Как спарсить любой сайт?

Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
Найдите официальное API,
Найдите XHR запросы в консоли разработчика вашего браузера,
Найдите сырые JSON в html странице,
Отрендерите код страницы через автоматизацию браузера,
Совет профессионалов: не начинайте с BS4/Scrapy
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
Поищите XHR запросы в консоли разработчика
Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
Открывайте вебстраницу, которую хотите спарсить
Открывайте вкладку Network и кликайте на фильтр XHR запросов
Обновляйте страницу, чтобы в логах стали появляться запросы
Найдите запрос, который запрашивает данные, которые вам нужны
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Кнопка, которую я искал месяцы
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. 🤗 Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? 🙅♀️ Нет! 🙅♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят. И наш любимый (у парсеров) Linkedin!
Алгоритм действий такой:
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
Внизу ищите длинную длинную строчку с данными.
Вырезаете JSON из HTML любыми костылямии (я использую html.find(«=<") ).
Отрендерите JS через Headless Browsers
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из Cool website достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
И сделаем наш первый get-запрос.
Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
Получаем такой код.
И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
После запуска появится файл test.csv — с результатами поиска.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
30+ парсеров для сбора данных с любого сайта
Десктопные/облачные, платные/бесплатные, для SEO, для совместных покупок, для наполнения сайтов, для сбора цен… В обилии парсеров можно утонуть.
Мы разложили все по полочкам и собрали самые толковые инструменты парсинга — чтобы вы могли быстро и просто собрать открытую информацию с любого сайта.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Но если вы хотите собрать персональные данные пользователей и использовать их для email-рассылок или таргетированной рекламы, это уже будет незаконно (эти данные защищены законом о персональных данных).
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
Из русскоязычных облачных парсеров можно привести такие:
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
IMPORTXML
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
Функция принимает два значения:
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.
С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
IMPORTHTML
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
Она принимает три значения:
Об использовании 16 функций Google Таблиц для целей SEO читайте в нашей статье. Здесь все очень подробно расписано, с примерами по каждой функции.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
Популярные парсеры для СП:
Парсеры цен конкурентов
Инструменты для интернет-магазинов, которые хотят регулярно отслеживать цены конкурентов на аналогичные товары. С помощью таких парсеров вы можете указать ссылки на ресурсы конкурентов, сопоставлять их цены с вашими и корректировать при необходимости.
Вот три таких инструмента:
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
Парсеры для SEO-специалистов
Отдельная категория парсеров — узко- или многофункциональные программы, созданные специально под решение задач SEO-специалистов. Такие парсеры предназначены для упрощения комплексного анализа оптимизации сайта. С их помощью можно:
Пройдемся по нескольким популярным парсерам и рассмотрим их основные возможности и функционал.
Парсер метатегов и заголовков PromoPult
Стоимость: первые 500 запросов — бесплатно. Стоимость последующих запросов зависит от количества: до 1000 — 0,04 руб./запрос; от 10000 — 0,01 руб.
Возможности
С помощью парсера метатегов и заголовков можно собирать заголовки h1-h6, а также содержимое тегов title, description и keywords со своего или чужих сайтов.
Инструмент пригодится при оптимизации своего сайта. С его помощью можно обнаружить:
Также парсер полезен при анализе SEO конкурентов. Вы можете проанализировать, под какие ключевые слова конкуренты оптимизируют страницы своих сайтов, что прописывают в title и description, как формируют заголовки.
Сервис работает «в облаке». Для начала работы необходимо добавить список URL и указать, какие данные нужно спарсить. URL можно добавить вручную, загрузить XLSX-таблицу со списком адресов страниц, или вставить ссылку на карту сайта (sitemap.xml).
Парсер метатегов и заголовков — не единственный инструмент системы PromoPult для парсинга. В SEO-модуле системы можно бесплатно спарсить ключевые слова, по которым добавленный в систему сайт занимает ТОП-50 в Яндексе/Google.
Здесь же на вкладке “Слова ваших конкурентов” вы можете выгрузить ключевые слова конкурентов (до 10 URL за один раз).
Подробно о работе с парсингом ключей в SEO-модуле PromoPult читайте здесь.
Netpeak Spider
Стоимость: от 19$ в месяц, есть 14-дневный пробный период.
Парсер для комплексного анализа сайтов. С Netpeak Spider можно:
Screaming Frog SEO Spider
Стоимость: лицензия на год — 149 фунтов, есть бесплатная версия.
Многофункциональный инструмент для SEO-специалистов, подходит для решения практически любых SEO-задач:
В бесплатной версии доступен ограниченный функционал, а также есть лимиты на количество URL для парсинга (можно парсить всего 500 url). В платной версии таких лимитов нет, а также доступно больше возможностей. Например, можно парсить содержимое любых элементов страниц (цены, описания и т.д.).
ComparseR
Стоимость: 2000 рублей за 1 лицензию. Есть демо-версия с ограничениями.
Еще один десктопный парсер. С его помощью можно:
Анализ сайта от PR-CY
Стоимость: платный сервис, минимальный тариф — 990 рублей в месяц. Есть 7-дневная пробная версия с полным доступом к функционалу.
Онлайн-сервис для SEO-анализа сайтов. Сервис анализирует сайт по подробному списку параметров (70+ пунктов) и формирует отчет, в котором указаны:
Анализ сайта от SE Ranking
Стоимость: платный облачный сервис. Доступно две модели оплаты: ежемесячная подписка или оплата за проверку.
Стоимость минимального тарифа — 7$ в месяц (при оплате годовой подписки).
Возможности:
Xenu’s Link Sleuth
Стоимость: бесплатно.
Десктопный парсер для Windows. Используется для парсинга все url, которые есть на сайте:
Часто применяется для поиска неработающих ссылок на сайте.
A-Parser
Стоимость: платная программа с пожизненной лицензией. Минимальный тарифный план — 119$, максимальный — 279$. Есть демо-версия.
Многофункциональный SEO-комбайн, объединяющий 70+ разных парсеров, заточенных под различные задачи:
Кроме набора готовых инструментов, можно создать собственный парсер с помощью регулярных выражений, языка запросов XPath или Javascript. Есть доступ по API.
Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
10 инструментов, позволяющих парсить информацию с веб-сайтов, включая цены конкурентов + правовая оценка для России

Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂
10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
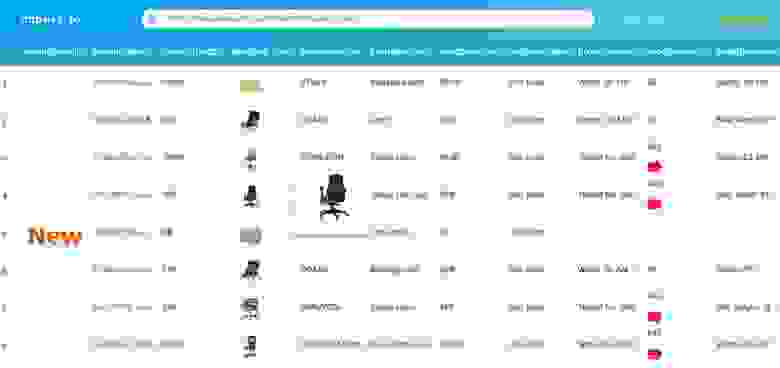
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.

Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.

CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.

Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
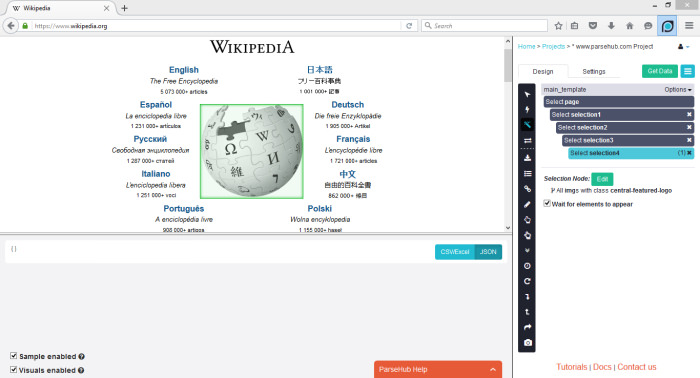
ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
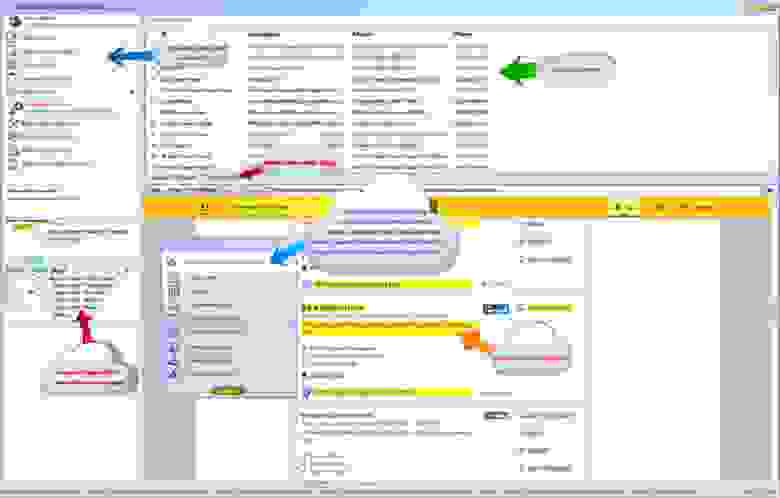
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
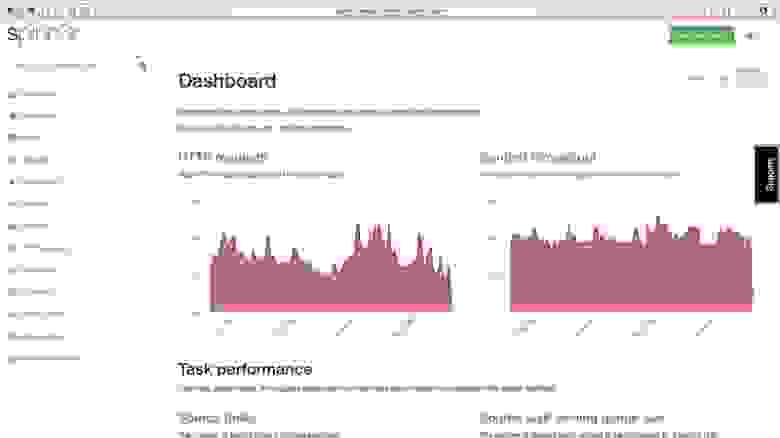
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.
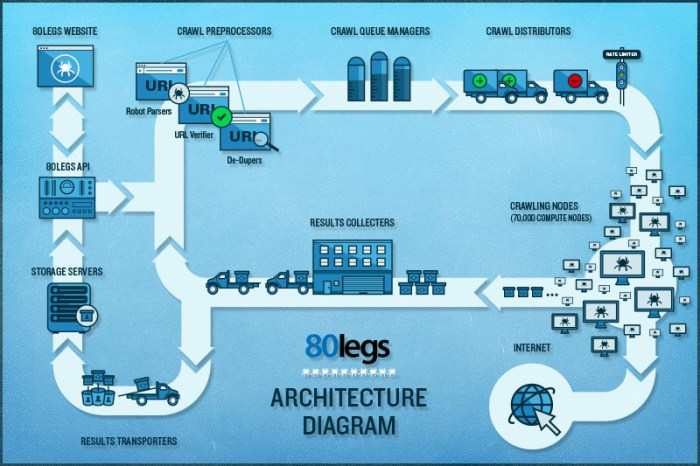
Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…



