ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Установка и настройка Docker Swarm
кластеризация, такая кластеризация
В этой статье мы рассмотрим процесс установки и настройки режима Docker Swarm на сервере Ubuntu 16.04.

Docker Swarm является стандартным инструментом кластеризации для Docker, преобразующий набор хостов Docker в один последовательный кластер, называемый Swarm. Docker Swarm обеспечивает доступность и высокую производительность работы, равномерно распределяя ее по хостингам Docker внутри кластера.

Установка Docker Swarm:
Перед началом обновите Ваш системный репозиторий до последней версии с помощью следующей команды:
После обновления следует выполнить перезагрузку системы. Необходимо еще установить среду Docker. По умолчанию Docker не доступен в репозитории Ubuntu 16.04, поэтому сначала необходимо создать хранилище Docker и начать установку с помощью следующей команды:
Добавляем GPG ключ для Docker:
Добавляем репозиторий Docker и обновляем с помощью команды:
Установка среды Docker с помощью следующей команды:
После установки запустите службу Docker во время загрузки с помощью следующей команды:
Для запуска Docker необходимы root права, а для других юзеров доступ получается только с помощью sudo. При необходимости запустить docker без использования sudo, есть возможность создать Unix и включить в него необходимых пользователей за счет выполнения следующих строк кода:
Затем выйдя из системы, делаем вход через dockeruser.
Затем перезагрузите брандмауэр, включив его при загрузке
Выполните перезагрузку “Докера”:
Создавая Docker Swarm кластер, необходимо определиться с IP-адресом, за счет которого ваш узел будет действовать в качестве диспетчера:
Вы должны увидеть следующий вывод:
Проверяем его состояние:
Если все работает правильно, вы должны увидеть следующий вывод:
Проверка статуса Docker Swarm Cluster осуществляется следующим образом:
Вывод должен быть следующим:
Узел теперь настроен правильно, пришло время добавить его в Swarm Cluster. Сначала скопируйте вывод команды «swarm init» из вывода результата выше, а затем вставьте этот вывод в рабочий узел для присоединения к Swarm Cluster:
Вы должны увидеть следующий вывод:
Теперь выполните следующую команду для вывода списка рабочего узла:
Вы должны увидеть информацию следующего вида:
Docker Swarm Cluster запущен и работает, теперь можно запустить веб-сервис в Docker Swarm Mode. За счет следующей строки кода выполнится развертывание службы веб-сервера:
Приведенная выше строка создаст контейнер веб-сервера Apache и сопоставит его с 80 портом, позволив иметь полный доступ к необходимому веб-серверу Apache из удаленной системы. Теперь запускаем проверку работающего сервиса с помощью команды:
Вы должны увидеть следующий вывод:
Запустите службу масштабирования веб-сервера с помощью строки:
А также проверьте состояние с помощью команды:
Вы должны увидеть следующий вывод:
Веб-сервер Apache работает. Теперь вы можете получить доступ к веб-серверу:

Служба веб-сервера Apache теперь распределена по двум узлам. Docker Swarm обеспечивает доступность вашего сервиса. Если веб-сервер отключается на рабочем узле, то новый контейнер будет запущен на узле менеджера. Для проверки доступности следует остановить службу Docker на рабочем узле:
Запустите службу веб-сервера с помощью команды:
Вы должны увидеть следующую информацию:
С помощью данной статьи, вы смогли установить и настроить кластер Docker Swarm для ОС Ubuntu 16.04. Теперь вы можете легко масштабировать свое приложение в кластере до тысячи узлов и пятидесяти тысяч контейнеров без существенной потери производительности.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Чем полезен Docker Swarm и в каких случаях лучше использовать Kubernetes
Технология контейнеризации позволяет запускать приложения в отдельных независимых средах — контейнерах. Они упрощают развертывание приложений, изолируют их друг от друга и ускоряют разработку. Но когда контейнеров становится слишком много, ими трудно управлять. Тут на помощь приходят системы оркестровки.
В статье разберем, чем может быть полезен Docker Swarm и в каких случаях стоит присмотреться к более продвинутым решениям.
Что такое Docker Swarm и чем он может быть полезен
При построении крупной продакшн-системы в нее обязательно закладывают требования по отказоустойчивости, производительности и масштабируемости. То есть система должна быть защищена от сбоев, не тормозить и иметь возможность для увеличения мощности.
Обычно для этого создают кластер — отдельностоящие хосты (серверы) объединяют под общим управлением, со стороны это выглядит как единая система. При этом она намного устойчивее к сбоям и производительнее:
При работе с контейнерами эти задачи решают системы оркестровки. Оркестровка — это управление и координация взаимодействия между контейнерами. Контейнеры запускаются на хостах, а хосты объединяют в кластер.
У Docker есть стандартный инструмент оркестровки — Docker Swarm Mode, или просто Docker Swarm. Он поставляется «из коробки», довольно прост в настройке и позволяет создать простой кластер буквально за минуту.
Кластер Swarm (Docker Swarm Cluster) состоит из нод, которые делят на два типа:
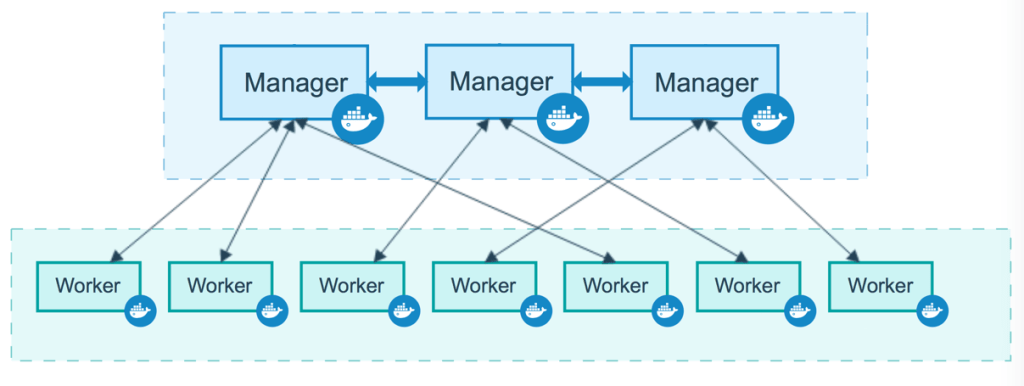
Схематичное устройство кластера Docker Swarm: три управляющих ноды и семь рабочих. Источник
В Docker Swarm вместо прямого использования контейнеров используются сервисы (Docker Swarm Service). Они похожи на контейнеры, но всё же это немного другое понятие.
Сервис — это что-то вроде уровня абстракции над контейнерами. В Swarm мы не запускаем контейнеры явно — этим занимаются сервисы. Для достижения отказоустойчивости мы лишь указываем сервису количество реплик — нод, на которых он должен запустить контейнеры. А Swarm уже сам проследит за тем, чтобы это требование выполнялось: найдет подходящие хосты, запустит контейнеры и будет следить за ними. Если один из хостов отвалится — создаст новую реплику на другом хосте.
Что такое Kubernetes и в чем его преимущества перед Swarm
Кроме стандартного Docker Swarm есть и другие инструменты оркестровки, например Kubernetes. Это сложная система, которая позволяет построить отказоустойчивую и масштабируемую платформу для управления контейнерами. Он умеет работать не только с контейнерами Docker, но и с другими контейнерами: rkt, CRI-O.
У Kubernetes довольно много возможностей, которые позволяют строить масштабные распределенные системы. Из-за этого порог вхождения в технологию гораздо выше, чем в Swarm. Нужно обладать определенным уровнем знаний, а на первоначальную установку и настройку может уйти несколько дней.
Если смотреть глобально, то устройство Kubernetes похоже на Swarm. Кластер состоит из двух типов нод: главной (Master) и рабочих (Worker):
Но если смотреть глубже, то устройство Kubernetes гораздо сложнее. В нем отдельные модули, например: proxy-балансировщик, etcd для хранения состояния кластера и другие компоненты. Не будем подробно всё это описывать. Достаточно понять, что Kubernetes устроен гораздо сложнее, чем Docker Swarm.

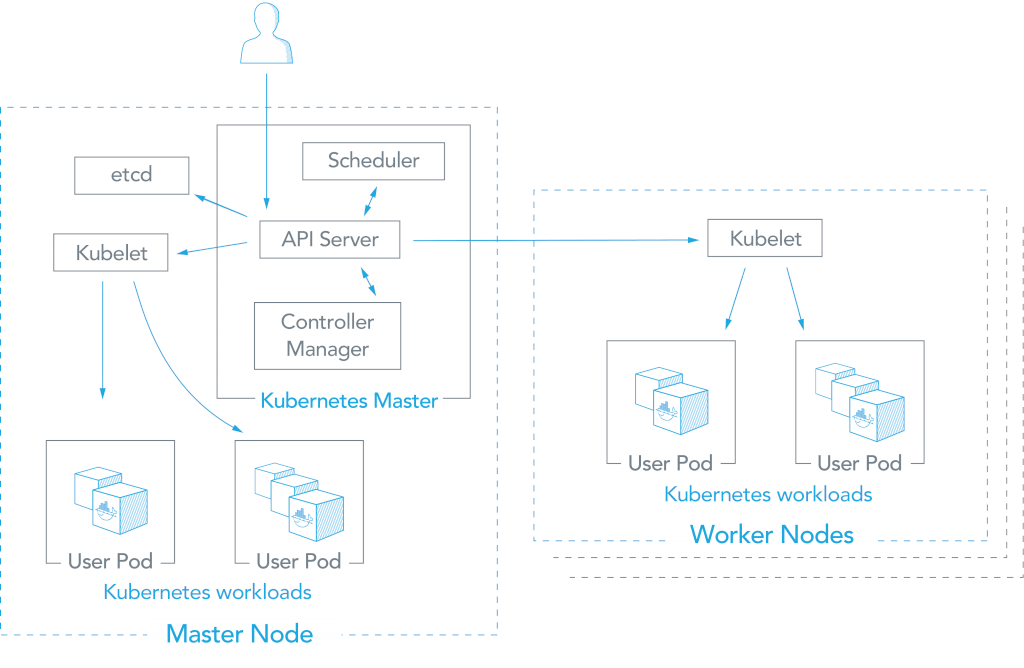
Глобально Kubernetes похож на Swarm. Но внутри все гораздо сложнее. Источник
Так зачем нужен Kubernetes со своими сложностями, когда уже есть «родной» и простой Docker Swarm?
Дело в том, что Kubernetes позволяет решать задачи, которые не под силу Docker Swarm. Для примера возьмем автомасштабирование: это когда система сама подстраивает свою мощность под нагрузку. Для этого в кластер автоматически добавляются/удаляются ноды, либо в существующих нодах для «тяжелых» задач будет выделяться больше/меньше ресурсов.
Но если система умеет масштабироваться, она отреагирует на возросшую нагрузку и увеличит ресурсы для этих задач. А когда нагрузка спадет, снова освободит эти мощности. Если кластер размещен в облаке, автомасштабирование сильно экономит деньги. В моменты простоя неиспользуемые ресурсы освобождаются, и за них не нужно переплачивать.
Так вот, в Kubernetes можно настроить автомасштабирование. Да, придется написать конфигурационный файл и выполнить другие настройки, но в результате вы получите рабочую и стабильную систему. А если развернуть кластер в облаке, которое поддерживает автомасштабирование, то на настройку уйдет всего несколько минут.
Docker Swarm не умеет делать этого «из коробки». Можно построить автомасштабируемую систему с использованием Swarm. Но для этого придется вручную писать скрипты или программы, которые будут следить за нагрузкой, принимать решения и посылать команды в Docker Swarm. Либо можно использовать сторонние разработки, вроде Orbiter, но его возможности тоже ограничены, и в любом случае это еще одна дополнительная надстройка над Swarm.
Теперь представьте, что кроме автомасштабирования у вас есть другие задачи, для которых приходится городить кучу инструментов над Swarm. Всё это нужно поддерживать, понимать как оно работает и тщательно тестировать при обновлениях. В Kubernetes такие сложности спрятаны внутри, и они стабильно работают.
Docker Swarm: знакомство
Visitors have accessed this post 5711 times.
Автор — Максим Рязанов
Всех приветствую! В этой статье я расскажу о Docker Swarm, его возможностях и основах взаимодействия с ним.
Пройдемся по следующим основным пунктам:
Для примера будут использоваться три виртуальные машины под управлением Debian 10, развернутые на моем компьютере. Все команды, перечисленные в статье, будут выполняться от имени пользователя root, а управление виртуальными машинами — с помощью команд libvirt.
Эта статья подготовлена с использованием материалов c docs.docker.com и открытого практикума Rebrain Docker Swarm 09.04.2020.
Итак, что такое Docker Swarm и причем тут, собственно, рой (swarm — англ. рой)? В этом режиме Docker можно запустить контейнеры на нескольких хостах, объединив их в общем пуле вычислительных ресурсов. При этом наблюдать за контейнерами, распределять их и поднимать в случае необходимости будет сам Docker. По умолчанию docker swarm выключен.
Как создать кластер Docker-контейнеров с помощью Docker Swarm
Наше построение кластера начнем с изучения скромного количества понятий о кластере Docker Swarm. Как и в любом другом кластере, в кластере docker swarm должны быть ноды, из которых кластер и будет состоять. У нод в кластере может быть две роли:
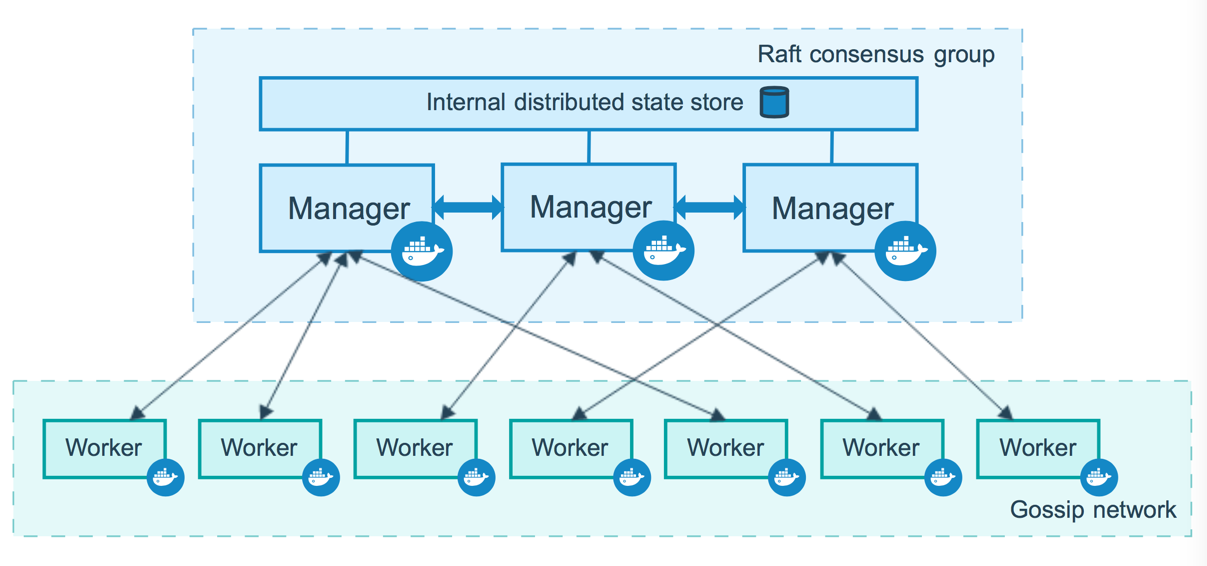
Приступим к знакомству на практике.
Для начала я разверну на своем компьютере виртуальные машины под управлением Debian 10 из заранее заготовленного шаблона с помощью libvirt. Libvirt — замечательный инструмент и помощник администратора виртуализации, который позволяет управлять множеством решений (поддерживает KVM, ESX, OpenVZ, lxc и т.д.) одними и теми же инструментами.
Развертка трех виртуальных машин будет состоять из трех последовательных команд:
В первой мы указываем утилите virt-clone взять за основу виртуальную машину debian10template, создать новую с именем swr1, в качестве файла диска для хранения данных скопировать существующий в /storage/dataspace_sata/swr1.qcow2. Остальные команды можно разобрать по аналогии.Для запуска используем следующие команды:
Далее я проверю IP-адреса, выданные этим виртуальным машинам. Они у меня находятся в изолированной локальной сети с именем locnet на хосте.
После на имеющемся у меня в сети powerdns сервере (с которым мы познакомились ранее в статье) я создам каждой ноде по доменному имени для удобства:
Затем выполним установку Docker Engine на эти три тестовые ноды, которые я буду использовать далее. Это можно сделать с помощью официальных инструкций для Ubuntu или Debian (они есть и для других дистрибутивов). Рекомендую ознакомиться с инструкцией под ваш дистрибутив, но для установки на 3 ноды сразу, абстрагируясь от дистрибутива, я подготовил универсальный playbook для ansible, который справится с установкой docker-ce из официального репозитория и на Debian, и на Ubuntu.
Имейте в виду, что при развертке docker на VDS с публичными IP-адресами хорошей практикой настройка правил брандмауэра для разрешения трафика docker swarm (iptables, firewalld, ufw) на каждом сервере перед созданием кластера. Для успешного создания кластера необходимо, чтобы каждый VDS мог связаться друг с другом по следующим протоколам и портам:
Займемся наконец созданием swarm кластера.
Инициализация первого swarm manager-а:
Если advertise address не будет передан параметром, docker попытается определить адрес для использования самостоятельно. Если у вас более двух сетевых интерфейсов (не считая интерфейса-петли), укажите конкретный адрес, чтобы у вас с докером не возникло недопонимания.
После инициализации первого менеджера ниже увидим команду для подключения нод-воркеров в формате:
Для просмотра команды, которая позволит добавить еще одного менеджера, выполним команду
Соответственно, для просмотра команды, которая позволит добавить еще одного воркера, выполним
В демонстрационных целях все три ноды я сделаю менеджерами.
Команда ниже позволит посмотреть состояние кластера:
Я выполню эту команду на сервере swr2.rpulse.locnet, и мы разберем ее вывод:
Все ноды готовы к обслуживанию (STATUS=Ready), доступны для выполнения на них контейнеров (AVAILABILITY=Active). Но лидером является только нода swr1.rpulse.locnet, в то время как остальные ноды просто доступны (MANAGER STATUS=Reacheble). Символом * отмечена нода, с которой мы выполнили команду.Команда
заставит ноду swr1.dev.rpulse.locnet не принимать на себя задачи по запуску и исполнению контейнеров (команду можно использовать для проведения техработ на ноде). При этом нода сохранит статус менеджера и продолжит выполнять соответствующие ее роли задачи.
Вернуть ноду к приему задач можно командой
Docker Swarm Service
Что такое сервис в docker swarm? Попробую описать сущность сервиса в одном изображении.
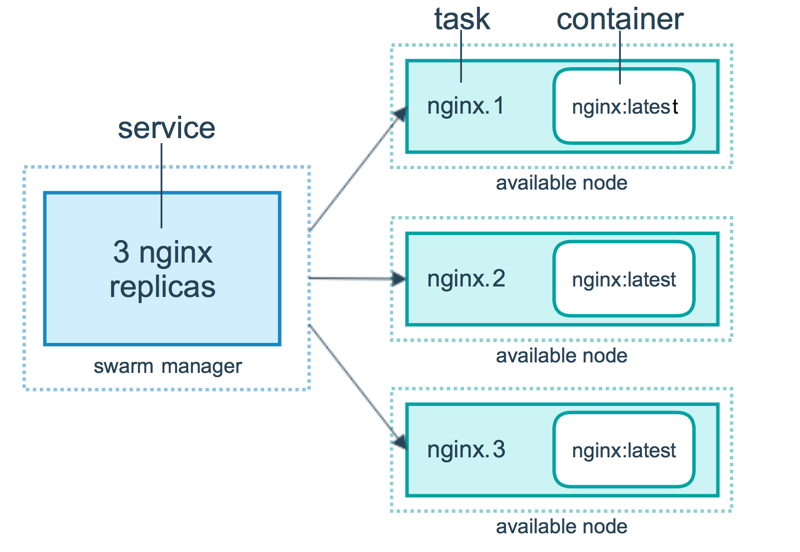
Docker Swarm container — это изолированный процесс. В модели docker swarm каждая задача вызывает один контейнер. Задача аналогична «слоту», куда планировщик помещает контейнер. Когда контейнер активен, планировщик распознает, что задача находится в рабочем состоянии. Если контейнер не проходит проверку работоспособности или завершается, завершается и задача.
Режимы Replicated и Global
Существует два типа развертывания сервисов: replicated и global.
Для реплицированного сервиса вы указываете, сколько идентичных задач хотите запустить. Например, вы решили развернуть сервис HTTP с тремя репликами, каждая из которых обслуживает один и тот же контент.
Глобальный сервис — это сервис, который запускает одну задачу на каждой ноде. Предварительно заданного количества задач нет. Каждый раз, когда вы добавляете ноду в swarm, оркестратор создает задачу, а планировщик назначает задачу новой ноде. По официальной документации, хорошими кандидатами на роль глобальных сервисов являются агенты мониторинга, антивирусные сканеры или другие типы контейнеров, которые вы хотите запустить на каждой ноде в swarm. Свой комментарий я дам позже.
Давайте вновь перейдем к практике и потренируемся в деплое сервисов.
создаст сервис HelloWorld из двух задач, контейнер базируется на образе alpine, где будет выполняться команда ping docker.com.
То же самое в расширенном режиме:
Обе команды выше поднимают сервис в режиме replicated – в нем несколько задач может быть и на одной ноде, и на разных.
Осуществим запуск сервисов в docker swarm по 1 задаче на каждую ноду в кластере (в режиме global):
покажет нам состояние всех запущенных сервисов в кластере.
покажет нам логи сервисa.
покажет последние 100 записей из логов сервиса.
Если мы выводим ноду, на которой были запущены задачи сервиса, в режим drain, мы можем посмотреть, по каким нодам разъедутся задачи командой
Это актуально для режима replicated.
обновит сервис и запустит в нем больше задач в режиме replicated. При этом несколько задач может быть и на одной ноде, и на разных. Можно заскейлить обратно.
удаляет наш сервис.
Файлы конфигурации и секреты
Конфигурации и секреты хранятся на manager-е, и оттуда происходит их дистрибуция.
создаст конфигурацию с именем passwdfile, которая будет осуществлять дистрибуцию файла /etc/passwd в контейнер.
покажет нам все созданные конфигурации.
создаст конфигурацию с именем shadowfile, хранящую sensitive данные.
покажет нам все конфигурации с sensitive данными.
Создадим сервис с пробросом файлов из наших конфигурации и секрета.
Посмотрим, на какой ноде запущен наш сервис:
Подключаемся к ноде и заходим в контейнер:
Наш конфиг подмонтировался в /passwd. Наш secret подмонтировался в /var/run/secrets/shadow.
Placements — места запуска
покажет все ноды в кластере.
покажет информацию о ноде.
Нодам можно задать labels — некие метки, по которым их можно сгруппировать. По умолчанию, они пустые. Если разным нодам мы дадим определенные лейблы, на основе их группировки мы получим площадки.
Посмотрим на примере — создадим две «площадки» с разными нодами, чтобы часть сервисов запускалась, скажем, на нодах, размещенных на площадке главного дата-центра (лейбл gdc), а другие — на резервной площадке (лейбл rp).
Предположим, что моя виртуальная машина swr1 размещена в главном дата-центре, а swr2 — на резервной площадке. Присвоим нодам лейблы.
Мы можем добавить еще лейблов для каждой ноды:
Запустим наш сервис на dev площадке в главном дата-центре:
Сервис запущен. Проверим, запустился ли он там, где мы ожидали:
***Как говорится, где пруфы, Билли! Буквы каждый написать может, давай скрины!! Даю.***
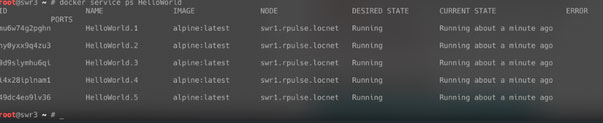
Сервис не попал на резервную площадку. А давайте пустим его туда?
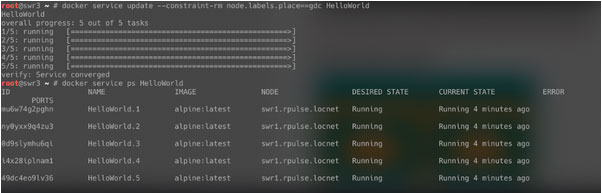
Задачам сервиса вполне уютно и на swr1 в gdc. Давайте заставим его оттуда уехать — переведем swr1 в «режим обслуживания»:
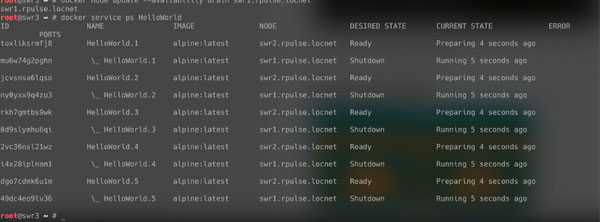
Задачи сервиса уехали на swr2, как и предполагалось. На скриншоте, сделанном сразу после вывода swr1 с приема задач, видно, что контейнеры еще подготавливаются. В скором времени сервис продолжит работу:
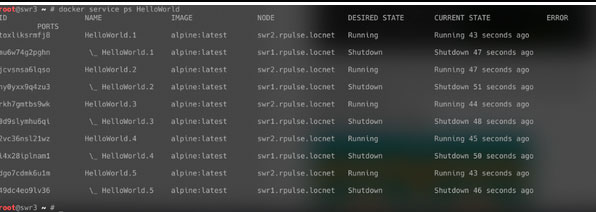
Ну и дабы набить руку, давайте все вернем взад!
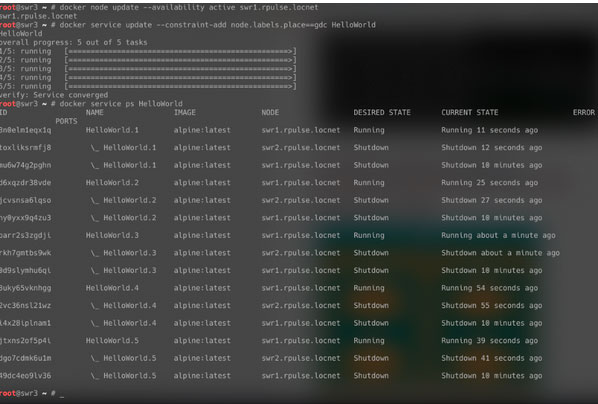
Вот и вернулся наш сервер на площадку дата-центра.Но мы еще сломали не все, что можно! Давайте посмотрим, что будет, если наш лидер-менеджер с запущенными на нем задачами внезапно сломается.
Снова удалим label gdc или пересоздадим сервис, чтобы сервису было куда уехать. Я пересоздам для примера.
После чего принудительно завершим работу гостевой системы (виртуальной машины) swr1.rpulse.locnet, это симулирует ситуацию аварийного завершения.
C помощью libvirt «убиваем» наповал swr1:
virsh destroy swr1
Смотрим на сервис и кластер:
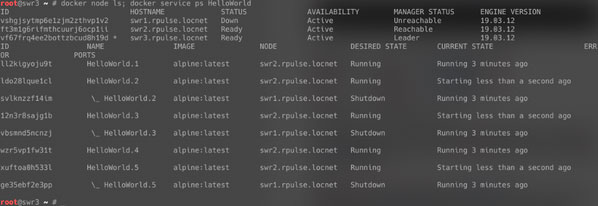
Во-первых, команда docker node ls показывает, что swr1 находится в статусе Unreachable (недоступен), а leader-ом стал swr3.
Вывод второй команды docker service ps HelloWorld показывает, что задачи 1 и 4 после пересоздания до симуляции падения лидера были запущены на swr2, так как он имел соответствующий label, а вот задачи 2, 3 и 5, запущенные изначально на swr1, переехали на swr2.
Поднимем обратно swr1 командой
Посмотрим, как там теперь обстоят дела.
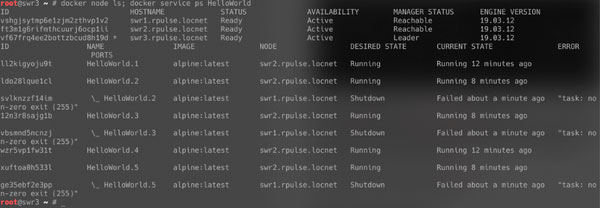
swr1 стал доступен, но лидером остался swr3. Часть задач вернулись обратно на swr1.
Docker Swarm. Stack
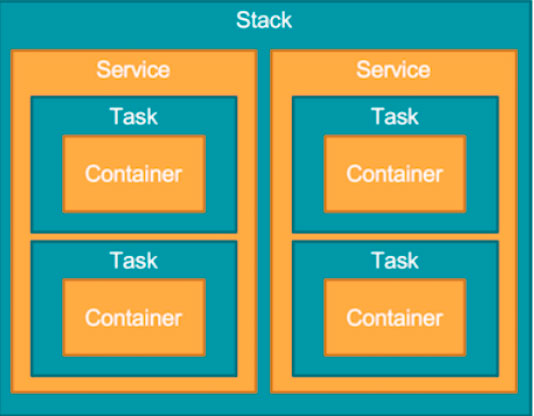
Файл формата docker-compose описывается для деплоя через docker stack, чтобы запустить несколько сервисов и управлять ими не как отдельными сервисами, а как единой системой в рамках одного стека. Проще говоря, в одном файле мы описываем все сервисы, необходимые для работы нашего приложения.
В данном стеке portainer присутствуют сервисы agent и portainer. Мы также описали здесь сеть и том.Для запуска стека portainer:
Docker Swarm. Краткий разбор сети
Network host
Используется для открытия порта в пространстве имен (namespace) хоста:
Запускает контейнер, вынося всю сеть контейнера в пространство имен хоста.
Routing Mesh
В данном режиме при запуске контейнера с опубликованным портом 9000, на какой ноде бы он не находился — к нему можно обратиться через любую ноду.
Routing Mesh Technologies — построены на:
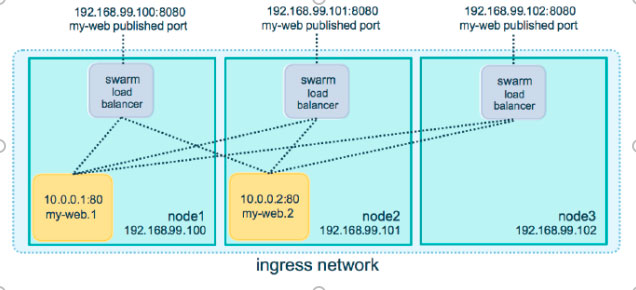
Cеть overlay в рамках swarm позволит создать внутреннюю сеть для контейнеров и опубликовать какой-либо порт на основе Routing mesh.
Хотите продолжить более подробный разбор полученных сегодня материалов с примерами? Обязательно отметьте свою заинтересованность и нажмите лайк слева от статьи. И до встречи в следующей части!
От редакции
Если вам интересно посещать бесплатные онлайн-мероприятия по DevOps, Kubernetes, Docker, GitlabCI и др. и задавать вопросы в режиме реального времени, подключайтесь к каналу DevOps by REBRAIN.
Краткое введение в Docker Swarm mode
Docker — прекрасен. С ним можно упаковать приложение по контейнерам, забросить их на случайный хост, и всё будет просто работать. Но на одном хосте особо не отмасштабируешься. Да и если хост прикажет долго жить, всё приложение отправится на тот свет вместе с ним. Конечно, для масштабирования можно завести сразу несколько хостов, объединить их при помощи overlay сети, так что и места больше будет, и возможность для контейнеров общаться останется.
Но опять же, как всем этим управлять? Хосты всё ещё могут отмирать. Как быстро определить, какой именно? Какие контейнеры на нём были? Куда теперь их переносить?
Начиная с версии 1.12.0 Docker может работать в режиме Swarm («Рой». В старых версиях был просто Docker Swarm, но тот работал по-другому), и потому способен решать все эти проблемы самостоятельно.
Что такое режим Swarm
Docker в Swarm режиме это просто Docker Engine, работающий в кластере. Кроме того, что он считает все кластерные хосты единым контейнерным пространством, он получает в нагрузку несколько новых команд (вроде docker node и docker service ) и концепцию сервисов.
Сервисы — это ещё один уровень абстракции над контейнерами. Как и у контейнера, у сервиса будет имя, базовый образ, опубликованные порты и тома (volumes). В отличие от контейнера, сервису можно задать требования к хосту (constraints), на которых его можно запускать. Да и вообще, сервис можно масштабировать прямо в момент создания, указав, сколько именно контейнеров для него нужно запустить.
Но важно понимать одну большую разницу. Сама по себе команда docker service create не создаёт никаких контейнеров. Она описывает желаемое состояние сервиса, а дальше уже Swarm менеджер будет искать способы это состояние достигнуть. Найдёт подходящие хосты, запустит контейнеры, будет следить, чтобы с ними (и хостами под ними) всё было хорошо, и перезапустит контейнер, если «хорошо» закончится. Иногда желаемое состояние сервиса так и не будет достигнуто. Например, если в кластере закончились доступные хосты. В таком случае сервис будет висеть в режиме ожидания до тех пор, пока что-нибудь не изменится.
План на сегодня
Будем играться. Пользы от абстрактной и непонятной теории — ноль, так что создадим-ка свой собственный уютный Docker кластер на три виртуальные машины. Запустим в нём один сервис для визуализации кластера, и ещё один, например web, чтобы масштабировался и заодно демонстрировал, как он успешно восстанавливается от внезапно упавшего хоста.
Что понадобится
Нам понадобится установленный Docker версии 1.12.0 и новее, docker-machine и VirtualBox. Первые два обычно устанавливаются вместе c Docker Toolbox на Маке и Windows. На Linux, ЕМНИП, docker-machine устанавливается отдельно, но всё ещё достаточно понятно. С установкой же VirtualBox проблем вообще не бывает. Обычно.
Я буду использовать Docker 17.03.1-ce для Mac и VirtualBox 5.1.20
Шаг 0. Создаём три виртуальные машины
Создавать машины при помощи именно docker-machine имеет смысл хотя бы потому, что они сразу будут идти с предустановленным Docker. Из трёх хостов на одном мы поселим менеджера Swarm, а на двух других — обычных рабочих. Собственно, создание виртуальных машин — удивительно безболезненное занятие:



