Как дубли страниц сайта влияют на его продвижение
 Рад приветствовать вас друзья. Сегодняшняя статья будет на тему — вред дублей страниц при продвижении и раскрутке сайта. Для начала давайте дадим определение самому термину. Дубли страниц – понятие дублирования одинакового контента на разных страницах сайта. На сегодняшний день алгоритмы поисковых систем развиты настолько, что без проблем могут определить наличие дублей страниц в пределах одного сайта. Казалось бы, а причем здесь мой сайт, ведь уникальность материала внутри сайта не сравнить с его уникальностью в целом по Интернету? Но реалии таковы, что при выявлении разных дублей страниц, поисковые системы могут крайне негативно проявить себя по отношению к этому сайту.
Рад приветствовать вас друзья. Сегодняшняя статья будет на тему — вред дублей страниц при продвижении и раскрутке сайта. Для начала давайте дадим определение самому термину. Дубли страниц – понятие дублирования одинакового контента на разных страницах сайта. На сегодняшний день алгоритмы поисковых систем развиты настолько, что без проблем могут определить наличие дублей страниц в пределах одного сайта. Казалось бы, а причем здесь мой сайт, ведь уникальность материала внутри сайта не сравнить с его уникальностью в целом по Интернету? Но реалии таковы, что при выявлении разных дублей страниц, поисковые системы могут крайне негативно проявить себя по отношению к этому сайту.
Давайте рассмотрим, основные опасности дублей страниц:
— Смена релевантной страницы сайта (которая продвигается по определенному запросу и наиболее точно отвечает ему) на страницу дубль. Очень частое явление, последствия которого, существенное понижение позиций по этому запросу.
— Ухудшение индексации сайта ПС. Если в течении продолжительного времени на вашем ресурсе размещено много страниц, то соответственно количество дублей как минимум будет таким же, а очень часто и в 3-5 раз превышать количество полезных статей.
— Потеря полезного внутреннего ссылочного веса в следствии его растекания по множеству «мусорных» страниц сайта.
— Попадание сайта под действия фильтров поисковых систем. Для Яндекса – это фильтр АГС, для Google – Panda. В этом случае переходы из поисковых систем могут вообще равняться 0.
— Сильное снижение позиций по ключевым запросам. При появлении дублей на сайте и их индексации, позиции вашего ресурса могут сильно упасть.
Также, нужно отметить, что бывают страницы полного и неполного дубля.
Полный дубль – абсолютно точное повторение содержимого одной страницы, другой страницей сайта, но с разными url-адресами.
В первом варианте в конце адреса нет слеша, а во втором он уже присутствует. Для поисковых систем, это абсолютно разные страницы, с одинаковым содержимым.
Неполный дубль – частичное совпадение информации с разных страниц сайта.
Яркий пример тому, анонсы постов блога в ленту RSS, или же анонсы записей в страницах категорий (движок WordPress).
http://site.ru/seo/statja-o-dubljah-stranic/ — отдельная статья на блоге
http://site.ru/category/seo/ — анонс записи этой же статьи, но с частичным дублей
Дубли страниц — методы определения
Метод №1. Зайдите в панель инструментов Вебмастера и перейдите по адресу Вид в поиске – Оптимизация HTML.

Перед вами откроется окно, в котором необходимо обратить внимание на:
Повторяющееся метаописание – страницы с одинаковым описанием (description)
Повторяющиеся заголовки (теги title) – страницы сайта с одинаковым title
Дело в том, что обычно на дублированных страницах, кроме контента и содержимого, дублируются еще и заголовки с метаописаниями. Поэтому, таким способом легко определить дубли страниц.
Метод №2. Если сайт не добавлен в панель инструментов, то можно воспользоваться поиском по фрагменту текста. Для этого скопируйте часть текста (1 предложение, или несколько слов), заключите его в кавычки и добавьте к нему такую приставку — site:vash-site.ru
В результате должен получится такой запрос:
«Фраза, которая мне напоминает дубль» site:vash-site.ru
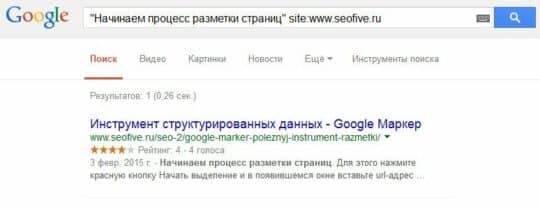
В приведенном примере, все хорошо, но очень часто бывает совсем по-другому.
Метод №3. В поисковой строке Google введите оператор:
опуститесь в самый низ страницы и в конце списка перейдите по ссылке – Показать скрытые результаты.
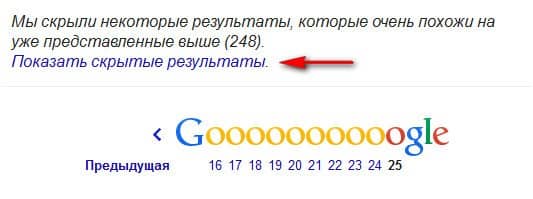
Внимательно изучите предоставленные вам результаты поиска для выявления дублей страниц.
Идем в расширенный поиск Яндекса, указываем нужный запрос в кавычках, и адрес проверяемого сайта.
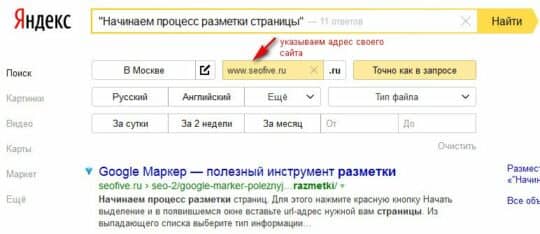
После нажатия кнопки Найти, будет предоставлен результат поиска.
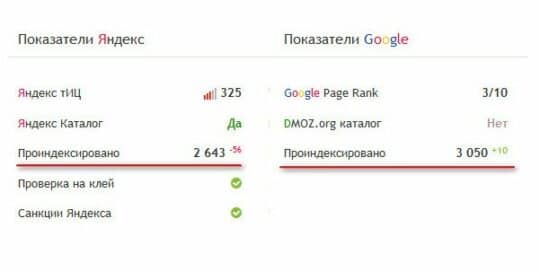
Еще можно сравнить количество проиндексированных страниц обеими ПС. Если результат, будет существенно отличатся, то с большой долей вероятности можно говорить о существовании дублей в одной из ПС.
С помощью специализированных программ.
Есть два отличных инструмента, которые полностью автоматизируют поиск дублированных страниц на сайте (и не только).
Описывать принцип их работы не имеет смысла, так как для анализа необходимо добавить url-адрес сайта и запустить сам процесс сканирования. После его окончания в соответствующих полях будет результат работы.
Методы решения проблем
Самым первым шагом по нахождению и исправлению мусорных страниц, является технический анализ сайта, с помощью которого можно определить причину появления дублей. После того, как причина определена можно приступать к решению проблемы.
где адрес http://site.ru/novosti/jeto-osnovnaja-stranica-sajta/ и будет основным. На основном адресе, этот тег указывать не нужно.
4) Для Google, который практически игнорирует этот файл, необходимо сделать следующую вставку в исходный код страниц дублей:
Таким образом, мы указываем на запрет индексирования роботом, конкретных страниц сайта.
Для Яндекса, этот метод также хорошо работает.
5) Метод использования 404 ошибки. Реализуется очень просто. Необходимо добиться от страниц дублей 404 ошибки, тогда при очередном сканировании роботами ПС, они будут выброшены с индекса.
В обязательном порядке периодически проверяйте свои сайты на наличие страниц дублей, чтобы своевременно реагировать на это и вовремя устранять появившиеся ошибки.
Что такое дубли страниц сайта: как появляются дубли
Вступление
Дубли страниц это повторение содержимого статьи или ее части под разными URL в свободной выдаче поисковиков. Дубли страниц могут создаваться системой управления сайтом автоматически или администратором сайта вручную (чаще не преднамеренно). В этой статье мы говорим о дубле страниц в рамках одного домена.
Что такое дубли страниц
Прежде всего, давайте поймем, что такое дубли страниц.
Под дублями страниц понимается, что одну и ту же страницу ресурса или ее части можно найти по разным URL адресам.
Пойдем дальше, вспомним, как формируется контент сайта. Статья публикуется на сайте и записывается под своим URL в базу данных. Это и есть оригинал статьи с уникальным адресом URL. Нельзя сказать, что он единственный в математическом понимании. Любой SEF модуль перепишет его в SEF ссылку. Но опять-таки, эта SEF ссылка уникальна в единственном экземпляре.
В идеале, в индекс должно попадать столько URL страниц, сколько опубликовано. Это и есть золотое правило SEO — каждая страница должна быть доступна только по одному адресу. А что же происходит в реальности?
Прежде чем разобраться откуда берутся дубли страниц, поймем, почему поисковики «не любят» сайты с большим количеством дублированных страниц.
 что такое дубли страниц сайта
что такое дубли страниц сайта
Ранжирование сайта и дубли страниц
Поисковики постоянно сканирует не закрытое от них содержание сайта. На сканирование и индексацию тратятся реальные ресурсы поисковых систем. Было бы странно, если поисковым системам нравились сайты, заполненные дублированными страницами. Ведь, по сути, получается, что поисковик листает одну и ту же страницу десятки и сотни раз.
Отсюда и появляются фильтры, накладываемые на сайты с большим количеством дублей, или сайт понижается в ранжировании (читать про ранжирование). Снижение ранжирования, отодвигает позиции в выдаче, а отсюда борьба «сеошников» с этими самыми дублями страниц. Вот такой логический цикл.
Но это не самая важная причина борьбы поисковиков с дублями страниц. Более веской причиной включения в поисковые алгоритмы санкций за дублирование страниц, стала борьба со ссылочным продвижением, когда масса ссылок разбрасывалась по сайту по одинаковым текстам (черные схемы оптимизации).
Причина появления дублей
Поняв, что такое дубли страниц сайта, давайте разберемся в причинах появления дублей страниц, в рамках одного домена. В рамках одного домена в создании дублей страниц есть следующие виновники:
Примечание: Слышал мнение, что дубли страниц плодят SEO расширения, которые вы используете на сайте. Это не так. SEO расширения не создают дубли, они их выявляют и записывают в свою базу. От того, что в их базе появляются новые дубли, они не виноваты.
Как появляются дубли страниц
Проследим, как появляются дубли на сайте, без примеров, только общие тенденции.
Зачем бороться с дублями страниц
Кроме опасности попасть из-за дублей страниц под поисковой фильтр, есть еще пару причин этой борьбы:
Выводы
Мы разобрались, что такое дубли страниц сайта и поняли, чтобы снизить количество дублей необходимо:
Как быстро найти и удалить все дубли страниц на сайте: 8 способов + лайфхак

Дубли — это страницы с одинаковым контентом. Они могут появиться при автогенерации, некорректных настройках, вследствие изменения структуры сайта или при неправильной кластеризации. Дубликаты негативно влияют на SEO-продвижение, так как поисковые системы хуже ранжируют страницы с похожим контентом. Кроме того, большое количество слабых, несодержательных или пустых страниц понижают оценку всего сайта. Поэтому важно своевременно отслеживать и устранять подобные проблемы.
В данной статье подробно рассмотрим, как найти и удалить дубли, а также предотвратить их появление.
Виды дублей
Дубликаты бывают 3-х видов:
Зачастую при анализе обращают внимание лишь на полные совпадения, но не стоит забывать про частичные и смысловые, так как к ним поисковики тоже относятся критично.
Полные
Полные дубли ухудшают хостовые факторы всего сайта и осложняют его продвижение в ТОП, поэтому от них нужно избавиться сразу после обнаружения.
Избавиться от полных дубликатов можно, поставив редирект, убрав ошибку программно или закрыв документы от индексации.
Частичные
Частичные дубликаты оказывают не такое сильное влияние на сайт, как полные. Однако если их много — это ухудшает ранжирование веб-ресурса. Кроме того, они могут мешать продвижению и по конкретным ключевым запросам. Разберем в каких случаях они возникают.
Характеристики в карточке товара
Нередко, переключаясь на вкладку в товарной карточке, например, на отзывы, можно увидеть, как это меняет URL-адрес. При этом большая часть контента страницы остаётся прежней, что создает дубль.
Пагинация
Если CMS неправильно настроена, переход на следующую страницу в категории меняет URL, но не изменяет Title и Description. В итоге получается несколько разных ссылок с одинаковыми мета-тегами:
Такие URL-адреса поисковики индексируют как отдельные документы. Чтобы избежать дублирования, проверьте техническую реализацию вывода товаров и автогенерации.
Также на каждой странице пагинации необходимо указать каноническую страницу, которая будет считаться главной. Как указать этот атрибут, будет рассмотрено ниже.
Подстановка контента
Часто для повышения видимости по запросам с указанием города в шапку сайта добавляют выбор региона. При нажатии которого на странице меняется номер телефона. Бывают случаи, когда в адрес добавляется аргумент, например «wt_city_by_default=..». В результате, у каждой страницы появляется несколько одинаковых версий с разными ссылками. Не допускайте подобной генерации или используйте 301 редирект.
Версия для печати
Версии для печати полностью копируют контент и нужны для преобразования формата содержимого. Пример:
Поэтому необходимо закрывать их от индексации в robots.txt.
Смысловые
Смысловые дубли — это статьи, написанные под запросы из одного кластера. Чтобы их обнаружить, нужно воспользоваться результатом парсинга сайта, выполненного, например, программой Screaming Frog. Затем скопировать заголовки всех статей и добавить их в любой Hard-кластеризатор с порогом группировки 3,4. Если несколько статей попали в один кластер – оставьте наиболее качественную, а с остальных поставьте 301 редирект.
Варианты устранения дубликатов
При дублировании важно не только избавиться от копий, но и предотвратить появление новых.
Физическое удаление
Самым простым способом было бы удалить повторяющиеся страницы вручную. Однако перед удалением нужно учитывать несколько важных моментов:
Настройка 301 редиректа
Создание канонической страницы
Указав каноническую страницу, вы показываете поисковым системам, какой документ считать основным. Этот способ используется для того, чтобы показать, какую страницу нужно индексировать при пагинации, сортировке, попадании в URL GET-параметров и UTM-меток. Для этого на всех дублях в теге прописывается следующая строчка со ссылкой на оригинальную страницу:
Например, на странице пагинации главной должна считаться только одна страница: первая или «Показать все». На остальных необходимо прописать атрибут rel=»canonical», также можно использовать теги rel=prev/next.
Для второй и последующей:
Для решения этой задачи на сайтах WordPress используйте плагины Yoast SEO или All in One SEO Pack. Чтобы все заработало просто зайдите в настройки плагина и отметьте пункт «Канонические URL».
Запрет индексации файла Robots.txt
Файле robots.txt — это своеобразная инструкция по индексации для поисковиков. Она подойдёт, чтобы запретить индексацию служебных страниц и дублей.
Для этого нужно воспользоваться директивой Disallow, которая запрещает поисковому роботу индексацию.
Disallow: /dir/ – директория dir запрещена для индексации
Disallow: /dir – директория dir и все вложенные документы запрещены для индексации
Disallow: *XXX – все страницы, в URL которых встречается набор символов XXX, запрещены для индексации.
Внимательно следите за тем какие директивы вы прописываете в robots. П ри некорректном написании можно заблокировать не те разделы либо вовсе закрыть сайт от поисковых систем.
Запрет индексировать страницы действует для всех роботов. Но каждый из них реагирует на директиву Disallow по-разному: Яндекс со временем удалит из индекса запрещенные страницы, а Google может проигнорировать правило, если на данный документ ведут ссылки.
Причины возникновения
Обычно при взгляде на URL-адрес можно сразу определить причину возникновения дубля. Но иногда нужен более детальный анализ и знание особенностей CMS. Ниже приведены 6 основных причин, почему они могут появляться:
Некоторые ошибки могут появиться и по другим причинам, например, если не указан редирект со старой страницы на новую или из-за особенностей конкретных скриптов и плагинов. С каждой такой проблемой нужно разбираться индивидуально.
Отдельным пунктом можно выделить страницы, дублирующиеся по смыслу. Такая ошибка часто встречается при неправильной разгруппировке. Подробнее о том как ее не сделать читайте по ссылке.
Как дубликаты влияют на позиции сайта
Дубли существенно затрудняют SEO- продвижение и могут стать препятствием для выхода запросов в ТОП поисковой выдачи.
Чем же они так опасны:
Инструменты для поиска
Как найти дублирующие ся документы? Это можно сделать с помощью программ и онлайн-сервисов. Часть из них платные, другие – бесплатные, некоторые – условно-бесплатные (с пробной версией или ограниченным функционалом).
Яндекс.Вебмастер
Чтобы посмотреть наличие дубликатов в панели Яндекса, необходимо:
Страницы исключаются из индекса по разным причинам, в том числе из-за повторяющегося контента. Обычно конкретная причина прописана под ссылкой.
Netpeak Spider
Netpeak Spider – платная программа с 14-дневной пробной версией. Если провести поиск по заданному сайту, программа покажет все найденные ошибки и дубликаты.
Бесплатным аналогом этих программ является Xenu, где можно проанализировать даже не проиндексированный сайт.
При сканировании программа найдет повторяющиеся заголовки и мета-описания.
Screaming Frog Seo Spider
Screaming Frog Seo Spider является условно-бесплатной программой. До 500 ссылок можно проверить бесплатно, после чего понадобится платная версия. Наличие дублей программа определяет так же, как и Xenu, но быстрее и эффективнее. Если нет денег на покупку рабочий ключ можно найти в сети.
Сервис-лайфхак
Для тех кто не хочет осваивать программы, рекомендую воспользоваться техническим анализом от Wizard.Sape. Аудит делается в автоматическом режиме в среднем за 2-4 часа. Цена вопроса — 690 рублей. В течении 30 дней бесплатно можно провести повторную проверку.
Помимо дублированного контента и мета-тегов инструмент выдает много полезной информации:
Вывод
Полные и частичные дубли значительно осложняют продвижение сайта. Поэтому обязательно проверяйте ресурс на дубликаты, как сгенерированные, так и смысловые и применяйте описанные в статье методы для их устранения.
Дублирующие страницы: как найти и устранить


Узнайте из статьи, чем опасны повторяющиеся страницы на сайте, какие они бывают, а также как найти дубли страниц. Мы расскажем про способы устранения полностью или частично похожих страниц, чтобы вы могли обезопасить свой ресурс от негативных последствий.
Статья будет полезна практикующим SEO-специалистам и владельцам сайтов.
Что такое дубль и чем он опасен
Дубликат — полное или частичное повторение контента на двух или более страницах сайта. Повторы плохо воспринимаются поисковиками и ведут к ухудшению ранжирования, а иногда и к попаданию под фильтры.
Основные проблемы, возникающие при наличии дубликатов:
1. Ухудшение индексации сайта. Наличие «двойников» увеличивает количество страниц сайта, которые нужно обойти поисковому роботу. Это плохо как для огромного проекта с несколькими тысячами страниц, так и для небольшого ресурса. Ведь робот за обход не сможет охватить все страницы и проиндексировать их. Помимо того, в индекс могут попасть сначала страницы-дубликаты, продвижение которых не планировалось, в то время нужные останутся без внимания и индексация исходных версий страниц затянется.
2. Ухудшение ранжирования всего ресурса в поисковой системе из-за неуникальности контента.
3. Неправильное распределение внутреннего ссылочного веса. Страница-дубликат может получить больший ссылочный вес, чем страница-оригинал за счет ошибок в перелинковке. В итоге значимой становится вовсе не та страница.

4. Изменение релевантной страницы в поиске. Поисковый алгоритм на основе пользовательского поведения может посчитать дубль релевантнее запросу и сменить страницу в выдаче. А это может приводить к снижению позиций.
Например, у вас есть 2 страницы:
URL разный, а контент полностью или частично дублируется. В поиске останется только одна страница, потому что поисковики не ранжируют схожие документы. А поскольку позиции рассчитываются на основе множества факторов, при смене релевантной страницы в выдаче позиции меняются. Часто в негативную сторону.
5. Неправильное распределение внешнего ссылочного веса. Когда пользователь захочет поделиться с кем-то ссылкой на определенную страницу, то высока вероятность, что он будет ссылаться именно на дубликат. Это грозит тем, что ссылочный вес достанется странице-дублю.
Как Google относится к дубликатам
Google серьезно относится к проблеме повторяющихся страниц, особенно при их большом количестве.
Предполагается, что дублирование может возникать при манипуляции рейтингом в поисковой системе: для увеличения трафика обманным путем или введения пользователя в заблуждение.
Одинаковые страницы появляются и без злого умысла у интернет-магазинов, форумов, при разных версиях сайта (для мобильных устройств, для печати).
Алгоритм поисковика настроен таким образом, чтобы индексировать и выводить в выдачу страницы с уникальным контентом. И если робот посчитает контент дубликатом — пересматривается рейтинг ресурса в сторону снижения, вплоть до полного отсутствия в выдаче.
Как Яндекс относится к дублям страниц
Для Яндекса дубли не так важны. В случае обнаружения «двойников» система просто удалит одну из повторяющихся страниц из выдачи. А какая-то это будет — оригинальная или дубль — неизвестно. Если Яндекс удалит основную версию страницы, которую вы продвигаете, то позиции сайта снизятся.
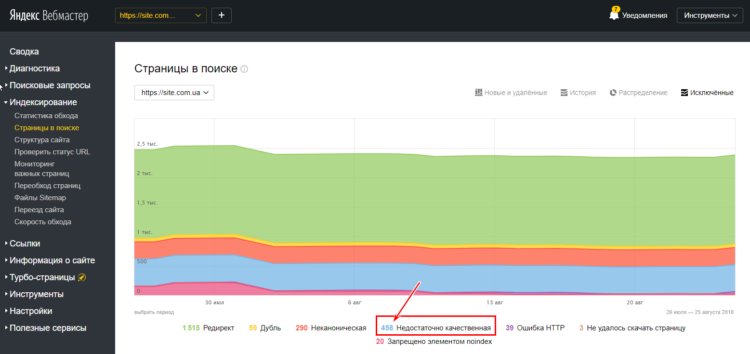
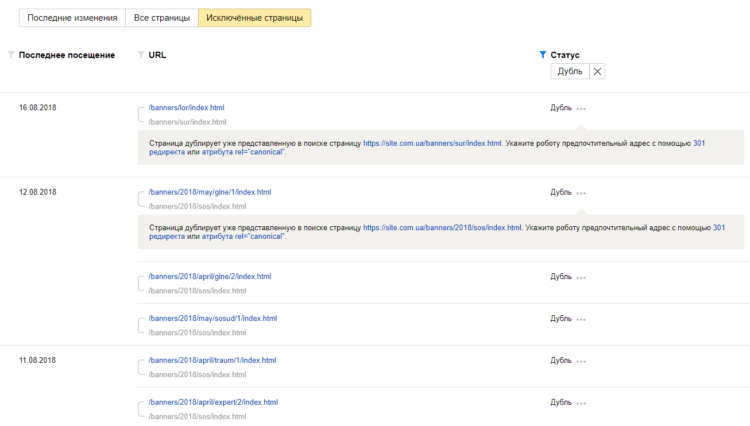
Например, в Яндекс Вебмастере вы сможете видеть постоянное движение во вкладке «Страницы в поиске» (исключенные, недостаточно качественные страницы), но при этом их количество в выдаче остается неизменным.
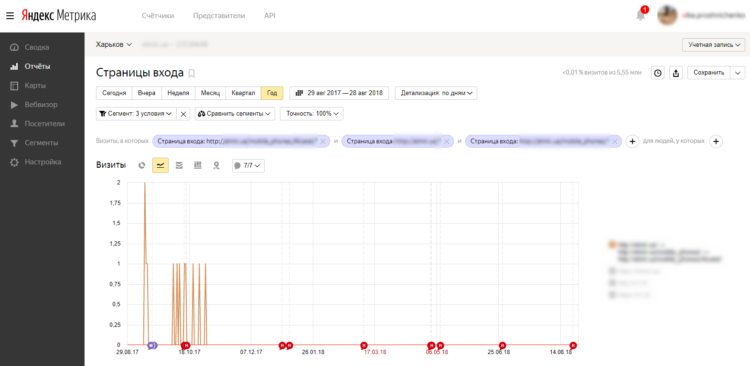
Или Яндекс. Метрика показывала переходы на страницу, а потом они резко прекратились. Это значит, что в индекс попала дублирующая страница. Статистика будет искажена.
Виды дублей и причины их возникновения
Чтобы начать поиск и устранение дублей, важно определиться с их типом, поскольку процесс очистки будет отличаться. Итак, все дубликаты на сайте делят на две большие группы:
Причины полных дублей:
| Тип частичных дублей | Суть | Пример |
|---|---|---|
| Страницы пагинации, фильтров, сортировок | Изменение порядка выводимого ассортимента продукции в каталоге может поменять URL с сохранением всей информации, заголовков и мета-тегов | http://site.com/ catalog/category/ – изначальный адрес страницы категории |
http://site.com/ catalog/category/?page=1 – страница пагинации
http://site.com/catalog/ shapka?razmer=1 – карточка товара с размером. Цена и характеристики при этом не меняются.
http://site.com/ catalog/print – черно-белая версия для печати
Причины частичных дублей:
Дубликаты по title
Копии title негативно сказываются на продвижении ресурса. Это связано с особенностями и функциями тега: текст из главного заголовка отображается в выдаче в виде ссылки на страницу. Если у вас окажутся повторы, то поисковый робот выберет только одну из дублирующихся страниц, даже если контент будет отличаться.
Важно!
Если 2 разных товара названы одинаково, стоит уникализировать название или включить в title артикул.
Вы продаете холодильники. У вас в каталоге есть несколько одинаковых названия «Холодильники Samsung». Чтобы сделать тег уникальным, важно добавить то, чем они отличаются:
Холодильники Samsung (56894–254).
Типичные дубли для разных движков
Для некоторых движков есть типичные дубли. Например:
1. Битрикс при формировании URL для каталога выдает дубликаты детальных страниц при отсутствии привязки к нескольким разделам:
2. WordPress создает копии несуществующих документов:
3. Joomla формирует два URL — «человеческий» и системный, из-за чего появляются копии страниц:
Обычно такие дубликаты устраняются через SEO-плагины и с помощью правильной структуры сайта.
Смысловые дубликаты
Суть этого вида дубликатов: тексты могут быть технически уникальными, но схожими по смыслу. То есть одна и та же информация подается разными словами. Самыми распространенными типами являются:
Этот тип относится не к техническим дубликатам, когда повторы возникают из-за неправильных настроек, а к дубликатам, созданным человеком по невнимательности.
Региональные дубли
Дубли по регионам возникают, когда вы предлагаете товары или услуги в разные города и страны, но при этом используете одинаковый контент.
У вас есть сайт по продаже запчастей для автомобилей. Работаете вы в трех странах — Украине, России и Белоруссии. Весь ресурс русскоязычный. Никаких отличий в работе, товарах и услугах нет, и вы решаете для каждой страны скопировать один и тот же контент. И вот тогда страницы удваиваются или утраиваются, дублируя друг друга. А это плохо влияет на ранжирование и индексацию в каждой стране.


Если вы ориентированы на один регион, переживать о наличие таких дублей не нужно. Однако при работе с разными странами поиск дублей страниц сайта обязателен.
Синонимические текстовые дубли
Ситуация возникает при описании одинаковых услуг и товаров с помощью синонимов, например:
Мы говорим про одно и то же только разными словами, а смысл не меняется — по сути это рерайтинг в рамках одного сайта. При этом URL, Title, Description, заголовок будут отличаться.
Примером синонимических дублей являются страницы с частично схожей информацией:
есть страница «Особенности колясок-трансформеров», где расписаны плюсы и минусы моделей, которые помогут определиться с выбором. А есть отдельная страница «Как подобрать коляску-трансформер». В текстах может встретиться пересечение информации, актуальной для подбора конкретной модели: она будет дублироваться, пусть и разными словами.
Такого повторения контента следует избегать, поскольку поисковики накладывают санкции на сайты с синонимическими дублями. Так, они называют такие страницы низкокачественными, а в итоге может ухудшиться ранжирование и позиции всего ресурса понизятся.
Текстовые дубли (полные или фрагментарные)
Бывает, что текст полностью или частично повторяется на разных страницах. Причина — умышленное или неосознанное копирование контента.
Например, у вас есть статья в блоге о том, как выбрать ноутбук. И часть информации вы копируете на страницу каталога.
Такие страницы поисковый робот приравняет. При этом их релевантность время от времени изменяется, а порой страницы и вовсе не попадают в индекс.
Как найти дубли страниц на сайте
Принцип поисковых систем: одна страница = один URL = уникальная информация на странице.
Поэтому чтобы уберечься от потери трафика и позиций в выдаче, продвигать и развивать ресурс, важно найти и удалить все дубли.
Ручной мониторинг выдачи через «site:»
Страницы, повторяющиеся полностью или фрагментами, найти на сайте легко с помощью такой комбинации:
site: имя сайта пробел фрагмент текста.
В выдаче появятся все страницы с искомой фразой на сайте:
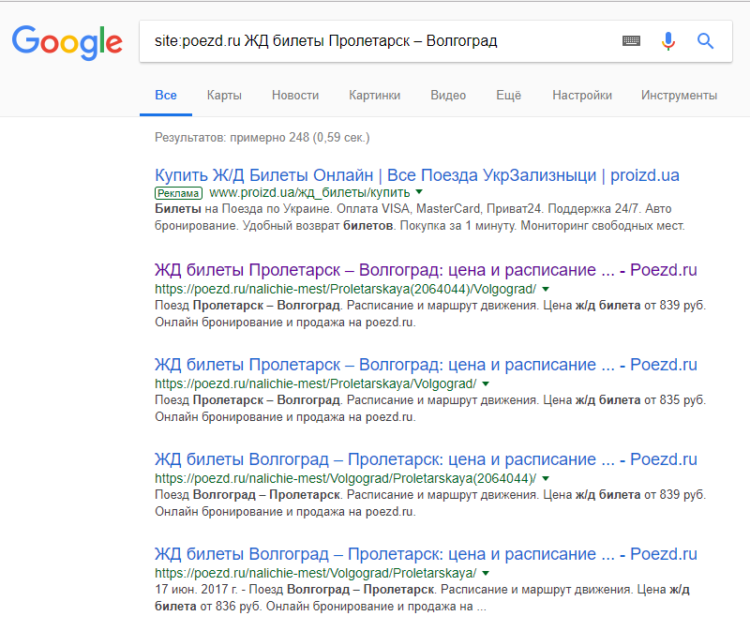 Мониторинг выдачи через «site:» на примере сайта poezd.ru. Перечень полных дублей по фразе «ЖД билеты Пролетарск — Волгоград»
Мониторинг выдачи через «site:» на примере сайта poezd.ru. Перечень полных дублей по фразе «ЖД билеты Пролетарск — Волгоград»
Понять, есть ли полные дубли поможет информация в сниппете: если вы увидели фразу, введенную в строку поиска, жирным шрифтом на 2 и более страницах, то это говорит о наличии дубликатов.
Важно!
Вводимый текст через «site:» не должен быть больше 1 предложения. А искать стоит без точки.
Анализ через Google Search Console
Чтобы проверить дубли страниц на сайте с одинаковыми мета-описаниями, в консоли Google Search Console перейдите на вкладку «Оптимизация Html». В результате вы получите список потенциальных копий.
 Поиск дубликатов в Google Search Console
Поиск дубликатов в Google Search Console
Анализ через Яндекс Вебмастер
В Яндекс Вебмастер повторы страниц проверяют по такому пути: «Индексирование» → «Страницы в поиске» → «Исключенные страницы» → «Дубли».
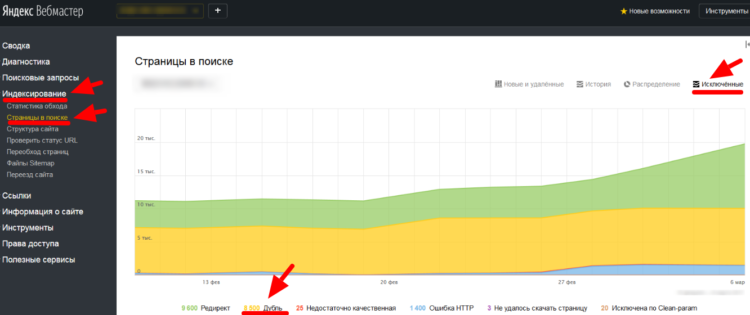 Отслеживание страниц-дубликатов в Яндекс Вебмастере
Отслеживание страниц-дубликатов в Яндекс Вебмастере
Десктопные программы-парсеры
Команда Livepage рекомендует программы:
Screaming Frog Seo Spider
Программа используется для мелких и средних проектов. Эффективно сканирует на наличие полных и фрагментированных дублей страниц, названий, мета-данных, заголовков.
Кроме того, с Seo Spider вы сможете проанализировать правильность составления мета-тегов, найти неработающие ссылки, провести аудит и другое.
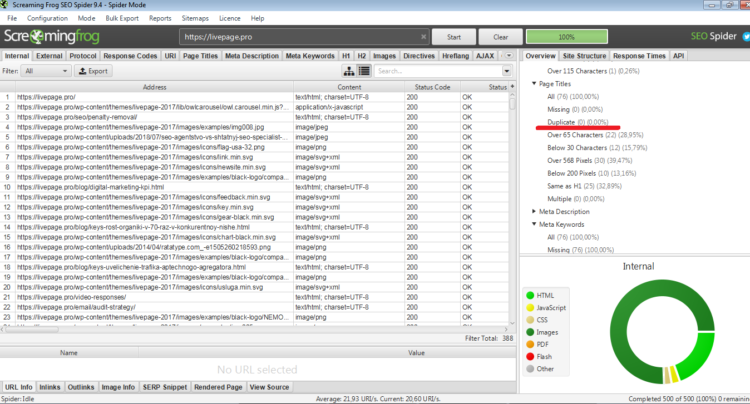 Итог после проверки отображен справа, в каждом пункте раскрываются несколько проблем и их количество
Итог после проверки отображен справа, в каждом пункте раскрываются несколько проблем и их количество
Netpeak Spider
Программа поможет провести полный аудит сайта и выявить проблемы, неточности и ошибки. Всего Netpeak определяет 62 ошибки в 54 параметрах, среди них:
С Xenu Link Sleuth также просто проверить сайт на наличие дублей страниц. Программа выполняет технический аудит сайта и находит полные копии, в том числе и заголовков. Однако частичные дубликаты она не видит.
После установки в строку ввода прописываете адрес сайта, сканируете, сортируете результаты, сравниваете совпадения.
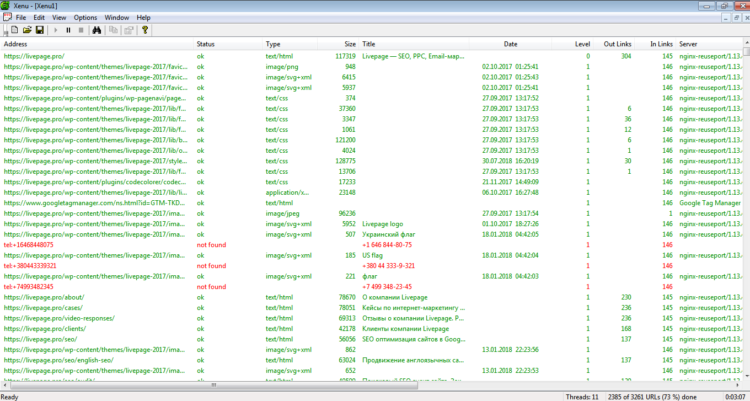 Результаты проверки в Xenu Link Sleuth
Результаты проверки в Xenu Link Sleuth
Онлайн-сервисы для проверки сайта на дубли страниц
Самыми популярными и эффективными являются такие сервисы:
* Цены актуальны на август 2018 года
** Помните, что результаты проверки не являются истиной последней инстанции. Выявленные проблемы — это не 100% проблемы, это лишь показатель того, на что важно обратить внимание, перепроверить и при необходимости исправить!
Serpstat
Платформа проводит технический SEO-аудит сайта, анализируя больше 50 ошибок. Среди всех возможных проблем и потенциально опасных ситуаций сервис выявляет дублированный контент на сайте на двух и больше страницах. Сервис видит:
Seoto.me
Сервис, позволяющий мониторить ошибки на сайте:
Регистрируетесь, добавляете проект и запускаете сканирование. Результат предоставляется в виде таблицы:
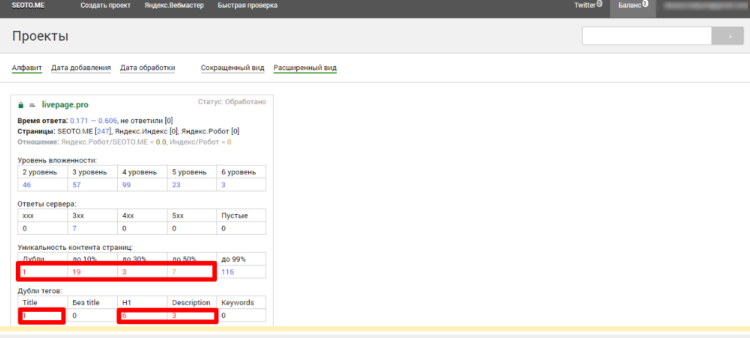 Общий результат проверки в Seoto.me
Общий результат проверки в Seoto.me 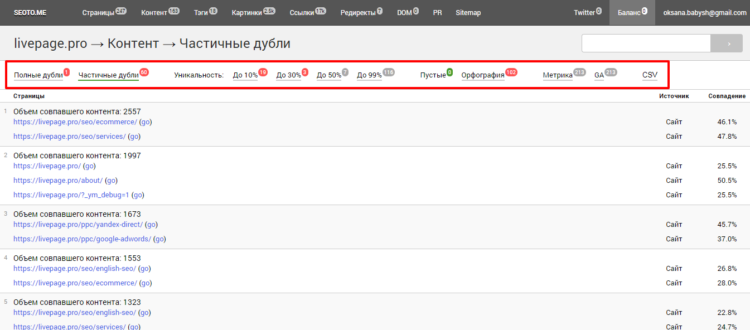 Детализация результатов по всем параметрам
Детализация результатов по всем параметрам
Сервис работает бесплатно для 3-х проектов. Далее плата за проект — 500 рублей.
JetOctopus.com
Онлайн-сервис поможет не только проверить сайт на дубли страниц, но и такие ошибки:
JetOctopus предлагает пробную версию бесплатно, потом можно выбрать подходящий тарифный план — от 20 € в месяц.
Важно! Преимущество сервиса — он может определять смысловые дубликаты. То есть страницы похожие по контенту, но уникально написанные.
Ручной перебор потенциальных страниц дубликатов на сайте
Этот способ актуален для маленького ресурса. Заключается в ручном подборе возможных вариаций URL, в которых могут быть дубли (примеры описывали выше).
Однако метод требует больших затрат времени, к тому же легко что-то пропустить или забыть.
Кроме того, вручную ищут и смысловые дубликаты, а именно синонимические. Важно аналитически подходить к такому редакторскому аудиту сайта: проверяйте статьи на схожесть информации, повторы фраз и абзацев другими словами. Задавайте вопрос, про что статья, и если будут совпадения — удаляйте одну из них.
Как убрать дубли страниц на сайте
Перед удалением дублей важно разобраться в причине их возникновения и устранить ее.
При этом в каждой ситуации необходимо индивидуально подбирать решение об их удалении или оставлении. Однако помните, если дубликаты функционально не оправданы, от них лучше отказаться.


Итак, убрать дубли можно с помощью:
Смысловые дубли можно нейтрализовать несколькими способами:
Закрыть дубли через
Тег meta name = «robots» content = «noindex» / > используется для страниц, которые должны продолжить существовать.
Цель применения — закрыть поисковому роботу доступ к странице. При этом можно:
Как разместить тег
301 редирект
301 редирект — способ перенаправления пользователей с одной страницы на другую, при использовании которого они «склеиваются». При этом ссылочный вес передается со старой страницы на новую.
Настройка 301 редиректов используется, когда нужно убрать дубли страниц на сайте, которые не должны существовать.
Как настроить редирект
Важно!
Если у вас нет опыта в программировании, а в штате нет программиста, воспользуйтесь технической поддержкой хостинг-провайдера. Или же установите плагины для настройки редиректов, например, Safe Redirect Manager, Redirection, Simple 301 Redirects. А, например, CMS Joomla или Wix имеют встроенные инструменты редиректа.
Закрыть дубли через rel = «canonical»
Установка тега rel = «canonical» — работающий вариант для страниц:
Этот способ актуален, если не получается удалить страницы-дубли. Тогда важно указать главную (каноническую) страницу, более предпочтительную для индексации, чтобы боты обращали внимание только на нее.
Атрибут rel = «canonical» применим и для Google, и для Яндекса. Однако эффективнее использовать этот тег для второй поисковой системы.
Как задать атрибут
Например, для страниц:
http://site.com/index.php?catalog=25&tovar=10;
http://site.com/catalog?filtr1=%5b%25D0%,filtr2=%5b%25D0%259 °F%;
http://site.com/catalog/print
— канонической будет страница http://site.com/catalog
Атрибуты rel=»next» и rel=»prev»
С помощью rel=»next» и rel = «prev» связываются отдельные страницы в цепочки. Стоит учитывать, что метод действенен только для страниц пагинации и только для Google. Однако этот тег лишь вспомогательный атрибут, и как правило, не является обязательная директива.
Кроме того, важно отслеживать правильность генерации тегов и отслеживать четкую последовательность между страницами пагинации. Это поможет избежать бесконечных цепочек.
Как настроить атрибут
Размещают атрибут на первой странице в разделе span style = «font-weight: 400;» > head > / span > :
link rel = «prev» href = «http://site.com/catalog-pageN» >
Настройка robots.txt
Закрыть доступ к разделам и страницам можно с помощью файла robots.txt. Однако это не гарантирует избавление от дублей. Поскольку некоторые страницы могли попасть в индекс, и после добавления запрета они остаются доступными для поисковых систем. То есть вы сможете противостоять новым дублям, но через robots.txt не получится удалить старые.
Способ применяется, когда не подходит никакой другой вариант. Подходит для закрытия служебных страниц, частично повторяющих контент основных.
Как настроить
В файле robots.txt прописываете страницы, которые хотите скрыть, а перед ними ставите слеш.
 Визуально настройка robots.txt выглядит так: 1 – закрыта страница входа в личный кабинет, 2 – закрыта страница сравнения товаров
Визуально настройка robots.txt выглядит так: 1 – закрыта страница входа в личный кабинет, 2 – закрыта страница сравнения товаров
Создание сайтов на разных поддоменах
Этот способ поможет в решении проблемы региональных дублей.
Чтобы у поисковиков не было вопросов к вашему ресурсу, продвигайте регионы на разных поддоменах. Для каждой страны лучше иметь национальный домен. Это облегчит продвижение и не повлечет за собой санкций от поисковых систем.
Теги alternate и hreflang
Представленные теги используются, когда:
Они предотвращают склеивание страниц при повторяющемся контенте.
Визуально пример нейтрализации дублей выглядит так:
link rel = «alternate» hreflang = «язык-регион» href = «адрес альтернативной страницы» / >
Применяя описанные методы, найти дубликаты страниц на сайте и избавиться от них для оптимизации ресурса будет проще.
Остались вопросы по вашему сайту? Напишите нам и мы поможем найти все дубликаты и оптимизировать ваш проект.



