Оператор SQL GROUP BY для группировки в запросах
Оператор GROUP BY имеет следующий синтаксис:
Группировка по одному столбцу без агрегатных функций
Если в результате запроса требуется вывести один столбец и по этому же столбцу производится группировка, то оператор GROUP BY просто выбирает уникальные значения и убирает дубликаты, то есть выполняет те же задачи, что и ключевое слово DISTINCT.
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке .
В примерах работаем с базой данных библиотеки и ее таблицей «Книга в пользовании» (Bookinuse). Отметим, что оператор GROUP BY ведёт себя несколько по-разному в MySQL и в MS SQL Server. Эти различия будут показаны на примерах.
| Author | Title | Pubyear | Inv_No | Customer_ID |
| Толстой | Война и мир | 2005 | 28 | 65 |
| Чехов | Вишневый сад | 2000 | 17 | 31 |
| Чехов | Избранные рассказы | 2011 | 19 | 120 |
| Чехов | Вишневый сад | 1991 | 5 | 65 |
| Ильф и Петров | Двенадцать стульев | 1985 | 3 | 31 |
| Маяковский | Поэмы | 1983 | 2 | 120 |
| Пастернак | Доктор Живаго | 2006 | 69 | 120 |
| Толстой | Воскресенье | 2006 | 77 | 47 |
| Толстой | Анна Каренина | 1989 | 7 | 205 |
| Пушкин | Капитанская дочка | 2004 | 25 | 47 |
| Гоголь | Пьесы | 2007 | 81 | 47 |
| Чехов | Избранные рассказы | 1987 | 4 | 205 |
| Пушкин | Сочинения, т.1 | 1984 | 6 | 47 |
| Пастернак | Избранное | 2000 | 137 | 18 |
| Пушкин | Сочинения, т.2 | 1984 | 8 | 205 |
| NULL | Наука и жизнь 9 2018 | 2019 | 127 | 18 |
| Чехов | Ранние рассказы | 2001 | 171 | 31 |
Пример 1. Вывести авторов выданных книг, сгруппировав их. Пишем следующий запрос:
Этот запрос вернёт следующий результат:
| Author |
| NULL |
| Гоголь |
| Ильф и Петров |
| Маяковский |
| Пастернак |
| Пушкин |
| Толстой |
| Чехов |
Как видим, в таблице стало меньше строк, так как фамилии авторов остались каждая по одной.
В следующем примере увидим, что оператор GROUP BY не следует путать с оператором ORDER BY и поймём, чем эти операторы отличаются друг от друга.
Пример 2. Вывести авторов и названия выданных книг, сгруппировав по авторам. Пишем следующий запрос, который допустим в MySQL:
Этот запрос вернёт следующий результат:
| Author | Title |
| NULL | Наука и жизнь 9 2018 |
| Гоголь | Пьесы |
| Ильф и Петров | Двенадцать стульев |
| Маяковский | Поэмы |
| Пастернак | Доктор Живаго |
| Пушкин | Капитанская дочка |
| Толстой | Война и мир |
| Чехов | Вишнёвый сад |
Как видим, в таблице каждому автору соответствует лишь одна книга, причём та, которая в таблице BOOKINUSE является первой по порядку записей.
Если бы нам требовалось вывести все книги, причём авторы должны были бы следовать не «вразброс», а по порядку: сначала Гоголь и все его книги, затем другие авторы и все их книги, то мы применили бы не оператор GROUP BY, а оператор ORDER BY.
Группировка по нескольким столбцам без агрегатных функций
И всё же вывести все записи, соответствующие значению столбца, по которому происходит группировка, можно. Но в этом случае в результирующей таблице должен появиться ещё один столбец. Такой случай проиллюстирован в следующем примере.
Пример 3. Вывести авторов, названия выданных книг, ID пользователя и инвентарный номер выданной книги. Сгруппировать по авторам, ID пользователя и инвентарному номеру. На MySQL запрос будет следующим:
Этот запрос вернёт следующий результат:
| Author | Title | Customer_ID | Inv_no |
| Гоголь | Пьесы | 47 | 81 |
| Ильф и Петров | Двенадцать стульев | 31 | 3 |
| Маяковский | Поэмы | 120 | 2 |
| Пастернак | Избранное | 18 | 137 |
| Пастернак | Доктор Живаго | 120 | 69 |
| Пушкин | Капитанская дочка | 47 | 25 |
| Пушкин | Сочинения, т.1 | 47 | 6 |
| Пушкин | Сочинения, т.2 | 205 | 8 |
| Толстой | Воскресенье | 47 | 77 |
| Толстой | Война и мир | 65 | 28 |
| Толстой | Анна Каренина | 205 | 7 |
| Чехов | Вишневый сад | 31 | 19 |
| Чехов | Ранние рассказы | 31 | 171 |
| Чехов | Вишневый сад | 65 | 5 |
| Чехов | Избранные рассказы | 120 | 19 |
| Чехов | Избранные рассказы | 205 | 4 |
По-другому ведёт себя оператор GROUP BY в MS SQL Server и в случае этого запроса.
Группировка с агрегатными функциями
Пример 4. Вывести количество выданных книг каждого автора. Запрос будет следующим:
Результатом выполнения запроса будет следующая таблица:
| Author | InUse |
| NULL | 1 |
| Гоголь | 1 |
| Ильф и Петров | 1 |
| Маяковский | 1 |
| Пастернак | 2 |
| Пушкин | 3 |
| Толстой | 3 |
| Чехов | 5 |
Пример 5. Вывести количество книг, выданных каждому пользователю. Запрос будет следующим:
Результатом выполнения запроса будет следующая таблица:
| User_ID | InUse |
| 18 | 1 |
| 31 | 3 |
| 47 | 4 |
| 65 | 2 |
| 120 | 3 |
| 205 | 3 |
Примеры запросов к базе данных «Библиотека» есть также в уроках по оператору IN, предикату EXISTS и функциям CONCAT, COALESCE.
SELECT — GROUP BY (Transact-SQL)
Предложение инструкции SELECT, которое разделяет результат запроса на группы строк обычно с целью выполнения одного или нескольких статистических вычислений в каждой группе. Инструкция SELECT возвращает одну строку для каждой группы.
Синтаксис
 Синтаксические обозначения в Transact-SQL (Transact-SQL)
Синтаксические обозначения в Transact-SQL (Transact-SQL)
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
column-expression
Указывает на столбец или на нестатистическое вычисление в столбце. Этот столбец может принадлежать таблице, производной таблице или представлению. Столбец должен быть указан в предложении FROM инструкции SELECT, но не обязательно должен присутствовать в списке SELECT.
Допустимые выражения см. в разделе expression.
Столбец должен быть указан в предложении FROM инструкции SELECT, но не обязательно должен присутствовать в списке SELECT. Каждый столбец таблицы или представления в любом нестатистическом выражении в списке должен быть включен в список GROUP BY.
Следующие инструкции являются допустимыми.
Следующие инструкции не являются допустимыми.
Выражение столбца не может содержать:
Группирует результаты инструкции SELECT в соответствии со значениями в списке одного или нескольких выражений столбцов.
Например, этот запрос создает таблицу Sales со столбцами Country, Region и Sales. Он вставляет четыре строки, и две строки имеют совпадающие значения для столбцов Country и Region.
В таблице Sales содержатся указанные далее строки.
| Country | Region | Sales |
|---|---|---|
| Canada | Alberta | 100 |
| Canada | British Columbia | 200 |
| Canada | British Columbia | 300 |
| США | Montana | 100 |
Этот запрос группирует значения столбцов Country и Region и возвращает общую сумму по каждому сочетанию значений.
Результат запроса содержит 3 строки, так как существует 3 сочетания значений для Country и Region. Значение TotalSales для Canada и British Columbia является суммой двух строк.
| Country | Регион | TotalSales |
|---|---|---|
| Canada | Alberta | 100 |
| Canada | British Columbia | 500 |
| США | Montana | 100 |
GROUP BY ROLLUP
Создает группу для каждого сочетания выражений столбцов. Кроме того, выполняет сведение результатов в промежуточные и общие итоги. Для этого запрос перемещается справа налево, уменьшая количество выражений столбцов, по которым он создает группы и агрегаты.
Порядок столбцов влияет на выходные данные ROLLUP и может отразиться на количестве строк в результирующем наборе.
Например, GROUP BY ROLLUP (col1, col2, col3, col4) создает группы для каждой комбинации выражений столбцов в следующих списках.
Принимая во внимание таблицу из предыдущего примера, этот код выполняет операцию GROUP BY ROLLUP вместо простого предложения GROUP BY.
Результатом запроса являются те же статистические вычисления, что и в простом предложении GROUP BY без ROLLUP. Кроме того, здесь создаются промежуточные итоги для каждого значения в столбце Country. Наконец, выводится общий итог для всех строк. Результат имеет следующий вид:
| Country | Регион | TotalSales |
|---|---|---|
| Canada | Alberta | 100 |
| Canada | British Columbia | 500 |
| Canada | NULL | 600 |
| США | Montana | 100 |
| США | NULL | 100 |
| NULL | NULL | 700 |
GROUP BY CUBE ( )
GROUP BY CUBE создает группы для всех возможных сочетаний столбцов. Для GROUP BY CUBE (a, b) результатами являются группы для уникальных значений (a, b) (NULL, b), (a, NULL) и (NULL, NULL).
Принимая во внимание таблицу из предыдущего примера, этот код выполняет операцию GROUP BY CUBE по столбцам Country и Region.
Результатом запроса являются группы для уникальных значений (Country, Region), (NULL, Region), (Country, NULL) и (NULL, NULL). Результат выглядит следующим образом:
| Country | Регион | TotalSales |
|---|---|---|
| Canada | Alberta | 100 |
| NULL | Alberta | 100 |
| Canada | British Columbia | 500 |
| NULL | British Columbia | 500 |
| США | Montana | 100 |
| NULL | Montana | 100 |
| NULL | NULL | 700 |
| Canada | NULL | 600 |
| США | NULL | 100 |
GROUP BY GROUPING SETS ( )
Параметр GROUPING SETS позволяет объединять несколько предложений GROUP BY в одно предложение GROUP BY. Результаты эквивалентны тем, что формируются с применением конструкции UNION ALL к указанным группам.
Например, GROUP BY ROLLUP (Country, Region) и GROUP BY GROUPING SETS ( ROLLUP (Country, Region) ) возвращают одинаковые результаты.
Если параметр GROUPING SETS имеет два или более элементов, результатом будет объединение элементов. Этот пример возвращает объединение результатов ROLLUP и CUBE для Country и Region.
Результаты будут такими же, так как этот запрос возвращает объединение двух инструкций GROUP BY.
SQL не консолидирует повторяющиеся группы, созданные для списка GROUPING SETS. Например, в GROUP BY ( (), CUBE (Country, Region) ) оба элемента возвращают строку для общего итога, и в списке результатов будут указаны обе строки.
GROUP BY ()
Указывает пустую группу, что приводит к созданию общего итога. Он полезен в качестве одного из элементов GROUPING SET. Например, эта инструкция выводит общий объем продаж для каждой страны, а затем — общий итог по всем странам.
Область применения: SQL Server и база данных SQL Azure
Этот синтаксис поддерживается только для обратной совместимости. В будущей версии он будет удален. Избегайте использования этого синтаксиса в новых разработках и учитывайте необходимость изменения в будущем приложений, использующих этот синтаксис сейчас.
Указывает включить все группы в результаты независимо от того, соответствуют ли они условиям поиска в предложении WHERE. Группы, которые не соответствуют условиям поиска, имеют значение NULL для статистического вычисления.
Область применения: SQL Server и база данных SQL Azure
Этот синтаксис поддерживается только для обратной совместимости. Избегайте использования этого синтаксиса в новых разработках и учитывайте необходимость изменения в будущем приложений, использующих этот синтаксис сейчас.
WITH (DISTRIBUTED_AGG)
Область применения: Azure Synapse Analytics и Система платформы аналитики (PDW)
Указание запроса DISTRIBUTED_AGG заставляет систему MPP перераспределять таблицу по определенному столбцу до выполнения статистического вычисления. Только один столбец в предложении GROUP BY может иметь указание запроса DISTRIBUTED_AGG. После завершения запроса перераспределенная таблица удаляется. Исходная таблица не изменяется.
Примечание. Указание запроса DISTRIBUTED_AGG предоставляется для обеспечения обратной совместимости с более ранними версиями Система платформы аналитики (PDW) и не улучшает производительность большинства запросов. По умолчанию MPP уже перераспределяет данные для улучшения производительности для статистических вычислений.
Общие замечания
Взаимодействие GROUP BY с инструкцией SELECT
Предложение ORDER BY:
Ограничения
Область применения: SQL Server (начиная с версии 2008) и Azure Synapse Analytics
Максимальная емкость
Для предложения GROUP BY, использующего ROLLUP, CUBE или GROUPING SETS, используется максимум 32 выражения. Максимальное количество групп — 4096 (2 12 ). Следующие примеры завершаются ошибкой, поскольку предложение GROUP BY имеет больше 4096 групп.
В следующем примере формируется 4097 (2 12 + 1) группирующих наборов, поэтому пример завершится ошибкой.
В этом примере используется синтаксис обратной совместимости. В примере создается 8192 (2 13 ) группирующих наборов, поэтому он завершится ошибкой.
Для предложений GROUP BY с поддержкой обратной совместимости и не содержащих операторов CUBE или ROLLUP количество элементов GROUP BY ограничивается размером столбцов GROUP BY, статистически обрабатываемых столбцов и статистических значений, включенных в запрос. Это объясняется ограничением размера промежуточной рабочей таблицы (8060 байт), необходимой для хранения промежуточных результатов запроса. При указании CUBE или ROLLUP максимально разрешенное количество выражений группирования равно 12.
Поддержка функций предложения GROUP BY, совместимых с ISO и ANSI SQL-2006
Предложение GROUP BY поддерживает все возможности предложения GROUP BY, включенные в стандарт SQL-2006, со следующими синтаксическими исключениями.
GROUP BY [ALL/DISTINCT] используется только в простом предложении GROUP BY, которое содержит выражения столбцов. Это предложение не может использоваться с конструкциями GROUPING SETS, ROLLUP, CUBE, WITH CUBE или WITH ROLLUP. Ключевое слово ALL применяется по умолчанию и задано неявно. Оно допускается только в синтаксисе обратной совместимости.
Сравнение поддерживаемых функций предложения GROUP BY
В следующей таблице описаны поддерживаемые возможности предложения GROUP BY с учетом версии SQL и уровня совместимости базы данных.
Например: SELECT SUM (x) FROM T GROUP BY dbo.cube(y);
Выдается следующее сообщение об ошибке: «Применение неверного синтаксиса недалеко от ключевого слова ‘cube’|’rollup'».
Например: SELECT SUM (x) FROM T GROUP BY dbo.cube(y);
Примеры
A. Использование простого предложения GROUP BY
Б. Использование предложения GROUP BY с несколькими таблицами
В. Использование предложения GROUP BY в выражениях
Г. Использование предложения GROUP BY с предложением HAVING
Примеры: Azure Synapse Analytics и Parallel Data Warehouse
Д. Базовое использование предложения GROUP BY
В следующем примере вычисляется общий объем всех продаж за каждый день. Выводится только одна строка, содержащая общий объем продаж по каждому дню.
Е. Базовое использование указания DISTRIBUTED_AGG
В этом примере показано указание запроса DISTRIBUTED_AGG для принудительного перемещения в таблице по столбцу CustomerKey перед выполнением статистического вычисления.
Ж. Варианты синтаксиса для GROUP BY
Если в списке Select статистические вычисления, каждый столбец в списке Select должен быть включен в список GROUP BY. Вычисляемые столбцы в списке Select можно указать в списке GROUP BY (делать это необязательно). Ниже приведены примеры синтаксически правильных инструкций SELECT.
З. Использование GROUP BY с несколькими выражениями GROUP BY
И. Использование предложения GROUP BY с предложением HAVING
Transact-SQL группировка данных GROUP BY
Мы с Вами рассмотрели много материала по SQL, в частности Transact-SQL, но мы не затрагивали такую, на самом деле простую тему как группировка данных GROUP BY. Поэтому сегодня мы научимся использовать оператор group by для группировки данных.

И для вступления небольшая теория.
Что такое оператор GROUP BY
GROUP BY – это оператор (или конструкция, кому как удобней) SQL для группировки данных по полю, при использовании в запросе агрегатных функций, таких как sum, max, min, count и других.
Как Вы знаете, агрегатные функции работают с набором значений, например sum суммирует все значения. А вот допустим, Вам необходимо просуммировать по какому-то условию или сразу по нескольким условиям, именно для этого нам нужен оператор group by, чтобы сгруппировать все данные по полям с выводом результатов агрегатных функций.
Как мне кажется, наглядней будет это все разобрать на примерах, поэтому давайте перейдем к примерам.
Примечание! Все примеры будем писать в Management Studio SQL сервера 2008.
Примеры использования оператора GROUP BY
И для начала давайте создадим и заполним тестовую таблицу с данными, которой мы будет посылать наши запросы select с использованием группировки group by. Таблица и данные конечно выдуманные, чисто для примера.
Создаем таблицу
Я ее заполнил следующими данными:
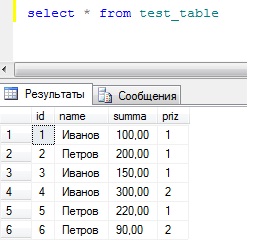
Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям
Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
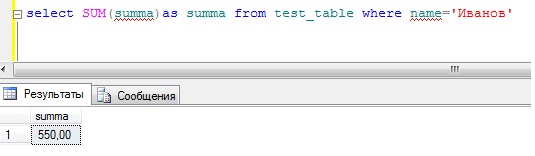
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
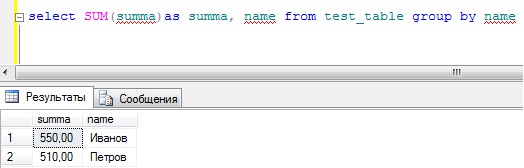
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Примечание! Сразу отмечу то, что, сколько полей мы пишем в запросе (т.е. поля группировки), помимо агрегатных функций, столько же полей мы пишем в конструкции group by. В нашем примере мы выводим одно поле, поэтому в group by мы указали только одно поле (name), если бы мы выводили несколько полей, то их все пришлось бы указывать в конструкции group by (в последующих примерах Вы это увидите).
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств. Для этого мы кроме функции sum будем еще использовать функцию count.
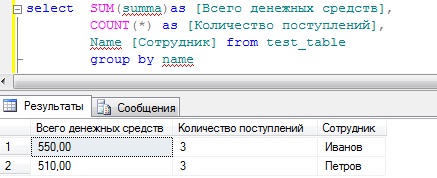
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т.е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
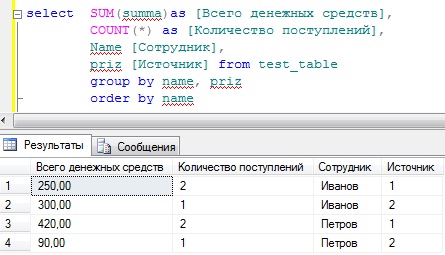
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
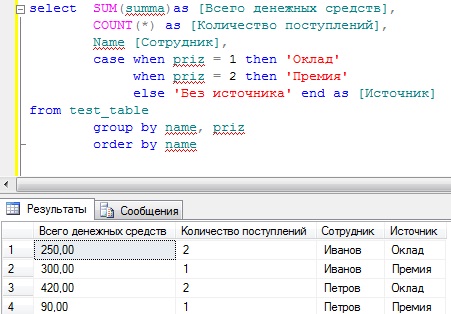
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count. Например, нам нужно вывести все то же самое, но только тех, у которых «всего денежных средств» больше 200. Для этого добавим условие having:
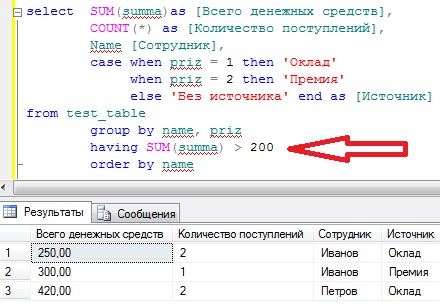
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Надеюсь, после сегодняшнего урока Вам стало понятно, как и зачем использовать конструкцию group by. Удачи! А SQL мы продолжим изучать в следующих статьях.



