Распознавание речи с помощью инструментов машинного обучения
В своей работе я столкнулся с необходимостью проверить записи звонков на соблюдение сотрудниками скрипта разговора с клиентами. Обычно для этого выделяется сотрудник, который тратит большое количество времени на прослушивание записей разговоров. Мы поставили себе задачу — уменьшить временные затраты на проверку с помощью инструментов автоматического распознавания речи (ASR). Один из таких инструментов мы рассмотрим подробнее.
Nvidia NeMo — набор инструментов машинного обучения для создания и обучения моделей на базе графического процессора.
Модели в составе NeMo используют современный подход к распознаванию речи — коннекционистская временная классификация (CTC).
До СТС использовался подход, при котором входной аудиофайл разбивался на отдельные речевые сегменты и по ним предсказывались токены. Далее токены объединялись, повторяющиеся сворачивались в один, и результат подавался на вывод модели.
При этом страдала точность распознавания, так как слово с повторяющимися буквами не считалось корректно распознанным на 100%. Например, «кООперация» приводилось к «кОперация».
С CTC — все еще предсказываю один токен на временной сегмент речи и дополнительно используем пустой токен, чтобы выяснить где свернуть повторяющиеся токены. Появление пустого токена помогает отделить повторяющиеся буквы, которые не должны быть свернуты.
Для своей задачи я взял одну из моделей (Jasper 10×5) и обучил ее с нуля. Для обучения был выбран публичный датасет телефонных разговоров, содержащий нарезанные аудиозаписи и их транскрибацию.
Чтобы обучить модель, необходимо подготовить файл-манифест, содержащий информацию об аудиофайле и транскрибацию этого файла. Файл манифест имеет свой формат:
Модель принимает аудиофайлы только в формате *.wav. Необходимо пробежаться циклом по всему списку аудиофайлов и при помощи консольной утилиты перекодировать аудиофайлы с отличным от необходимого разрешением:
Для построения тестового и тренировочного манифеста я использовал следующую функцию, в которой получили длительность аудиофайла с помощью функции getduration(filename=audiopath) библиотеки Librosa, путь к файлам транскрибации и аудиофайлам нам известен:
Для инициализации модели я сформировал специальный файл конфигурации, в котором прописываются все параметры модели:
Достаточно загрузить этот файл в конструктор модели и приступать к ее обучению. Для этого необходимо добавить к параметрам модели пути к тестовому и проверочному манифесту и с помощью инструмента pytorch_lighting запустить процесс обучения:
После обучения готовую модель можно использовать для распознавания речи:
В результате мне удалось добиться достаточной точности, чтобы уверенно распознавать аудиофайлы.
При использовании инструмента NeMo я выделил для себя следующие достоинства:
быстрое обучение на GPU;
возможность менять настройки модели из одного места, не меняя код;
Из недостатков можно отметить необходимость включения большого количества тяжеловесных библиотек, а также то, что инструмент относительно свежий и некоторые функции модели находятся в бета-тесте.
При решении задачи по распознаванию речи я получил интересный опыт работы с ASR моделями. Смог обучить модель на случайном датасете и получили достаточную точность для уверенного распознавания телефонных разговоров.
Предлагаем использовать данный инструмент не только для распознавания речи, но и для генерации аудиофайлов на основе текста (TTS) и распознавания диктора (speaker recognition).
Классификация звуков с помощью TensorFlow
Игорь Пантелеев, Software Developer, DataArt
Для распознавания человеческой речи придумано множество сервисов — достаточно вспомнить Pocketsphinx или Google Speech API. Они способны довольно качественно преобразовать в печатный текст фразы, записанные в виде звукового файла. Но ни одно из этих приложений не может сортировать разные звуки, захваченные микрофоном. Что именно было записано: человеческая речь, крики животных или музыка? Мы столкнулись с необходимостью ответить на этот вопрос. И решили создать пробные проекты для классификации звуков с помощью алгоритмов машинного обучения. В статье описано, какие инструменты мы выбрали, с какими проблемами столкнулись, как обучали модель для TensorFlow, и как запустить наше решение с открытым исходным кодом. Также мы можем загружать результаты распознавания на IoT-платформу DeviceHive, чтобы использовать их в облачных сервисах для сторонних приложений.
Выбор инструментов и модели для классификации
Сначала нам нужно было выбрать ПО для работы с нейронными сетями. Первым решением, которое показалось нам подходящим, была библиотека Python Audio Analysis.
Основная проблема машинного обучения — хороший набор данных. Для распознавания речи и классификации музыки таких наборов очень много. С классификацией случайных звуков дела обстоят не так хорошо, но мы, пусть и не сразу, нашли набор данных с «городскими» звуками.
В ходе тестирования мы столкнулись со следующими проблемами:
Модель обучения
Следующей задачей было выяснить, как работает интерфейс YouTube-8M. Он предназначен для работы с видео, но, к счастью, может работать и с аудио. Эта библиотека довольно гибкая, но имеет фиксированное число классов. Поэтому мы внесли некоторые изменения, чтобы количество классов можно было передавать в качестве параметра. YouTube-8M может работать с данными двух типов: агрегированными фичами и фичами для каждого фрагмента. Google AudioSet предоставляет данные в виде фич для каждого фрагмента. Далее нам нужно было выбрать модель для обучения.
Ресурсы, время и точность
Графические процессоры (GPU) лучше подходят для машинного обучения, чем центральные процессоры (CPU). Вы можете найти больше информации здесь, поэтому мы не будем на этом подробно останавливаться и сразу перейдем к нашей конфигурации. Для экспериментов мы использовали PC с одной видеокартой NVIDIA GTX 970 4GB.
В нашем случае время обучения не имело особого значения. Отметим, что одного–двух часов обучения было достаточно, чтобы принять первоначальное решение о выбранной модели и ее точности.
Конечно, мы хотим получить как можно более высокую точность. Но для обучения более сложной модели (которая должна обеспечить большую точность) потребуется больше оперативной памяти (памяти видеоплаты в случае использования графического процессора).
Выбор модели
Полный список моделей YouTube-8M с описаниями доступен здесь. Поскольку наши данные для обучения представлены в виде фрагментированных фич, необходимо использовать соответствующую модель. Google AudioSet содержит разделенный на три части набор данных: сбалансированное обучение (balanced train), несбалансированное обучение (unbalanced train) и оценка. Подробнее об этом можно прочитать здесь.
Для обучения и оценки использовалась модифицированная версия YouTube-8M. Ее можно найти здесь.
Сбалансированное обучение
В данном случае команда выглядит следующим образом:
Для LstmModel мы изменили базовую скорость обучения на 0,001 в соответствии с документацией. Также мы изменили значение lstm_cells на 256, так как у нас не хватило оперативной памяти.
Давайте посмотрим на результаты обучения.


| Название модели | Время обучения | Оценка на последнем шаге | Средняя оценка |
|---|---|---|---|
| Logistic | 14m 3s | 0.5859 | 0.5560 |
| Dbof | 31m 46s | 1.000 | 0.5220 |
| Lstm | 1h 45m 53s | 0.9883 | 0.4581 |
Нам удалось получить хорошие результаты на этапе обучения, однако это не значит, что мы достигнем аналогичных показателей при полной оценке.
Несбалансированное обучение
В несбалансированном наборе данных намного больше сэмплов, поэтому мы установили значение количества циклов обучения на 10 (следовало выставить пять, потому что на обучение ушло достаточно много времени).


| Название модели | Время обучения | Оценка на последнем шаге | Средняя оценка |
|---|---|---|---|
| Logistic | 2h 4m 14s | 0.8750 | 0.5125 |
| Dbof | 4h 39m 29s | 0.8848 | 0.5605 |
| Lstm | 9h 42m 52s | 0.8691 | 0.5396 |
Журнал обучения
Подробнее об обучении
YouTube-8M принимает множество параметров, и многие из них влияют на процесс обучения.
Например, можно настроить скорость обучения и количество эпох, что сильно изменит процесс обучения. Также существуют три функции для расчета потерь и другие полезные переменные, которые можно настроить и изменить для улучшения результатов.
Использование обученной модели с устройствами для захвата аудио
Когда у нас есть обученные модели, пора добавить код для взаимодействия с ними.
Захват аудио с помощью микрофона
Нам нужно каким-то образом получить аудиоданные с микрофона. Мы будем использовать библиотеку PyAudio, которая имеет простой интерфейс и может работать на большинстве платформ.
Подготовка звука
Как упоминалось ранее, мы используем модель TensorFlow VGGish в качестве инструмента для извлечения фич. Вот краткое объяснение процесса трансформации:
Для визуализации использовался сэмпл Dog bark («Лай собаки») из набора данных UrbanSound.
Преобразуем аудио к формату 16 kHz моно.
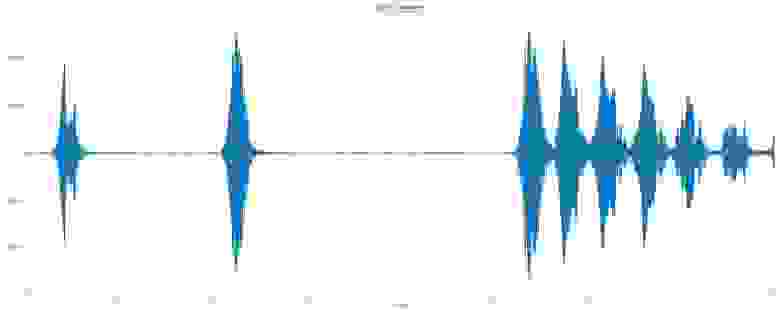
Рассчитываем спектрограмму с помощью величин STFT (преобразование Фурье на малом временном интервале) с размером окна 25 мс, шагом в 10 мс и периодическим окном Ханна.

Рассчитываем мел-спектрограмму, приводя текущую спектрограмму к 64-разрядному мел-диапазону.
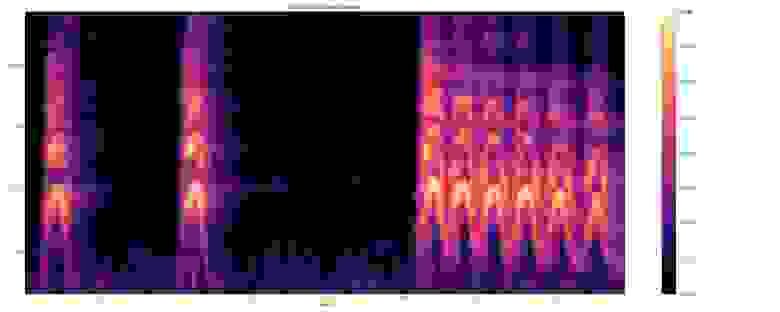
Рассчитываем стабилизированную логарифмическую спектрограмму с помощью log (mel-спектр + 0,01), где используется смещение, чтобы избежать логарифма нуля.

Эти фичи затем преобразуются в непересекающиеся фрагменты в 0,96 секунды, где каждый из них имеет размерность 64 мел-диапазона на 96 фреймов по 10 мс каждый.
Полученные данные затем подаются в модель VGGish для приведения данных в векторный вид.
Классификация
Наконец, нам нужен интерфейс для передачи данных в нейронную сеть и получения результатов.
Возьмем за основу интерфейс YouTube-8M, но изменим его, чтобы удалить этап сериализации/десериализации.
Здесь вы можете ознакомиться с результатами нашей работы. Давайте рассмотрим этот момент подробнее.
Установка
PyAudio использует libportaudio2 и portaudio19-dev, поэтому для работы необходимо установить эти пакеты.
Также вам необходимо загрузить и извлечь в корень проекта архив с сохраненными моделями. Вы можете найти его здесь.
Запуск
Наш проект предлагает возможность использования одного из трех интерфейсов.
Предварительно записанный аудиофайл
Просто запустите python parse_file.py path_to_your_file.wav, и вы увидите в терминале Speech: 0.75, Music: 0.12, Inside, large room or hall: 0.03
Результат зависит от исходных данных. Эти значения выводятся на основе прогноза нейронной сети. Более высокое значение означает более высокую вероятность того, что входные данные принадлежат этому классу.
Захват и обработка данных с микрофона
Веб-интерфейс
Команда python daemon.py реализует простой веб-интерфейс, который по умолчанию доступен по адресу http://127.0.0.1:8000. Мы используем тот же код, что и в предыдущем примере. Вы можете увидеть последние десять прогнозов на странице событий.
Интеграция с IoT
Последний очень важный момент — интеграция с IoT-инфраструктурой. Если вы запустите веб-интерфейс, который мы упоминали в предыдущем разделе, на главной странице можете найти статус подключения клиента DeviceHive и его настройки. Пока клиент подключен, прогнозы будут отправляться на указанное устройство в виде уведомлений.
Клиническая обработка сигналов речи и машинное обучение. Часть 1
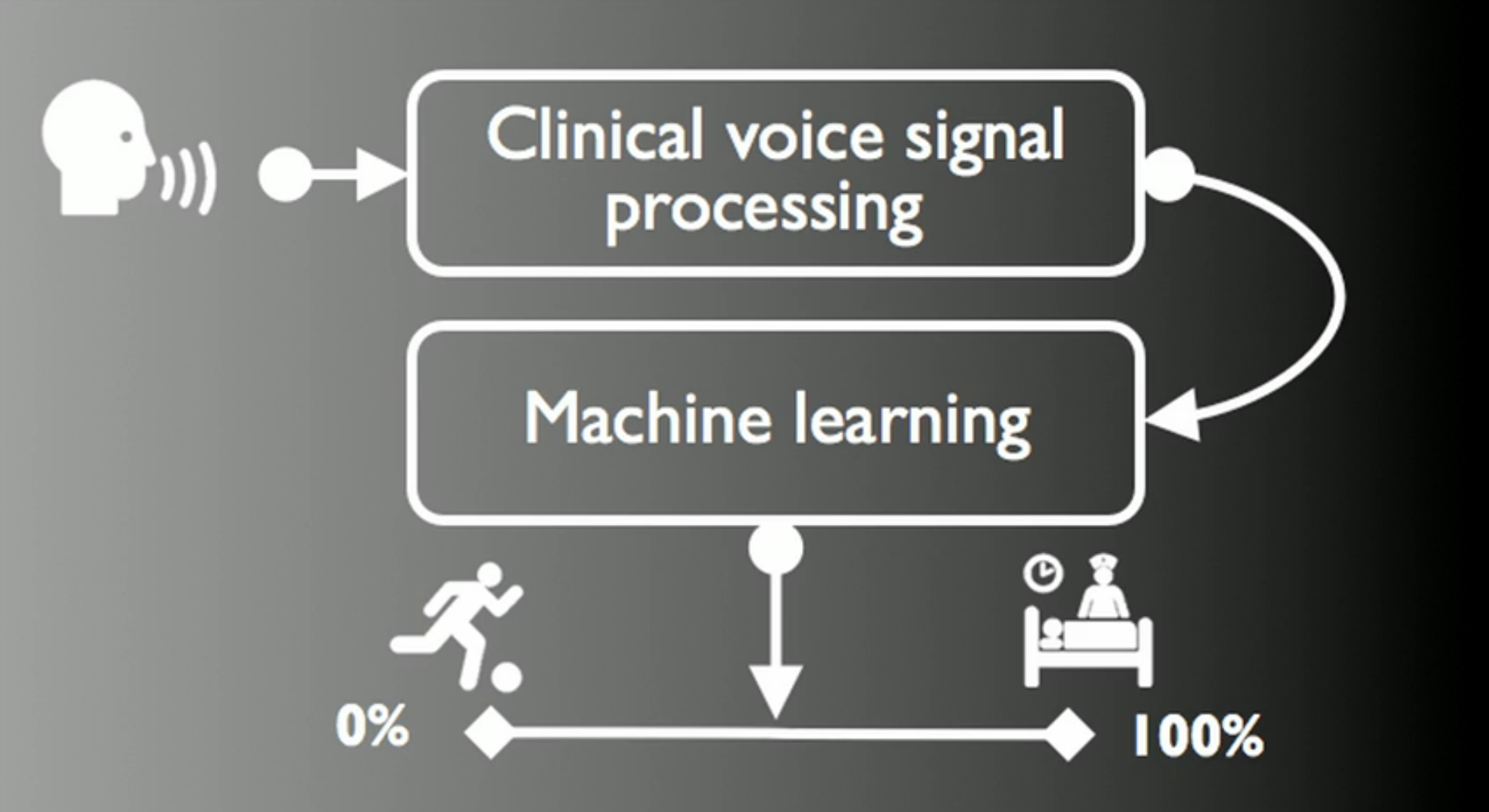
Из выступления Max Little (основателя PVI) на конференции TED в 2012 году.
Здравствуй, Хабрахабр. Данный цикл статей будет посвящен рассмотрению возможности и построению Open Source универсального анализатора нарушений речи.
В данной статье будет рассказано о проекте Parkinson Voice Initiative, посвященному ранней диагностике Болезни Паркинсона по голосу (успешность распознавания составляет 98,6± 2.1% за 30 секунд по телефонному разговору).
Будет произведено сравнение точности используемых в нем алгоритмов выбора особенностей (ВО) – Feature Selection Algorithm – LASSO, mRMR, RELIEF, LLBFS.
Битва между Random Forest (RF) и Supported Vector Machine (SVM) за звание лучшего анализатора в данного рода приложениях.
Начало
Читая статьи по синтезу и распознаванию речи, нашел упоминание о том, что при болезни изменяется голос. Проверив очевидность факта, что я не первый догадался использовать распознавание речи для диагностики болезней (первые клиницисты определили некоторые features — особенности еще в 40-х годах прошлого века, записывая на магнитофонную ленту, а потом вручную анализируя), пошел по ссылкам Гугла. Одна из первых указывала на проект PVI.
Посмотрев выступление основателя на конференции TED 2012 года (доступны субтитры на русском от Ирины Жандаровой), я нашел необходимые аргументы в пользу такого проекта для себя, для врачей и пациентов, и, надеюсь, для программистов.
До 2012 года не существовало биомаркеров Болезни Паркинсона, а существующие скорее для определения динамики развития, нежели чем для первичной диагностики. Кроме этого, вопрос их доступности, цены, времени получения результата и трудоемкости остается открытым.

Отрывок из презентации TED 2012 года (субтитры на русском от Ирины Жандаровой).
Аргументы
| Особенности | Невролог | Проверка голоса |
|---|---|---|
| Не инвазивность | + | + |
| Использование существующей инфраструктуры | + | + |
| Точность | + | + |
| Удаленность | + | |
| Возможность использования не профессионалом | + | |
| Высокая скорость получения результата | + | |
| Очень низкая стоимость | + | |
| Масштабируемость | + |
Также это позволяет часто проводить проверки на наличие заболевания.
Замечательно, подумал я, можно легко сделать такие же анализаторы и по другим болезням, кликнул на вкладку Science и увидел, что этот анализатор начали делать с 2006 года. Срок разработки несколько понизил уровень энтузиазма, но не отбил желание.
Почему этот сайт не дает медицинских советов, если они имеют такой точный анализатор?
На это есть несколько возможных причин (они подходят для любого анализатора болезни):
Судя по всему, данные доступны врачам и исследователям, которые смогут правильно их оценить.
Темпы роста уникальных записей голосов людей вы можете увидеть ниже. Данные за 2012 год (через 8 лет после начала программы)на основе Твиттера Max Little @MaxALittle показывают, что количество людей, проходящих тест, больше зависит от освещения средствами массовой информации и соцсетями, как и везде.
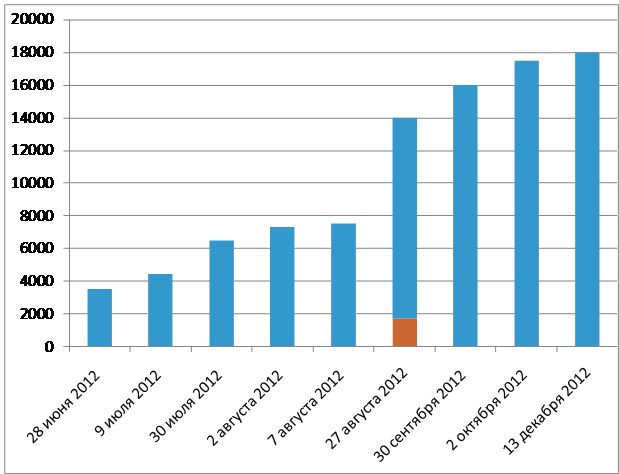
Верхняя граница столбца – общее количество прошедших голосовой тест на проекте PVI. 27 августа были опубликованы данные, что 1700 из 14000 подписавшихся (приблизительно 12% больны Паркинсоном) – красный столбик.
В память о Аароне Шварце он выложил свои публикации в свободный доступ, благодаря чему каждый может с ними ознакомиться, посмотреть технические детали и развить его работы.
To honour Aaron Swartz memory, all my publications to-date, for free: www.maxlittle.net/publications #pdftribute

Основатель проекта Parkinson Voice Initiative, его число Эрдёша равно 4.
В последнем исследовании Max Little от 2012 года, размещенном на сайте – «Новые алгоритмы для обработки сигналов речи для высокоточной классификации Болезни Паркинсона» произведено сравнение 4 алгоритмов выбора особенностей (ВО). Данные, на основе которых проходило исследование, включало 132 особенностей и 263 записей, включающих в себя фонации контрольной группы (61 запись от 10 человек) и лиц, больных Болезнью Паркинсона (202 записи от 33 человек).
Технические детали
Используя все особенности, исследованные в данной работе, SVM, с 10-кратной cross-validation — перекрестной проверкой (ПП), повторенной 100 раз, показал точность 97.7±2.8%, а при использовании RF, с 10-кратной перекрестной проверкой, повторенной 100 раз – достигнутая точность составила 90.2±5.9%.
Наилучшие результаты, описанные в литературе до этого, достигали 93,1±2.9% точности в классификации на выборке из 22 особенностей с использованием алгоритма GP-EM (for genetic programming and the expectation maximization algorithm — для генетического программирования и максимизации ожиданий).
Для повышения качества предсказаний и снижения трудоемкости в обработке сигналов речи в исследовании было решено создать поднабор из 10 особенностей. Всесторонний поиск через все возможные поднаборы достаточно затратный в машинном времени, поэтому были разработаны алгоритмы по ВО, которые предлагают быстрые, принципиальные подходы к уменьшению набора особенностей.
Поднаборы особенностей в каждом случае были выбраны с помощью подхода ПП, используя только обучающую информацию на каждой итерации ПП. Они повторяли процесс ПП в целом 10 раз, где каждый раз особенности (для каждого ВО алгоритма) появлялись в нисходящем порядке выбора. В идеале, каждый раз должен получаться один и тот же порядок, но на практике так не происходит.
RELIEF
RELIEF, используя всего 10 особенностей (из 132) на данных 256 фонаций, показал 98,6± 2.1% точность (истинно положительные: 99.2 ± 1.8%; истинно отрицательные: 95.1 ± 8.4%) с SVM и 93,5% точность с RF.
RELIEF — это алгоритм, основанный на определении «веса» особенности, который повышает особенности, которые разделяют образцы из различных классов. Это соотносится с максимизацией исправляющей способности алгоритмов, и было отнесено к k-Nearest-Neighbor классификатору. Противоположно алгоритму mRMR (рассмотренному ниже), RELIEF использует сопряженность, как неотъемлемую часть процесса выбора особенностей.
LLBFS
Второе место занял алгоритм LLBFS (Local Learning-Based Feature Selection — основанный на локальном обучении выбор особенности) с точностью 97.1 ± 3.7% (истинно положительные: 99.7 ± 1.7%; истинно отрицательные: 89.1 ±13.9%).
LLBFS нацелен на разбиение трудноразрешимых комбинаторных проблем ВО в набор локальных линейных проблем через локальное обучение. Исходным особенностям были назначены веса, которые отражают их важность для проблемы классификации, после чего из них были выбраны особенности, имеющие максимальный вес. LLBFS был задуман, как расширение RELIEF и базируется на ядерной оценки плотности распределения и понятиях максимизации исправляющей особенности.
LASSO
Least Absolute Shrinkage and Selection Operator (LASSO), метод оценки параметров линейной модели, имеющий возможности редукции размерности, занял 3 место с точностью 94.4 ± 4.4% (истинно положительные: 97.5 ± 3.4%; истинно отрицательные: 86.5 ± 14.3%).
LASSO штрафует за абсолютное число коэффициентов, устанавливаемых в линейной регрессии; это ведет к сокращению некоторых из них до нуля, что эффективно показывает связанные с ними особенности. LASSO показало предсказывающие способности (корректно идентифицировало все «правильные» особенности, вносящие вклад в предсказывание ответа) при разреженной установке, когда особенности не высоко сопряжены. В то же время, когда особенности коррелируют, все еще могли быть выбраны «шумные» особенности (не вносящие вклад в ответ) и выброшены некоторые полезные особенности для предсказывания результата.
Minimum Redundancy Maximum Relevance (mRMR), (минимальная избыточность — максимальная релевантность) занял последнее место среди исследуемых алгоритмов ВО, с точностью 94.1 ± 3.9 (истинно положительных: 97.6 ± 3.3; истинно отрицательных: 84.3 ± 13.2).
Алгоритм mRMR использует эвристический критерий для установления баланса между максимальной релевантностью (связью силы особенностей с ответом) и минимальным избытком (связями между парами особенностей). Это жадный алгоритм (основанный на выборе одной особенности за один проход), который акцентирует внимание только на попарную избыточность и игнорирует сопряженность (соединения логическими связями особенностей для предсказывания ответа).
SVM vs. RF
В данном исследовании SVM взял верх над RF. Автор исследования пробовал изменять параметр настройки RF (количество особенностей, среди которых должен осуществляться поиск для построения каждой ветви дерева), но это не дало заметно отличающихся результатов для общей точности RF.
Возможные улучшения, предлагаемые автором исследования:
SVM и RF могут быть настроены для вывода «Не знаю», через введение дополнительного класса, если возможность отнесения к другим классам ниже некоторой предварительно-заданной черты, что позволит повысить точность определения, а также даст повод присмотреться внимательнее к данному случаю врачам.
В следующей части будут обсуждены особенности, на основании которых можно получить такие замечательные результаты.
Распознавание речи
Распознавание речи (англ. Speech Recognition) — процесс преобразования речевого сигнала в цифровую информацию.
Причем, в процессе распознавания вероятность уже полученных признаков Р(Х) не подлежит оптимизации и знаменатель в формуле не испльзуется:
Содержание
Классификация систем распознавания речи [ править ]
Системы распознавания речи классифицируются [1] :
Структура систем распознавания речи [ править ]
Системы распознавания речи впервые появились в 1952 году. С тех пор методы распознавания не раз менялись. Ранее использовались такие методы и алгоритмы, как:
В настоящее время, перечисленные выше методы как правило комбинируются. Их сочетание позволяет получить более высокое качество распознавания, чем использование каждой модели отдельно.
Системы распознавания речи имеют следующие основные модули:
Акустическая модель [ править ]
Фонема (phoneme) — элементарная единица человеческой речи. Примерами фонем являются транскрипции в формате IPA — так, слово hello состоит из фонем [hɛˈləʊ].
Акустическая модель — это функция, принимающая на вход признаки на небольшом участке акустического сигнала (фрейме) и выдающая распределение вероятностей различных фонем на этом фрейме. Таким образом, акустическая модель дает возможность по звуку восстановить, что было произнесено — с той или иной степенью уверенности.
Самой популярной реализацией акустической модели является скрытая Марковская модель (СММ), в которой скрытыми состояниями являются фонемы, а наблюдениями — распределения вероятностей признаков на фрейме.
Рассмотрим подробнее акустическую модель на основе СММ для слова six:
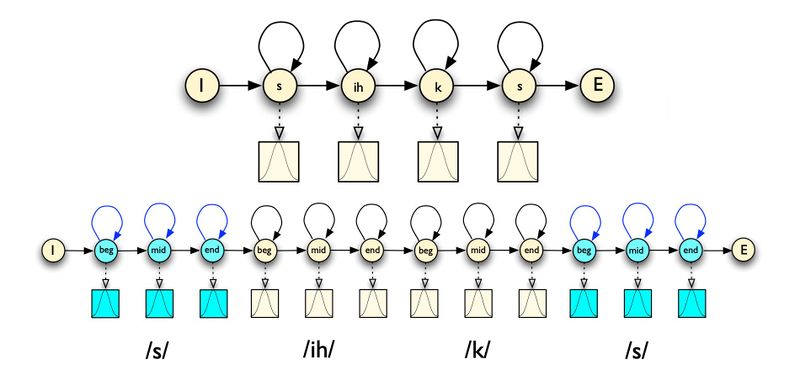
В круглых (скрытых) состояниях изображены фонемы, а в квадратных (наблюдениях) — распределения вероятностей признаков (для упрощения, здесь изображено одномерное распределение). Фонемы часто разбивают на 3 этапа — начало, середину и конец, — потому что фонема может звучать по-разному в зависимости от момента времени её произнесения. Каждое скрытое состояние содержит переход само в себя, так как время произнесения одной фонемы может занять несколько фреймов. Вероятности перехода между фонемами в СММ являются обучаемыми параметрами, и для их настройки используют алгоритм Баума-Велша. Последовательность фонем по набору распределений на фреймах восстанавливают по алгоритму Витерби.

В качестве функции распределения вероятностей признаков часто выбирают смешанную гауссову модель (англ. Gaussian Mixture Model, GMM): дело в том, что одна и та же фонема может звучать по-разному, например, в зависимости от акцента. Так как эта функция является по сути суммой нескольких нормальных распределений, она позволяет учесть различные звучания одной и той же фонемы.
Языковая модель [ править ]
Языковая модель — позволяет узнать, какие последовательности слов в языке более вероятны, а какие менее. Здесь в самом простом случае требуется предсказать следующее слово по известным предыдущим словам. В традиционных системах применялись модели типа N-грамм, в которых на основе большого количества текстов оценивались распределения вероятности появления слова в зависимости от N предшествующих слов. Для получения надежных оценок распределений параметр N должен быть достаточно мал: одно, два или три слова — модели униграмм, биграмм или триграмм соответственно. Внедрение языковой модели в систему распознавания речи позволило значительно повысить качество распознавания за счет учета контекста.
Декодер [ править ]
В ходе работы системы автоматического распознавания речи задача распознавания сводится к определению наиболее вероятной последовательности слов, соответствующих содержанию речевого сигнала. Наиболее вероятный кандидат должен определяться с учетом как акустической, так и лингвистической информации. Это означает, что необходимо производить эффективный поиск среди возможных кандидатов с учетом различной вероятностной информации. При распознавании слитной речи число таких кандидатов огромно, и даже использование самых простых моделей приводит к серьезным проблемам, связанным с быстродействием и памятью систем. Как результат, эта задача выносится в отдельный модуль системы автоматического распознавания речи, называемый декодером. Декодер должен определять наиболее грамматически вероятную гипотезу для неизвестного высказывания – то есть определять наиболее вероятный путь по сети распознавания, состоящей из моделей слов (которые, в свою очередь, формируются из моделей отдельных фонов). Правдоподобие (likelihood) гипотезы определяется двумя факторами, а именно вероятностями последовательности фонов, приписываемыми акустической моделью, и вероятностями следования слов друг за другом, определяемыми моделью языка.
Рассмотрим математическую основу декодеров.
Отбрасывая несущественный на этапе распознавания знаменатель, запишем:
[math]W = argmax [P(W)P(XW)][/math]
[math]W = argmax [P(W)\sum_
[math]W = argmax[P(W)^aMax[P(x_1^T, s_1^T | w_1^N)]][/math]
Различают систему раннего и систему позднего предсказания. В первой выполняется предсказание для акустической и языковой модели независимо, а затем оба предсказания поступают в декодер. При позднем предсказании, вычисленные признаки речи в акустической и языковой моделях без предсказания поступают в декодер и уже на основе их совместного декодирования выполняется предсказание.
Признаки [ править ]
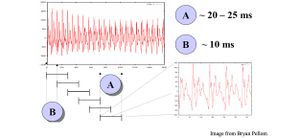
Входные данные представляют собой непрерывную осциллограмму звуковой волны. В задачах распознавания речи эту осциллограмму разбивают на фреймы — фрагменты звукового потока длительностью около 20 мс и шагом 10 мс. Такой размер соответствует скорости человеческой речи: если человек говорит по 3 слова в секунду, каждое из которых состоит примерно из 4 звуков и каждый звук разбивается на 3 этапа, то на этап выходит около 28 мс. Каждый фрейм независимо трансформируется и подвергается извлечению признаков, тем самым образуя векторизированный набор данных для задачи машинного обучения.
Признаки речевых событий, используемые при распознавании речи:
Спектр Фурье получают, используя алгоритм БПФ (Быстрого Преобразования Фурье) с длиной окна равной 2-4 периода основного тона, что составляет около 20 мс. При частоте квантования 10-16 кГц выбирается окно 256 отсчетов.
Для ослабления искажений сигнала, вызванных применением к непрерывному сигналу конечного окна анализа, чаще всего используется окно Хэмминга по формуле:
где n = 1..N, N – размерность окна, S(n) – отсчеты речевого сигнала.
Спектр Фурье в шкале мел
К каждому кадру, полученного Фурье спектра применяется блок мел-фильтров — треугольных пересекающихся фильтров, расположенных наиболее плотно в области нижних частот. Количество фильтров — 26. Для расчета фильтров выбирается верхняя и нижняя частота. Затем осуществляется переход от частотной шкалы к мел-шкале по формуле:
[math]M(f) = 1127*ln\left(1 + \frac
На мел-шкале выбираются линейно расположенные точки (28 точек для 26 фильтров), после чего, производится обратный переход в частотную область.
Коэффициенты линейного предсказания
Модель линейного предсказания речи предполагает, что передаточная функция голосового тракта представляется полюсным фильтром с передаточной функцией:
где p – число полюсов и [math]a_0 = 1[/math] ; Фильтр с такой передаточной функцией позволяет описать поведение сглаженного спектра речевого сигнала с хорошей точностью, за исключением назализованных звуков. Коэффициенты фильтра < [math]a_i[/math] >– выбираются путем минимизации среднеквадратичной ошибки предсказания, просуммированной на окне анализа.
Кепстр (cepstrum) сигнала на основе спектра Фурье вычисляется путем применения косинусного Фурье преобразования к логарифму спектра:
где [math]s_i[/math] – логарифм спектра, N – количество отсчётов спектра, [math]C_
Кепстральные коэффициенты, полученные приведённым способом из мел спектра Фурье, широко используются для распознавания с помощью марковских моделей и носят название MFCC (Mel-frequency cepstral coefficients).
Показатели оценки качества распознавания речи [ править ]
Существуют различные по сложности и прикладному значению задачи распознавания: изолированных слов (команд); ключевых слов в потоке речи; связанной речи (тщательное проговаривание текста с паузами между словами); слитной речи (разделяют диктовку в узкой тематической области, и спонтанную речь, например, в диалоге между людьми).
Оценка системы, распознающей отдельные команды, не представляет каких-либо трудностей – количество неправильно распознанных команд делится на общее количество испытаний и получается процент ошибки. Для систем, распознающих слитную речь, ситуация не столь проста.
Основными показателями качества распознавания слитной речи являются:
Поскольку с развитием речевых технологий показатель WER все более приближается к нулю, то значение улучшения WER более наглядно, чем улучшение точности распознавания слов.
[math]WER = \frac
State of the Art в автоматическом распознавании речи [ править ]
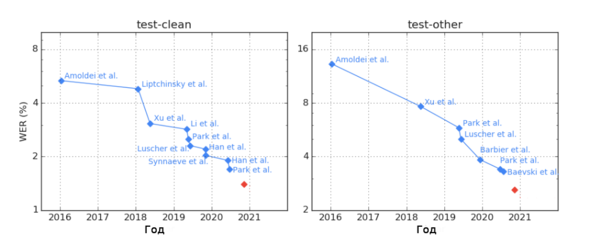
Для обучения современных систем распознавания речи требуются тысячи часов размеченной речи, однако получение размеченных данных в необходимом объеме (особенно с учетом разнообразия существующих языков) затруднительно. Это повлияло на то, что сейчас в машинном обучении для распознавания речи успешно используется обучение с частичным привлечением учителя, которое позволяет сначала обучать модель на большом объеме неразмеченных данных, а потом корректировать ее при помощи размеченных.
Основная идея состоит в том, что множество моделей Конформеров при помощи алгоритма wav2vec предварительно обучается на неразмеченных данных, при этом одновременно с этим на основе них генерируются размеченные. Таким образом, неразмеченные данные используются для двух целей: для обучения модели и для генерации размеченных данных, которые используются для дальнейшего обучения модели алгоритмом noisy student.
Конформер [ править ]
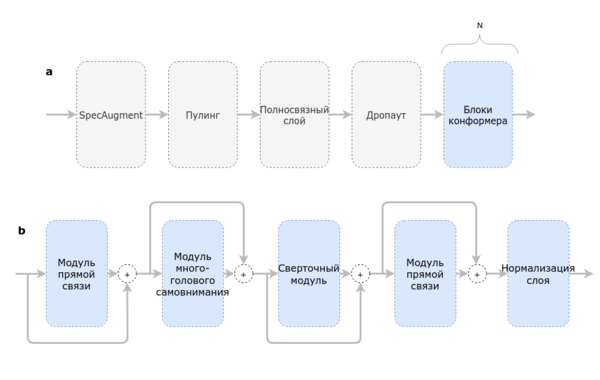
Сначала данные, подающиеся на вход Конформеру, проходят аугментацию. В применении к распознаванию речи, используется метод аугментации SpecAugment. SpecAugment применяет к мел спектрограмме три вида деформаций: искажение времени (удлинение или сжатие некоторого промежутка записи), удаление некоторого временного промежутка из записи, и удаление некоторого промежутка частот. Таким образом, при обучении на зашумленных с помощью SpecAugment данных сеть обучается на признаках, устойчивых к деформации во времени, частичной потере частотной информации и потере небольших сегментов речи. Конформер обрабатывает итоговые аугментированные входные данные с помощью сверточной нейронной сети, состоящей из слоя пулинга, полносвязного слоя и дропаута, а затем с помощью последовательности блоков Конформера.
Блоки Конформера — это последовательность из двух модулей прямой связи (англ. feed forward), между которыми расположены модуль многоголового самовнимания (англ. Multi-Head Self Attention) и сверточный модуль, с последующей нормализацией слоя (англ. layer normalization).
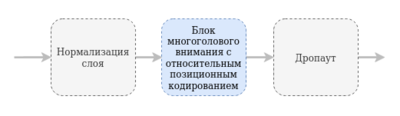
Модуль многоголового самовнимания
В модуле используется блок многоголового внимания с относительным позиционным кодированием (англ. Multi-Head Attention with Relative Positional Encoding). Такой блок (изначально часть архитектуры Трансформер-XL [5] ) используется с целью исправить два недостатка Трансформера: ограничение на длину входа (что не позволяет модели, например, использовать слово, которое появилось несколько предложений назад) и фрагментацию контекста (последовательность разбивается на несколько блоков, каждый из которых обучается независимо). Для достижения этой цели используются два механизма: механизм повторения (англ. reccurence mechanism) и относительное позиционное кодирование (англ. relative positional encoding). Механизм повторения позволяет использовать информацию из предыдущих сегментов. Как и в оригинальной версии, Трансформер-XL обрабатывает первый сегмент токенов, но сохраняет выходные данные скрытых слоев. При обработке следующего сегмента каждый скрытый слой получает два входа: результат предыдущего скрытого слоя этого сегмента, как в Трансформере, и результат предыдущего скрытого слоя из предыдущего сегмента, который позволяет модели создавать зависимости от далеких сегментов.
Однако, с использованием механизма повторения возникает новая проблема: при использовании исходного позиционного кодирования каждый сегмент кодируется отдельно, и в результате токены из разных сегментов закодированы одинаково.
Относительное позиционное кодирование почти полностью совпадает с абсолютным позиционным кодированием из оригинального Трансформера, но вместо позиции внутри сегмента используется расстояние между сегментами. Кроме того, добавляются два вектора параметров, задающие важность расстояния и содержания второго токена относительно первого.
Использование модуля многоголового самовнимания с относительным позиционным кодированием позволяет сети лучше обучаться при различной длине ввода, а результирующая архитектура получается более устойчивой к неоднородности длины высказывания.

Модули прямой связи

В отличие от Трансформера, в котором единственный модуль прямой связи следует за модулем внимания и состоит из двух линейных преобразований и нелинейной активации между ними, Конформер представляет собой два модуля прямой связи, состоящих из слоя нормализации и двух линейных слоев. Кроме того, для регуляризации используется функция активации swish и дропаут.
wav2vec [ править ]
Подход wav2vec [10] основан на самообучении на мел спектрограммах.
Noisy student [ править ]
Вариация классического алгоритма самообучения: на каждой итерации модель-ученик обучается на аугментированных данных.
Применение [ править ]
Системы распознавания речи начали развиваться как специальные сервисы для людей с ограниченными возможностями, но также нашли применение в различных сферах бизнеса, таких как:
Основные отрасли применения:



