идея этих наработок – упростить работу администратора, позволяя ему настраивать кластер в привычных ему терминах, на уровне оперирования серверами, не опускаясь ниже, а также минимизировать уровень «ручного управления» работой кластера, дав кластеру механизмы для решения большинства рабочих задач и возможных проблем «на автопилоте».
Три звена отказоустойчивости
Как известно, даже если компоненты системы по отдельности надёжны, проблемы могут возникнуть там, где компоненты системы вызывают друг друга. Мы хотели свести количество мест, критичных для работоспособности системы, к минимуму. Важным дополнительным соображением была минимизация переделок прикладных механизмов в платформе и исключение изменений в прикладных решениях. В версии 8.3 появилось 3 звена обеспечения отказоустойчивости «на стыках»:
В заключение
Благодаря механизму отказоустойчивости приложения, созданные на платформе 1С:Предприятие, благополучно переживают разные виды отказов рабочих серверов в кластере, при этом бо́льшая часть клиентов продолжают работать без перезапуска.
Бывают ситуации, когда мы не можем повторить вызов, или падение сервера застает платформу в очень неудачный момент времени, например, в середине транзакции и не очень понятно, что с ними делать. Мы стараемся обеспечить статистически хорошую выживаемость клиентов при падении серверов в кластере. Как правило, средние потери клиентов за отказ сервера – единицы процентов. При этом все «потерянные» клиенты могут продолжить работу в кластере после перезапуска клиентского приложения.
Надежность кластера серверов 1С в версии 8.3 существенно повысилась. Уже давно не редкость внедрения продуктов 1С, где количество одновременно работающих пользователей достигает нескольких тысяч. Есть и внедрения, где одновременно работают и 5 000, и 10 000 пользователей — например, внедрение в «Билайне», где приложение «1С: Управление Торговлей» обслуживает все салоны продаж «Билайн» в России, или внедрение в грузоперевозчике «Деловые Линии», где приложение, самостоятельно созданное разработчиками ИТ-отдела «Деловых Линий» на платформе 1С:Предприятие, обслуживает полный цикл грузоперевозок. Наши внутренние нагрузочные тесты кластера эмулируют одновременную работу до 20 000 пользователей.
В заключение хочется кратко перечислить что ещё полезного есть в нашем кластере (список неполный):



