С чего начать изучение Python: книги для начинающих

Друзья, забирайте в закладки подборку из 17 книг по Python.
Подборка поможет вам освоить язык программирования с нуля или с минимальными знаниями.
Готовы приступить к изучению Python?
Начинаем подготовку к изучению Python
Если вы не переходите на Python с другого языка программирования, а начинаете с нуля, сначала разберитесь в базовых понятиях разработки. Чтобы читать техническую литература на английском, подтяните уровень языка. В этом помогут книги:
Новички могут легко утонуть в профессиональных понятиях. Эта книга поможет разобраться в терминологии: что такое функции, функциональное и объектно-ориентированное программирование, как структурировать и развернуть программу, как хранить, управлять и обмениваться данными.
Даже если вы хорошо владеете английским, профессиональная терминология может загнать в тупик — потратите время на гугление. Этот учебник с аудиокнигой и интерактивными словарями поможет подтянуть уровень грамматики и пополнить словарный запас техническими терминами.
Учебный курс, который поможет улучшить навыки грамматики, пополнить словарный запас техническими терминами. Фишка книги — она содержит тексты и диаграммы для лучшего понимания материала, словарь современных вычислительных терминов, сокращений и символов.
Знакомимся с Python
Начните изучать язык программирования с теоретических основ — разберитесь в терминах, принципах работы языка. Для этого изучите книги:
Простая книга для введения в Python — автор объясняет основные термины, особенности языка доступным языком. Издание в основном теоретическое, из практики — руководства по созданию нескольких элементарных программ.
Опытный разработчик и преподаватель рассказывает об основных принципах разработки на примерах создания простых игр. После каждой главы автор предлагает проект игры, резюме пройденного материала и задачи для закрепления. После прочтения вы освоите базовые навыки разработки на Python и научитесь применять их на практике.
Переходим к практике
Когда разберетесь в теоретических основах, переходите на книги с практикой — реальными примерами кода, задачами, руководствами по разработке первых простых проектов:
Автор описывает основные типы объектов в Python, порядок их создания и дальнейшей работы с ними, рассказывает об основном процедурном элементе языка — функциях. После каждой главы приводит контрольные вопросы для закрепления материала, а после каждой части — практические упражнения.
Руководство по использованию Python в различных сферах — системном администрировании, создании веб-приложений и графических интерфейсов. Автор рассказывает, как работать с базами данных, программировать сетевые взаимодействия, создавать интерфейсы для сценариев и других задач.
Книга разработчика Лучано Рамальо для тех, кто уже научился писать на языке Python, но еще не использует все его возможности. Автор рассказывает о базовых средствах и библиотеках языка и приводит наглядные примеры, как сделать код короче, понятнее и быстрее.
Пошаговое руководство для новичков, которые хотят освоить язык программирования с нуля. Автор объясняет базовый синтаксис, учит работать с типами данными и переменными, классами и объектами, обрабатывать файлы и исключения.
Эта книга — полноценное руководство по Python, состоящее из четырех частей. Новичкам стоит изучить первую часть книги. Автор просто и понятно рассказывает о механизмах работы Python, как разобраться в основах языка и написать свою первую программу.
Пошаговое руководство, которое поможет освоить язык Python и применять его на практике. Автор рассказывает, как запустить первую программу, описывает переменные, типы данных, идентификаторы и делится другой полезной информацией.
Книга для новичков, которые уже освоили язык Python и хотят программировать лучше. Автор рассказывает, как использовать паттерны программирования, чтобы улучшить код, проводить распараллеливание и компиляцию программ, объясняет принципы высокоуровневого сетевого программирования и графики.
Продолжаем изучение: книги о Python по направлениям
Python можно использовать для решения многих задач — работы с сайтами, веб-приложениями, машинного обучения. Определитесь, в каком направлении хотите развиваться, и начните с профильной литературы:
Автор подробно рассказывает, как писать геоприложения. Вы научитесь получать доступ к геоданным и визуализировать их, читать и записывать данные в векторном и растровом формате, хранить и получать доступ, выполнять геопропространственные расчеты на языке Python.
Руководство, как примененять скрипты Python и веб-API, чтобы собирать и обрабатывать данные с тысяч сайтов. Будет интересна программистам и веб-администраторам, которые хотят изучить работу веб-скраперов, освоить анализ сырых данных и тестирование интерфейса.
Книга для новичков. Авторы доступно для понимания рассказывают, как строить системы машинного обучения, подробно объясняют этапы работы с применением Python и библиотек scikit-learn, NumPy и matplotlib.
Книга о Django — фреймворке для разработки веб-приложений на Python. Авторы рассказывают о компонентах фреймворка и методах работы с ним, приводят примеры применения в разных проектах.
Автор учит работать с популярным фреймворком Flask, приводит пошаговое руководство, как создать приложение социального блогинга. Узнаете возможности фреймворка, научитесь расширять приложения дополнительными технологиями.
Как выучить python || План обучения с нуля
Всем привет. Решил поделиться планом обучения python с нуля и до приемлимого уровня.
Итак рекомендую начать обучение с прочтения книги «Byte of Python « или по русски укус питона. Это очень маленькая книжка, прочтение которой не отнимет у вас много времени, но зато вы уже сможете получить знания об основах языка. Все кратно и по делу.
Ссылка: https://wombat.org.ua/AByteOfPython/#id10
Далее стоит закрепить полученные знания в курсе на сайте stepik : «Поколение Python»: курс для начинающих
После этого курса стоит немного уделить времени алгоритмам, в этом нам поможет книга “Грокаем аглоритмы”, все примеры в этой книге так же разбираются на языке пайтон, что очень удобно для нас.
После книги про алгоритмы возвращаемся на stepik и проходим курс «Python: основы и применение.» Здесь вы еще больше погрузитесь в язык. изучите классы, попробуете поработать с различными АПИ. В общем будет чем заняться.
Ссылка: https://stepik.org/course/512/syllabus
После этого курса я рекомендую пару недель уделить только решению различных задач по программированию. Для этого существует множество сайтов, я оставлю ссылки на все в описании. Выбирайте какой больше понравится. Лично мне больше всех понравился chekio. Знаю, что многие любят codewars.
Сайты где можно порешать задачки Python:
Вне зависимости от того какой сайт вы выберете, рекомендую начинать с более простых задач, и решать по 3-5 штук в день. Так же после решения, вам будет позволено посмотреть как эту задачу решили другие участники. Почти всегда это будет сделано более элегантным или продвинутым способом. В общем на решениях других людей тоже можно многое почерпнуть.
Далее стоит ознакомиться с ютуб каналом Computer science center
Здесь уже рассматривают продвинутые техники языка. Очень рекомендую к ознакомлению.
Если вам больше нравится читать книги, то вместо этого курса могу порекомендовать книгу «Python. К вершинам мастерства.»
Еще есть вот такой курс от Яндекса.
Так же не забываем постоянно решать задачки с сайтов, чтобы постоянно была практика.
При среднем темпе обучения, на все эти шаги у вас уйдет 3-4 месяца.
На этом этапе уже можно спокойно начать погружаться в выбранную Вами сферу, будь это веб программирование с помощью фреймворков джанго, фласк или может быть датасаенс. Это уже выходит за рамки данного поста. То как стать датасаентистом, мы разбирали в этом посте:
Так же эти ресурсы могут быть вам полезны:
Книга: Изучаем Python. Том 1 | Лутц Марк
Книга: Изучаем Python. Том 2 | Лутц Марк
Книга: Доусон М. Программируем на Python.
У нас есть чатик в телеграмме где мы обсуждаем с подписчиками различные вопросы, залетай к нам! https://t.me/DataScienceGuy
Салют! Ты с 0 осваивал pyhton? Сколько времени заняло обучение чтобы выйти на начальный уровень?
Сейчас смотрю лекции Хирьянова.
О, от яндекса курс не видела ещё, спасибо.
Спасибо, а почему бы и нет!
Здравствуйте. Есть предложение по сотрудничеству. Если интересно- напишите ermolenko_olja@mail.ru
А мне кажется, что бесплатно сложно научиться, мотивация не такая сильная, в отличие от того
если ты заплатил за курс. Есть относительно не дорогие, но очень качественные курсы https://codeby.net/threads/kurs-python-dlja-pentestera.70415. Пять месяцев обучения от нуля до продвинутого. Домашнее задание проверяется в ручную, преподаватели всегда на связи.
Крутяк! Хотеть подобный пост про Java
Давно хотел изучить Питон, но никак не мог найти правильный ракурс подхода к данному вопросу. Опираясь на Ваш пост уже прошел курс «Поколение Python: курс для начинающих» и прочел книги «Byte of Python» и «Грокаем алгоритмы». Так вот, к чему это я. Дойдя до курса «Python: основы и применение.» я познал боль и отчаяние. Был вынужден искать новые пути познания и пока остановился на курсе «Инди-курс программирования на Python от egoroff_channel» от Артема Егорова (ссылку оставлять не стану на случай, если автор против подобных вбросов). Данный курс часто появлялся в комментах на «Основах и применении» как единственная панацея, что я и решил проверить. Не знаю, проблема ли в качестве изложения авторов курса из Вашего списка, либо в резком перепаде сложности курсов, но что-то не пошло. Возможно стоит рассмотреть какую-то прослойку из переходного курса или вспомогательных материалов. Дело Ваше, но я говорю от лица человека, который по данному посту с нуля решил обучиться и встретил определенные сложности.
Во всяком случае, путь мой только начат, и начат он не без Вашей помощи. Спасибо 🙂
Пы.Сы: хотел просто вбросить про возможно неплохое дополнение к программе обучения, но что-то занесло хехехе.
А у меня создалось ощущение, что питон просто очередная мода. Может быть востребован ещё долго, а может и отвалится. Помнится на перл поначалу также многие молились.
Сам пользуюсь уже лет 10 для автоматизации и мне в принципе питон очень нравится. Но крупный серьёзный проект скорее всего на нем не стал бы делать.
За сссылки спасибо, сохранил.
Оставлю комент. Завтра почитаю.
ТС скажи как у питона обстоят дела с ООП
На всякий случай изучу. А то в селе скучно стало, клуб и тот закрыли.
найти заказчика, который скажет: Тебе надо закрыть этот проект на питоне «на вчера»
Ну не летом же начинать такое серьезное дело, а вот с числа точно начну!:))


Вот уже на протяжении нескольких лет Тимофей, преподаватель кафедры информатики МФТИ, выкладывает свои лекции по программированию на своём Youtube канале с открытым доступом.




Разработка системы заметок с нуля. Часть 2: REST API для RESTful API Service + JWT + Swagger
Продолжаем серию материалов про создание системы заметок. В этой части мы спроектируем и разработаем RESTful API Service на Go cо Swagger и авторизацией. Будет много кода, ещё больше рефакторинга и даже немного интеграционных тестов.
В первой части мы спроектировали систему и посмотрели, какие сервисы требуются для построения микросервисной архитектуры.
Подробности в видео и текстовой расшифровке под ним.
Начнём с макетов интерфейса. Нам нужно понять, какие ручки будут у нашего API и какой состав данных он должен отдавать. Макеты мы будем делать, чтобы понять, какие сущности, поля и эндпоинты нам нужны. Используем для этого онлайн-сервис NinjaMock. Он подходит, если макет надо сделать быстро и без лишних действий.
Страницу регистрации сделаем простую, с четырьмя полями: Name, Email, Password и Repeat Password. Лейблы делать не будем, обойдемся плейсходерами. Авторизацию сделаем по юзернейму и паролю.
После входа в приложение пользователь увидит список заметок, который будет выглядеть примерно так:
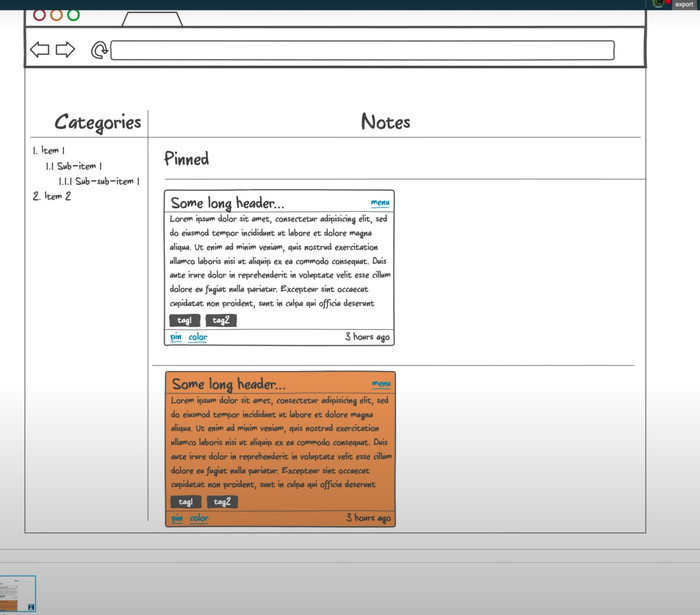
Интерфейс, который будет у нашего веб-приложения:
— Слева — список категорий любой вложенности.
— Справа — список заметок в виде карточек, который делится на два списка: прикреплённые и обычные карточки.
— Каждая карточка состоит из заголовка, который урезается, если он очень длинный.
— Справа указано, сколько секунд/минут/часов/дней назад была создана заметка.
— Тело заголовка — отрендеренный Markdown.
— Панель инструментов. Через неё можно изменить цвет, прикрепить или удалить заметку.
Тут важно отметить, что файлы заметки мы не отображаем и не будем запрашивать у API для списка заметок.
Полная карточка открывается по клику на заметку. Тут можно сразу отобразить полностью длинный заголовок. Высота заметки зависит от количества текста. Для файлов появляется отдельная секция. Мы их будем получать отдельным асинхронным запросом, который не помешает пользователю редактировать заметку. Файлы можно скачать по ссылке, также есть отдельная кнопка на добавление файлов.
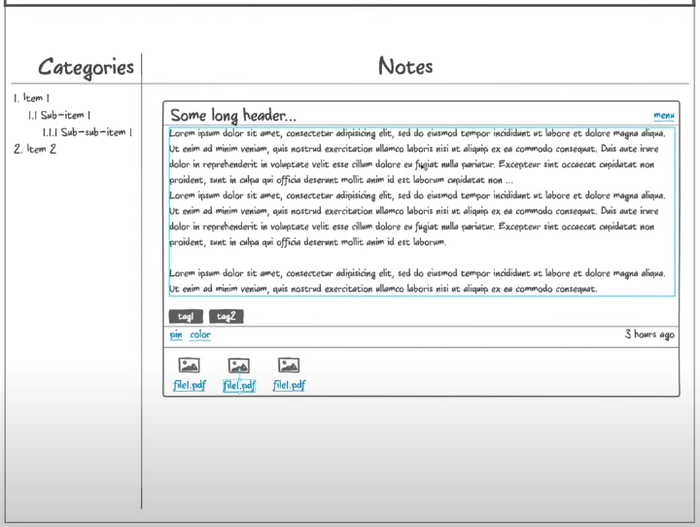
Так будет выглядеть открытая заметка
В ходе прототипирования стало понятно, что в первой части мы забыли добавить еще один микросервис — TagsService. Он будет управлять тегами.
Для страниц авторизации и регистрации нам нужны эндпоинты аутентификации и регистрации соответственно. В качестве аутентификации и сессий пользователя мы будем использовать JWT. Что это такое и как работает, разберём чуть позднее. Пока просто запомните эти 3 буквы.
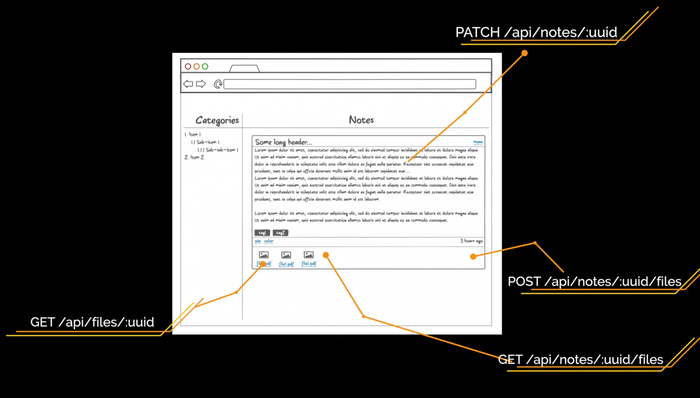
Для страницы списка заметок нам нужны эндпоинты /api/categories для получения древовидного списка категорий и /api/notes?category_id=? для получения списка заметок текущей категории. Перемещаясь по другим категориям, мы будем отдельно запрашивать заметки для выбранной категории, а на фронтенде сделаем кэш на клиенте. В ходе работы с заметками нам нужно уметь создавать новую категорию. Это будет метод POST на URL /api/categories. Также мы будем создавать новый тег при помощи метода POST на URL /api/tags.

Чтобы обновить заметку, используем метод PATCH на URL /api/notes/:uuid с измененными полями. Делаем PATCH, а не PUT, потому что PUT требует отправки всех полей сущности по спецификации HTTP, а PATCH как раз нужен для частичного обновления. Для отображения заметки нам ещё нужен эндпоинт /api/notes/:uuid/files с методами POST и GET. Также нам нужно скачивать файл, поэтому сделаем метод GET на URL /api/files/:uuid.
Структура репозитория системы
Ещё немного общей информации. Структура репозитория всей системы будет выглядеть следующим образом:
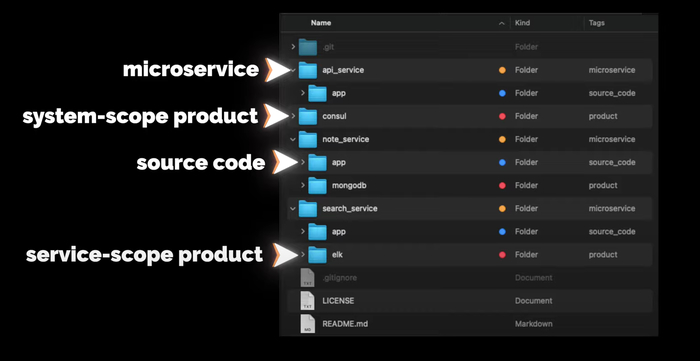
В директории app будет исходный код сервиса (если он будет). На уровне с app будут другие директории других продуктов, которые используются с этим сервисом, например, MongoDB или ELK. Продукты, которые будут использоваться на уровне всей системы, например, Consul, будут в отдельных директориях на уровне с сервисами.
Писать будем на Go
— Идём на официальный сайт.
— Копируем ссылку до архива, скачиваем, проверяем хеш-сумму.
— Распаковываем и добавляем в переменную PATH путь до бинарников Go
— Пишем небольшой тест проверки работоспособности, собираем бинарник и запускаем.
Установка завершена, всё работает
Теперь создаём проект. Структура стандартная:
— cmd — точка входа в приложение,
— internal — внутренняя бизнес-логика приложения,
— pkg — для кода, который можно переиспользовать из проекта в проект.
Я очень люблю логировать ход работы приложения, поэтому перенесу свою обёртку над логером logrus из другого проекта. Основная функция здесь Init, которая создает логер, папку logs и в ней файл all.log со всеми логами. Кроме файла логи будут выводиться в STDOUT. Также в пакете реализована поддержка логирования в разные файлы с разным уровнем логирования, но в текущем проекте мы это использовать не будем.
APIService будет работать на сокете. Создаём роутер, затем файл с сокетом и начинаем его слушать. Также мы хотим перехватывать от системы сигналы завершения работы. Например, если кто-то пошлёт приложению сигнал SIGHUP, приложение должно корректно завершиться, закрыв все текущие соединения и сессии. Хотел перехватывать все сигналы, но линтер предупреждает, что os.Kill и SIGSTOP перехватить не получится, поэтому их удаляем из этого списка.
Теперь давайте добавим сразу стандартный handler для метрик. Я его копирую в директорию pkg, далее добавляю в роутер. Все последующие роутеры будем добавлять так же.
Далее создаём точку входа в приложение. В директории cmd создаём директорию main, а в ней — файл app.go. В нём мы создаём функцию main, в которой инициализируем и создаём логер. Роутер создаём через ключевое слово defer, чтобы метод Init у роутера вызвался только тогда, когда завершится функция main. Таким образом можно выполнять очистку ресурсов, закрытие контекстов и отложенный запуск методов. Запускаем, проверяем логи и сокет, всё работает.
Но для разработки нам нужно запускать приложение на порту, а не на сокете. Поэтому давайте добавим запуск приложения на порту в наш роутер. Определять, как запускать приложение, мы будем с помощью конфига.
Создадим для приложения контекст. Сделаем его синглтоном при помощи механизма sync.Once. Пока что в нём будет только конфиг. Контекст в виде синглтона создаю исключительно в учебных целях, впоследствии он будет выпилен. В большинстве случаев синглтоны — необходимое зло, в нашем проекте они не нужны. Далее создаём конфиг. Это будет YAML-файл, который мы будем парсить в структуру.
В роутере мы вытаскиваем из контекста конфиг и на основании listen.type либо создаем сокет, либо вешаем приложение на порт. Код graceful shutdown выделяем в отдельный пакет и передаём на вход список сигналов и список интерфейсов io.Close, которые надо закрывать. Запускаем приложение и проверяем наш эндпоинт heartbeat. Всё работает. Давайте и конфиг сделаем синглтоном через механизм sync.Once, чтобы потом безболезненно удалить контекст, который создавался в учебных целях.
Теперь переходим к API. Создаём эндпоинты, полученные при анализе прототипов интерфейса. Тут важно отметить, что у нас все данные привязаны к пользователю. На первый взгляд, все ручки должны начинаться с пользователя и его идентификатора /api/users/:uuid. Но у нас будет авторизация, иначе любой пользователь сможет программно запросить заметки любого другого пользователя. Авторизацию можно сделать следующим образом: Basic Auth, Digest Auth, JSON Web Token, сессии и OAuth2. У всех способов есть свои плюсы и минусы. Для этого проекта мы возьмём JSON Web Token.
Работа с JSON Web Token
JSON Web Token (JWT) — это JSON-объект, который определён в открытом стандарте RFC 7519. Он считается одним из безопасных способов передачи информации между двумя участниками. Для его создания необходимо определить заголовок (header) с общей информацией по токену, полезные данные (payload), такие как id пользователя, его роль и т.д., а также подписи (signature).
JWT использует преимущества подхода цифровой подписи JWS (Signature) и кодирования JWE (Encrypting). Подпись не даёт кому-то подделать токен без информации о секретном ключе, а кодирование защищает от прочтения данных третьими лицами. Давайте разберёмся, как они могут нам помочь для аутентификации и авторизации пользователя.
Аутентификация — процедура проверки подлинности. Мы проверяем, есть ли пользователь с полученной связкой логин-пароль в нашей системе.
Авторизация — предоставление пользователю прав на выполнение определённых действий, а также процесс проверки (подтверждения) данных прав при попытке выполнения этих действий.
Другими словами, аутентификация проверяет легальность пользователя. Пользователь становится авторизированным, если может выполнять разрешённые действия.
Важно понимать, что использование JWT не скрывает и не маскирует данные автоматически. Причина использования JWT — проверка, что отправленные данные были действительно отправлены авторизованным источником. Данные внутри JWT закодированы и подписаны, но не зашифрованы. Цель кодирования данных — преобразование структуры. Подписанные данные позволяют получателю данных проверить аутентификацию источника данных.
Реализация JWT в нашем APIService:
— Создаём директории middleware и jwt, а также файл jwt.go.
— Описываем кастомные UserClaims и сам middlware.
— Получаем заголовок Authorization, оттуда берём токен.
— Берём секрет из конфига.
— Создаём верификатор HMAC.
— Парсим и проверяем токен.
— Анмаршалим полученные данные в модель UserClaims.
— Проверяем, что токен валидный на текущий момент.
При любой ошибке отдаём ответ с кодом 401 Unauthorized. Если ошибок не было, в контекст сохраняем ID пользователя в параметр user_id, чтобы во всех хендлерах его можно было получить. Теперь надо этот токен сгенерировать. Это будет делать хендлер авторизации с методом POST и эндпоинтом /api/auth. Он получает входные данные в виде полей username и password, которые мы описываем отдельной структурой user. Здесь также будет взаимодействие с UserService, нам надо там искать пользователя по полученным данным. Если такой пользователь есть, то создаём для него UserClaims, в которых указываем все нужные для нас данные. Определяем время жизни токена при помощи переменной ExpiresAt — берём текущее время и добавляем 15 секунд. Билдим токен и отдаём в виде JSON в параметре token. Клиента к UserService у нас пока нет, поэтому делаем заглушку.
Добавим в хендлер с heartbeat еще один тестовый хендлер, чтобы проверить работу аутентификации. Пишем небольшой тест. Для этого используем инструмент sketch, встроенный в IDE. Делаем POST-запрос на /api/auth, получаем токен и подставляем его в следующий запрос. Получаем ответ от эндпоинта /api/heartbeat, по истечении 5 секунд мы начнём получать ошибку с кодом 401 Unauthorized.
Наш токен действителен очень ограниченное время. Сейчас это 15 секунд, а будет минут 30. Но этого всё равно мало. Когда токен протухнет, пользователю необходимо будет заново авторизовываться в системе. Это сделано для того, чтобы защитить пользовательские данные. Если злоумышленник украдет токен авторизации, который будет действовать очень большой промежуток времени или вообще бессрочно, то это будет провал.
Чтобы этого избежать, прикрутим refresh-токен. Он позволит пересоздать основной токен доступа без запроса данных авторизации пользователя. Такие токены живут очень долго или вообще бессрочно. После того как только старый JWT истекает мы больше не можем обратиться к API. Тогда отправляем refresh-токен. Нам приходит новая пара токена доступа и refresh-токена.
Хранить refresh-токены на сервере мы будем в кэше. В качестве реализации возьмём FreeCache. Я использую свою обёртку над кэшем из другого проекта, которая позволяет заменить реализацию FreeCache на любую другую, так как отдает интерфейс Repository с методами, которые никак не связаны с библиотекой.
Пока рассуждал про кэш, решил зарефакторить существующий код, чтобы было удобней прокидывать объекты без dependency injection и синглтонов. Обернул хендлеры и роутер в структуры. В хендлерах сделал интерфейс с методом Register, которые регистрируют его в роутере. Все объекты теперь инициализируются в main, весь роутер переехал в мейн. Старт приложения выделили в отдельную функцию также в main-файле. Теперь, если хендлеру нужен какой-то объект, я его просто буду добавлять в конструктор структуры хендлера, а инициализировать в main. Плюс появилась возможность прокидывать всем хендлерам свой логер. Это будет удобно когда надо будет добавлять поле trace_id от Zipkin в строчку лога.
Вернемся к refresh_token. Теперь при создании токена доступа создадим refresh_token и отдадим его вместе с основным. Сделаем обработку метода PUT для эндпоинта /api/auth, а в теле запроса будем ожидать параметр refresh_token, чтобы сгенерировать новую пару токена доступа и refresh-токена. Refresh-токен мы кладём в кэш в качестве ключа. Значением будет user_id, чтобы по нему можно было запросить данные пользователя у UserService и сгенерировать новый токен доступа. Refresh-токен одноразовый, поэтому сразу после получения токена из кэша удаляем его.
Для описания нашего API будем использовать спецификацию OpenAPI 3.0 и Swagger — YAML-файл, который описывает все схемы данных и все эндпоинты. По нему очень легко ориентироваться, у него приятный интерфейс. Но описывать вручную всё очень муторно, поэтому лучше генерировать его кодом.
— Создаём эндпоинты /api/auth с методами POST и PUT для получения токена по юзернейму и паролю и по Refresh-токену соответственно.
— Добавляем схемы объектов Token и User.
— Создаём эндпоинты /api/users с методом POST для регистрации нового пользователя. Для него создаём схему CreateUser.
Понимаем, что забыли сделать хендлер для регистрации пользователя. Создаём метод Signup у хенлера Auth и структуру newUser со всеми полями для регистрации. Генерацию JWT выделяем в отдельный метод, чтобы можно было его вызывать как в Auth, так и в Signup-хендлерах. У нас всё еще нет UserService, поэтому проставляем TODO. Нам надо будет провалидировать полученные данные от пользователя и потом отправить их в UserService, чтобы он уже создал пользователя и ответил нам об успехе. Далее вызываем функцию создания пары токена доступа и refresh-токена и отдаём с кодом 201.
У нас есть подсказка в виде Swagger-файла. На его основе создаём все нужные хендлеры. Там, где вызов микросервисов, будем проставлять комментарий с TODO.
Создаём хендлер для категорий, определяем URL в константах. Далее создаём структуры. Опираемся на Swagger-файл, который создали ранее. Далее создаём сам хендлер и реализуем метод Register, который регистрирует его в роутере. Затем создаём методы с логикой работы и сразу пишем тест API на этот метод. Проверяем, находим ошибки в сваггере. Таким образом мы создаём все методы по работе с категориями: получение и создание.
Далее создаём таким же образом хендлер для заметок. Понимаем, что забыли методы частичного обновления и удаления как для заметок, так и для категорий. Дописываем их в Swagger и реализуем методы в коде. Также обязательно тестируем Swagger в онлайн-редакторе.
Здесь надо обратить внимание на то, что методы создания сущности возвращают код ответа 201 и заголовок Location, в котором находится URL для получения сущности. Оттуда можно вытащить идентификатор созданной сущности.
В третьей части мы познакомимся с графовой базой данных Neo4j, а также будем работать над микросервисами CategoryService и APIService.



