Оценка классификатора (точность, полнота, F-мера)
Продолжая тему реализации автоматической классификации необходимо обсудить следующий очень важный вопрос. Как оценивать качество алгоритма? Допустим, вы хотите внести изменения в алгоритм. Откуда вы знаете что эти изменения сделают алгоритм лучше? Конечно же надо проверять алгоритм на реальных данных.
Тестовая выборка
Основой проверки является тестовая выборка в которой проставлено соответствие между документами и их классами. В зависимости от ваших конкретных условий получение подобной выборки может быть затруднено, так как зачастую ее составляют люди. Но иногда ее можно получить без большого объема ручной работы, если проявить изобретательность. Каких-то конеретных рецептов, к сожалению, не существует.
Когда у вас появилась тестовая выборка достаточно натравить классификатор на документы и соотнести его решение с заведомо известным правильным решением. Но для того чтобы принимать решение хуже или лучше справляется с работой новая версия алгоритма нам необходима численная метрика его качества.
Численная оценка качества алгоритма
Accuracy
В простейшем случае такой метрикой может быть доля документов по которым классификатор принял правильное решение.
где, – количество документов по которым классификатор принял правильное решение, а – размер обучающей выборки. Очевидное решение, на котором для начала можно остановиться.
Тем не менее, у этой метрики есть одна особенность которую необходимо учитывать. Она присваивает всем документам одинаковый вес, что может быть не корректно в случае если распределение документов в обучающей выборке сильно смещено в сторону какого-то одного или нескольких классов. В этом случае у классификатора есть больше информации по этим классам и соответственно в рамках этих классов он будет принимать более адекватные решения. На практике это приводит к тому, что вы имеете accuracy, скажем, 80%, но при этом в рамках какого-то конкретного класса классификатор работает из рук вон плохо не определяя правильно даже треть документов.
Один выход из этой ситуации заключается в том чтобы обучать классификатор на специально подготовленном, сбалансированном корпусе документов. Минус этого решения в том что вы отбираете у классификатора информацию об отностельной частоте документов. Эта информация при прочих равных может оказаться очень кстати для принятия правильного решения.
Другой выход заключается в изменении подхода к формальной оценке качества.
Точность и полнота
Точность (precision) и полнота (recall) являются метриками которые используются при оценке большей части алгоритмов извлечения информации. Иногда они используются сами по себе, иногда в качестве базиса для производных метрик, таких как F-мера или R-Precision. Суть точности и полноты очень проста.
Точность системы в пределах класса – это доля документов действительно принадлежащих данному классу относительно всех документов которые система отнесла к этому классу. Полнота системы – это доля найденных классфикатором документов принадлежащих классу относительно всех документов этого класса в тестовой выборке.
Эти значения легко рассчитать на основании таблицы контингентности, которая составляется для каждого класса отдельно.
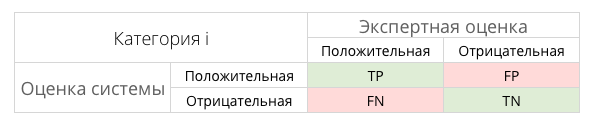
В таблице содержится информация сколько раз система приняла верное и сколько раз неверное решение по документам заданного класса. А именно:
Тогда, точность и полнота определяются следующим образом:
Рассмотрим пример. Допустим, у вас есть тестовая выборка в которой 10 сообщений, из них 4 – спам. Обработав все сообщения классификатор пометил 2 сообщения как спам, причем одно действительно является спамом, а второе было помечено в тестовой выборке как нормальное. Мы имеем одно истино-положительное решение, три ложно-отрицательных и одно ложно-положительное. Тогда для класса “спам” точность классификатора составляет (50% положительных решений правильные), а полнота (классификатор нашел 25% всех спам-сообщений).
Confusion Matrix
На практике значения точности и полноты гораздо более удобней рассчитывать с использованием матрицы неточностей (confusion matrix). В случае если количество классов относительно невелико (не более 100-150 классов), этот подход позволяет довольно наглядно представить результаты работы классификатора.
Матрица неточностей – это матрица размера N на N, где N — это количество классов. Столбцы этой матрицы резервируются за экспертными решениями, а строки за решениями классификатора. Когда мы классифицируем документ из тестовой выборки мы инкрементируем число стоящее на пересечении строки класса который вернул классификатор и столбца класса к которому действительно относится документ.

Матрица неточностей (26 классов, результирующая точность – 0.8, результирующая полнота – 0.91)
Как видно из примера, большинство документов классификатор определяет верно. Диагональные элементы матрицы явно выражены. Тем не менее в рамках некоторых классов (3, 5, 8, 22) классификатор показывает низкую точность.
Имея такую матрицу точность и полнота для каждого класса рассчитывается очень просто. Точность равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота – отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
F-мера
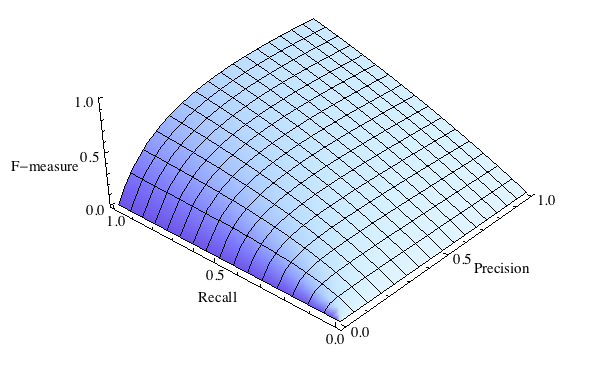
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма.
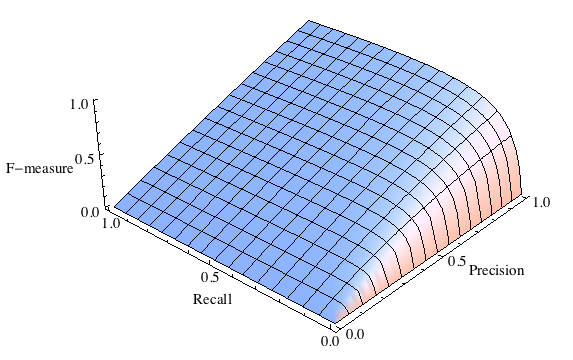
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют F1).
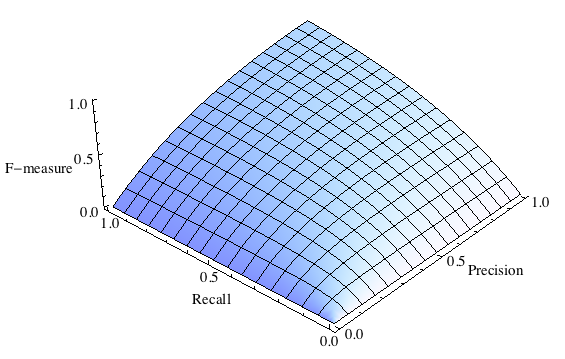
F-мера с приоритетом точности ()
F-мера с приоритетом полноты ()
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея в своем распоряжении подобный механизм оценки вам будет гораздо проще принять решение о том являются ли изменения в алгоритме в лучшую сторону или нет.
Ссылки по теме
иногда встречаются названия: F-score или мера Ван Ризбергена. ↩
Оценка качества в задачах классификации и регрессии
В машинном обучении различают оценки качества для задачи классификации и регрессии. Причем оценка задачи классификации часто значительно сложнее, чем оценка регрессии.
Содержание
Оценки качества классификации [ править ]
Матрица ошибок (англ. Сonfusion matrix) [ править ]
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок). Допустим, что у нас есть два класса [math]y = \< 0, 1 \>[/math] и алгоритм, предсказывающий принадлежность каждого объекта одному из классов. Рассмотрим пример. Пусть банк использует систему классификации заёмщиков на кредитоспособных и некредитоспособных. При этом первым кредит выдаётся, а вторые получат отказ. Таким образом, обнаружение некредитоспособного заёмщика ( [math]y = 1 [/math] ) можно рассматривать как «сигнал тревоги», сообщающий о возможных рисках.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
Несложно увидеть, что эти ошибки неравноценны по связанным с ними проблемам. В случае «ложной тревоги» потери банка составят только проценты по невыданному кредиту (только упущенная выгода). В случае «пропуска цели» можно потерять всю сумму выданного кредита. Поэтому системе важнее не допустить «пропуск цели», чем «ложную тревогу».
Таким образом, ошибка I рода, или ложно-положительный исход классификации, имеет место, когда отрицательное наблюдение распознано моделью как положительное. Ошибкой II рода, или ложно-отрицательным исходом классификации, называют случай, когда положительное наблюдение распознано как отрицательное. Поясним это с помощью матрицы ошибок классификации:
| [math]y = 1[/math] | [math]y = 0[/math] | |
| [math]a ( x ) = 1[/math] | Истинно-положительный (True Positive — TP) | Ложно-положительный (False Positive — FP) |
| [math]a ( x ) = 0[/math] | Ложно-отрицательный (False Negative — FN) | Истинно-отрицательный (True Negative — TN) |
Здесь [math]a ( x )[/math] — это ответ алгоритма на объекте, а [math]y [/math] — истинная метка класса на этом объекте. Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP). P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T значит что класс предсказан правильно (соответственно F — неправильно). Каждая строка в матрице ошибок представляет спрогнозированный класс, а каждый столбец — фактический класс.
Безупречный классификатор имел бы только истинно-положительные и истинно отрицательные классификации, так что его матрица ошибок содержала бы ненулевые значения только на своей главной диагонали (от левого верхнего до правого нижнего угла):
Аккуратность (англ. Accuracy) [ править ]
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:
Эта метрика бесполезна в задачах с неравными классами, что как вариант можно исправить с помощью алгоритмов сэмплирования и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5). Тогда accuracy:
[math] accuracy = \dfrac<5+90> <5+90+10+5>= 86,4 [/math]
Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую аккуратность:
[math] accuracy = \dfrac<0+100> <0+100+0+10>= 90,9 [/math]
При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
Точность (англ. Precision) [ править ]
Точностью (precision) называется доля правильных ответов модели в пределах класса — это доля объектов действительно принадлежащих данному классу относительно всех объектов которые система отнесла к этому классу.
[math] Precision = \dfrac
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive.
Полнота (англ. Recall) [ править ]
Полнота — это доля истинно положительных классификаций. Полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
[math] Recall = \dfrac
Полнота (recall) демонстрирует способность алгоритма обнаруживать данный класс вообще.
Имея матрицу ошибок, очень просто можно вычислить точность и полноту для каждого класса. Точность (precision) равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота (recall) — отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
F-мера (англ. F-score) [ править ]
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок. Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в производство (у кого больше тот и круче). Именно такой метрикой является F-мера.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма:
где [math]β[/math] принимает значения в диапазоне [math]0\lt β\lt 1[/math] если вы хотите отдать приоритет точности, а при [math]β\gt 1[/math] приоритет отдается полноте. При [math]β=1[/math] формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют [math]F_1[/math] ).
Как мы искали компромисс между точностью и полнотой в конкретной задаче ML

Я расскажу о практическом примере того, как мы формулировали требования к задаче машинного обучения и выбирали точку на кривой точность/полнота. Разрабатывая систему автоматической модерации контента, мы столкнулись с проблемой выбора компромисса между точностью и полнотой, и решили ее с помощью несложного, но крайне полезного эксперимента по сбору асессорских оценок и вычисления их согласованности.
Мы в HeadHunter используем машинное обучение для создания пользовательских сервисов. ML — это «модно, стильно, молодежно…», но, в конце концов, это лишь один из возможных инструментов решения бизнес-задач, и этим инструментом нужно правильно пользоваться.
Постановка задачи
Если предельно упрощать, то разработка сервиса — это инвестиции денег компании. А разработанный сервис должен приносить прибыль (возможно, косвенно — например, увеличивая лояльность пользователей). Разработчики же моделей машинного обучения, как вы понимаете, оценивают качество своей работы несколько в других терминах (например, accuracy, ROC-AUC и так далее). Соответственно, нужно каким-то образом переводить требования бизнеса, например, в требования к качеству моделей. Это позволяет в том числе не увлекаться улучшением модели там, где «не надо». То есть с точки зрения бухгалтерии — меньше инвестировать, а с точки зрения разработки продукта — делать то, что действительно полезно пользователям. На одной конкретной задаче я расскажу о том, как довольно простым образом мы устанавливали требования к качеству модели.
Одна из частей нашего бизнеса заключается в том, что мы предоставляем пользователям-соискателям набор сервисов для создания электронного резюме, а пользователям-работодателям — удобные (в большинстве своем платные) способы работы с этими резюме. В связи с этим нам крайне важно обеспечивать высокое качество базы резюме именно с точки зрения восприятия менеджерами по персоналу. Например, в базе не просто не должно быть спама, но и всегда должно быть указано последнее место работы. Поэтому у нас есть специальные модераторы, которые проверяют качество каждого резюме. Количество новых резюме непрерывно растет (что, само по себе, нас очень радует), но одновременно растет нагрузка на модераторов. У нас возникла простая идея: накоплены исторические данные, давайте же обучим модель, которая сможет отличать резюме, допустимые к публикации, от резюме, требующих доработки. На всякий случай поясню, что, если резюме «требует доработки», у пользователя ограничены возможности использования данного резюме, он видит причину этого и может все поправить.
Я не буду сейчас описывать увлекательный процесс сбора исходных данных и построения модели. Возможно, те коллеги, кто это делал, рано или поздно поделятся своим опытом. Как бы то ни было, в итоге у нас получилась модель с таким качеством:

По вертикальной оси отложена точность (precision), или доля верно принимаемых моделью резюме. По горизонтальной оси — соответствующая полнота (recall), или доля принимаемых моделью резюме от общего числа «допустимых к публикации» резюме. Все, что не принимается моделью, принимается людьми. У бизнеса есть две противоположные цели: хорошая база (наименьшая доля «недостаточно хороших» резюме) и стоимость модерации (как можно больше резюме принимать автоматически, при этом чем меньше стоимость разработки — тем лучше).
Хорошая или плохая модель получилась? Нужно ли ее улучшать? А если не нужно, то какой порог (threshold), то есть какую точку на кривой выбрать: какой компромисс между точностью и полнотой устраивает бизнес? Сначала я отвечал на этот вопрос довольно туманными построениями в духе «хотим 98% точности, а 40% полноты — казалось бы, вполне неплохо». Обоснование для подобных «продуктовых требований», конечно, существовало, но настолько зыбкое, что недостойно помещения в печать. И первая версия модели вышла именно в таком виде.
Эксперимент с асессорами
Все довольны и счастливы, и дальше возникает вопрос: а давайте автоматическая система будет принимать еще больше резюме! Очевидно, этого можно достичь двумя способами: улучшить модель, или, например, выбрать другую точку на вышеприведенной кривой (ухудшить точность в угоду полноте). Что же мы сделали для того, чтобы более осознанным образом сформулировать продуктовые требования?
Мы предположили, что на самом деле люди (модераторы) тоже могут ошибаться, и провели эксперимент. Четверым случайным модераторам было предложено разметить (независимо друг от друга) одну и ту же выборку резюме на тестовом стенде. При этом был полностью воспроизведен рабочий процесс (эксперимент ничем не отличался от обычного рабочего дня). В формировании выборки же была хитрость. Для каждого модератора мы взяли N случайных резюме, уже им обработанных (то есть итоговый размер выборки получился 4N).
Итак, для каждого резюме мы собрали 4 независимых решения модераторов (0 или 1), решение модели (вещественное число от 0 до 1) и исходное решение одного из этих четверых модераторов (опять же 0 или 1). Первое, что можно сделать — посчитать среднюю «самосогласованность» решений модераторов (она получилась около 90%). Дальше можно более точно оценить «качество» резюме (оценку «опубликовать» или «не публиковать»), например, методом мнения большинства (majority vote). Наши предположения следующие: у нас есть «исходная оценка модератора» и «исходная оценка робота» плюс три оценки независимых модераторов. По трем оценкам всегда будет существовать мнение большинства (если бы оценок было четыре, то при голосовании 2:2 можно было бы выбирать решение случайным образом). В результате мы можем оценить точность «среднего модератора» — она опять же оказывается около 90%. Наносим точку на нашу кривую и видим, что модель обеспечит такую же ожидаемую точность при полноте более 80% (в итоге мы стали автоматически обрабатывать в 2 раза больше резюме при минимальных затратах).
Выводы и спойлер
На самом деле, пока мы думали над тем, как построить процесс приемки качества системы автоматической модерации, мы натолкнулись еще на несколько камней, которые я попробую описать в следующий раз. Пока же на достаточно простом примере, надеюсь, мне удалось проиллюстрировать пользу асессорской разметки и простоту построения таких экспериментов, даже если у вас под рукой нет «Яндекс.Толоки», а также то, насколько неожиданными могут оказаться результаты. В данном конкретном случае мы выяснили, что для решения бизнес-задачи вполне достаточно точности 90%, то есть до того, как улучшать модель, стоит потратить некоторое время на изучение реальных бизнес-процессов.
И в заключение хотел бы выразить свою признательность Роману Поборчему p0b0rchy за консультации нашей команды в ходе работы.
Метрики в задачах машинного обучения

В задачах машинного обучения для оценки качества моделей и сравнения различных алгоритмов используются метрики, а их выбор и анализ — непременная часть работы датасатаниста.
В этой статье мы рассмотрим некоторые критерии качества в задачах классификации, обсудим, что является важным при выборе метрики и что может пойти не так.
Метрики в задачах классификации
Для демонстрации полезных функций sklearn и наглядного представления метрик мы будем использовать датасет по оттоку клиентов телеком-оператора.
Accuracy, precision и recall
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов, тогда матрица ошибок классификации будет выглядеть следующим образом:
 |  | |
|---|---|---|
 | True Positive (TP) | False Positive (FP) |
 | False Negative (FN) | True Negative (TN) |
Здесь  — это ответ алгоритма на объекте, а
— это ответ алгоритма на объекте, а  — истинная метка класса на этом объекте.
— истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
Accuracy
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:

Эта метрика бесполезна в задачах с неравными классами, и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:

Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую accuracy:

При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
Precision, recall и F-мера
Для оценки качества работы алгоритма на каждом из классов по отдельности введем метрики precision (точность) и recall (полнота).


Precision можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющимися положительными, а recall показывает, какую долю объектов положительного класса из всех объектов положительного класса нашел алгоритм.
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive. Recall демонстрирует способность алгоритма обнаруживать данный класс вообще, а precision — способность отличать этот класс от других классов.
Как мы отмечали ранее, ошибки классификации бывают двух видов: False Positive и False Negative. В статистике первый вид ошибок называют ошибкой I-го рода, а второй — ошибкой II-го рода. В нашей задаче по определению оттока абонентов, ошибкой первого рода будет принятие лояльного абонента за уходящего, так как наша нулевая гипотеза состоит в том, что никто из абонентов не уходит, а мы эту гипотезу отвергаем. Соответственно, ошибкой второго рода будет являться «пропуск» уходящего абонента и ошибочное принятие нулевой гипотезы.
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Классическим примером является задача определения оттока клиентов.
Очевидно, что мы не можем находить всех уходящих в отток клиентов и только их. Но, определив стратегию и ресурс для удержания клиентов, мы можем подобрать нужные пороги по precision и recall. Например, можно сосредоточиться на удержании только высокодоходных клиентов или тех, кто уйдет с большей вероятностью, так как мы ограничены в ресурсах колл-центра.
Обычно при оптимизации гиперпараметров алгоритма (например, в случае перебора по сетке GridSearchCV ) используется одна метрика, улучшение которой мы и ожидаем увидеть на тестовой выборке.
Существует несколько различных способов объединить precision и recall в агрегированный критерий качества. F-мера (в общем случае  ) — среднее гармоническое precision и recall :
) — среднее гармоническое precision и recall :

 в данном случае определяет вес точности в метрике, и при
в данном случае определяет вес точности в метрике, и при  это среднее гармоническое (с множителем 2, чтобы в случае precision = 1 и recall = 1 иметь
это среднее гармоническое (с множителем 2, чтобы в случае precision = 1 и recall = 1 иметь  )
)
F-мера достигает максимума при полноте и точности, равными единице, и близка к нулю, если один из аргументов близок к нулю.
В sklearn есть удобная функция _metrics.classificationreport, возвращающая recall, precision и F-меру для каждого из классов, а также количество экземпляров каждого класса.
| class | precision | recall | f1-score | support |
|---|---|---|---|---|
| Non-churned | 0.88 | 0.97 | 0.93 | 941 |
| Churned | 0.60 | 0.25 | 0.35 | 159 |
| avg / total | 0.84 | 0.87 | 0.84 | 1100 |
Здесь необходимо отметить, что в случае задач с несбалансированными классами, которые превалируют в реальной практике, часто приходится прибегать к техникам искусственной модификации датасета для выравнивания соотношения классов. Их существует много, и мы не будем их касаться, здесь можно посмотреть некоторые методы и выбрать подходящий для вашей задачи.
AUC-ROC и AUC-PR
При конвертации вещественного ответа алгоритма (как правило, вероятности принадлежности к классу, отдельно см. SVM) в бинарную метку, мы должны выбрать какой-либо порог, при котором 0 становится 1. Естественным и близким кажется порог, равный 0.5, но он не всегда оказывается оптимальным, например, при вышеупомянутом отсутствии баланса классов.
Одним из способов оценить модель в целом, не привязываясь к конкретному порогу, является AUC-ROC (или ROC AUC) — площадь (Area Under Curve) под кривой ошибок (Receiver Operating Characteristic curve ). Данная кривая представляет из себя линию от (0,0) до (1,1) в координатах True Positive Rate (TPR) и False Positive Rate (FPR):


TPR нам уже известна, это полнота, а FPR показывает, какую долю из объектов negative класса алгоритм предсказал неверно. В идеальном случае, когда классификатор не делает ошибок (FPR = 0, TPR = 1) мы получим площадь под кривой, равную единице; в противном случае, когда классификатор случайно выдает вероятности классов, AUC-ROC будет стремиться к 0.5, так как классификатор будет выдавать одинаковое количество TP и FP.
Каждая точка на графике соответствует выбору некоторого порога. Площадь под кривой в данном случае показывает качество алгоритма (больше — лучше), кроме этого, важной является крутизна самой кривой — мы хотим максимизировать TPR, минимизируя FPR, а значит, наша кривая в идеале должна стремиться к точке (0,1).
Критерий AUC-ROC устойчив к несбалансированным классам (спойлер: увы, не всё так однозначно) и может быть интерпретирован как вероятность того, что случайно выбранный positive объект будет проранжирован классификатором выше (будет иметь более высокую вероятность быть positive), чем случайно выбранный negative объект.
Рассмотрим следующую задачу: нам необходимо выбрать 100 релевантных документов из 1 миллиона документов. Мы намашинлернили два алгоритма:



Скорее всего, мы бы выбрали первый алгоритм, который выдает очень мало False Positive на фоне своего конкурента. Но разница в False Positive Rate между этими двумя алгоритмами крайне мала — всего 0.0019. Это является следствием того, что AUC-ROC измеряет долю False Positive относительно True Negative и в задачах, где нам не так важен второй (больший) класс, может давать не совсем адекватную картину при сравнении алгоритмов.
Для того чтобы поправить положение, вернемся к полноте и точности :




Здесь уже заметна существенная разница между двумя алгоритмами — 0.855 в точности!
Precision и recall также используют для построения кривой и, аналогично AUC-ROC, находят площадь под ней.
Здесь можно отметить, что на маленьких датасетах площадь под PR-кривой может быть чересчур оптимистична, потому как вычисляется по методу трапеций, но обычно в таких задачах данных достаточно. За подробностями о взаимоотношениях AUC-ROC и AUC-PR можно обратиться сюда.
Logistic Loss
Особняком стоит логистическая функция потерь, определяемая как:

здесь — это ответ алгоритма на  -ом объекте, — истинная метка класса на -ом объекте, а
-ом объекте, — истинная метка класса на -ом объекте, а  размер выборки.
размер выборки.
Подробно про математическую интерпретацию логистической функции потерь уже написано в рамках поста про линейные модели.
Данная метрика нечасто выступает в бизнес-требованиях, но часто — в задачах на kaggle.
Интуитивно можно представить минимизацию logloss как задачу максимизации accuracy путем штрафа за неверные предсказания. Однако необходимо отметить, что logloss крайне сильно штрафует за уверенность классификатора в неверном ответе.
Отметим, как драматически выросла logloss при неверном ответе и уверенной классификации!
Следовательно, ошибка на одном объекте может дать существенное ухудшение общей ошибки на выборке. Такие объекты часто бывают выбросами, которые нужно не забывать фильтровать или рассматривать отдельно.
Всё становится на свои места, если нарисовать график logloss:
Видно, что чем ближе к нулю ответ алгоритма при ground truth = 1, тем выше значение ошибки и круче растёт кривая.
Подытожим:
Полезные ссылки
Благодарности
Спасибо mephistopheies и madrugado за помощь в подготовке статьи.



