Нужны ли графические ядра Nvidia CUDA для игр?

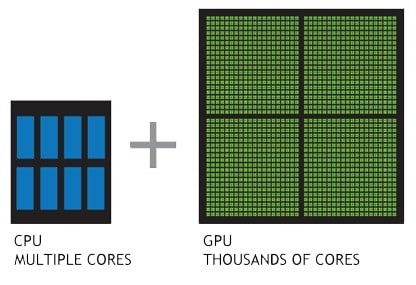
Ядра CUDA являются эквивалентом процессорных ядер Nvidia. Они оптимизированы для одновременного выполнения большого количества вычислений, что очень важно для современной графики. Естественно, на графические настройки больше всего повлияло количество ядер CUDA в видеокарте, и они требуют больше всего от графического процессора, то есть теней и освещения, среди прочего.
CUDA долгое время была одной из самых выдающихся записей в спецификациях любой видеокарты GeForce. Однако не все до конца понимают, что такое ядра CUDA и что конкретно они означают для игр.
В этой статье дан краткий и простой ответ на этот вопрос. Кроме того, мы кратко рассмотрим некоторые другие связанные вопросы, которые могут возникнуть у некоторых пользователей.
Что такое ядра видеокарты CUDA?
CUDA является аббревиатурой от одной из запатентованных технологий Nvidia: Compute Unified Device Architecture. Его цель? Эффективные параллельные вычисления.
Одиночное ядро CUDA аналогично ядру ЦП, основное отличие в том, что оно менее изощренное, но реализовано в большем количестве. Обычный игровой процессор имеет от 2 до 16 ядер, но количество ядер CUDA исчисляется сотнями, даже в самых низких современных видеокартах Nvidia GeForce. Между тем, у высококлассных карт сейчас их тысячи.
Что делают ядра CUDA в играх?
Обработка графики требует одновременного выполнения множества сложных вычислений, поэтому такое огромное количество ядер CUDA реализовано в видеокартах. И учитывая, как графические процессоры разрабатываются и оптимизируются специально для этой цели, их ядра могут быть намного меньше, чем у гораздо более универсального CPU.
И как ядра CUDA влияют на производительность в игре?
По сути, любые графические настройки, которые требуют одновременного выполнения вычислений, значительно выиграют от большего количества ядер CUDA. Наиболее очевидными из них считается освещение и тени, но также включены физика, а также некоторые типы сглаживания и окклюзии окружающей среды.
Ядра CUDA или потоковые процессоры?
Там, где у Nvidia GeForce есть ядра CUDA, у их основного конкурента AMD Radeon есть потоковые процессоры.
Ядра CUDA лучше оптимизированы, поскольку аппаратное обеспечение Nvidia обычно сравнивают с AMD, но нет никаких явных различий в производительности или качестве графики, о которых вам следует беспокоиться, если вы разрываетесь между приобретением Nvidia или AMD GPU.
Сколько ядер CUDA вам нужно?
И вот сложный вопрос. Как часто бывает с бумажными спецификациями, они просто не являются хорошим индикатором того, какую производительность вы можете ожидать от аппаратного обеспечения.
Многие другие спецификации, такие как пропускная способность VRAM, более важны для рассмотрения, чем количество ядер CUDA, а также вопрос оптимизации программного обеспечения.
Для общего представления о том, насколько мощен графический процессор, мы рекомендуем проверить UserBenchmark. Однако, если вы хотите увидеть детальное и всестороннее тестирование, есть несколько надежных сайтов, таких как GamersNexus, TrustedReviews, Tom’s Hardware, AnandTech и ряд других.
Вывод
Надеемся, что это помогло пролить некоторый свет на то, чем на самом деле являются ядра CUDA, что они делают и насколько они важны. Прежде всего, мы надеемся, что помогли развеять любые ваши заблуждения по этому поводу.
CUDA: Как работает GPU
Внутренняя модель nVidia GPU – ключевой момент в понимании GPGPU с использованием CUDA. В этот раз я постараюсь наиболее детально рассказать о программном устройстве GPUs. Я расскажу о ключевых моментах компилятора CUDA, интерфейсе CUDA runtime API, ну, и в заключение, приведу пример использования CUDA для несложных математических вычислений.
Вычислительная модель GPU:
При использовании GPU вы можете задействовать грид необходимого размера и сконфигурировать блоки под нужды вашей задачи.
CUDA и язык C:
Дополнительные типы переменных и их спецификаторы будут рассмотрены непосредственно в примерах работы с памятью.
CUDA host API:
Перед тем, как приступить к непосредственному использованию CUDA для вычислений, необходимо ознакомиться с так называемым CUDA host API, который является связующим звеном между CPU и GPU. CUDA host API в свою очередь можно разделить на низкоуровневое API под названием CUDA driver API, который предоставляет доступ к драйверу пользовательского режима CUDA, и высокоуровневое API – CUDA runtime API. В своих примерах я буду использовать CUDA runtime API.
Понимаем работу GPU:
Как было сказано, нить – непосредственный исполнитель вычислений. Каким же тогда образом происходит распараллеливание вычислений между нитями? Рассмотрим работу отдельно взятого блока.
Задача. Требуется вычислить сумму двух векторов размерностью N элементов.
Нам известна максимальные размеры нашего блока: 512*512*64 нитей. Так как вектор у нас одномерный, то пока ограничимся использованием x-измерения нашего блока, то есть задействуем только одну полосу нитей из блока (рис. 3). 
Рис. 3. Наша полоса нитей из используемого блока.
Заметим, что x-размерность блока 512, то есть, мы можем сложить за один раз векторы, длина которых N // Функция сложения двух векторов
__global__ void addVector( float * left, float * right, float * result)
<
//Получаем id текущей нити.
int idx = threadIdx.x;
Таким образом, распараллеливание будет выполнено автоматически при запуске ядра. В этой функции так же используется встроенная переменная threadIdx и её поле x, которая позволяет задать соответствие между расчетом элемента вектора и нитью в блоке. Делаем расчет каждого элемента вектора в отдельной нити.
Пишем код, которые отвечает за 1 и 2 пункт в программе:
#define SIZE 512
__host__ int main()
<
//Выделяем память под вектора
float * vec1 = new float [SIZE];
float * vec2 = new float [SIZE];
float * vec3 = new float [SIZE];
//Инициализируем значения векторов
for ( int i = 0; i //Указатели на память видеокарте
float * devVec1;
float * devVec2;
float * devVec3;
…
dim3 gridSize = dim3(1, 1, 1); //Размер используемого грида
dim3 blockSize = dim3(SIZE, 1, 1); //Размер используемого блока
Теперь нам остаеться скопировать результат расчета из видеопамяти в память хоста. Но у функций ядра при этом есть особенность – асинхронное исполнение, то есть, если после вызова ядра начал работать следующий участок кода, то это ещё не значит, что GPU выполнил расчеты. Для завершения работы заданной функции ядра необходимо использовать средства синхронизации, например event’ы. Поэтому, перед копированием результатов на хост выполняем синхронизацию нитей GPU через event.
Код после вызова ядра:
//Выполняем вызов функции ядра
addVector >>(devVec1, devVec2, devVec3);
//Хендл event’а
cudaEvent_t syncEvent;
cudaEventCreate(&syncEvent); //Создаем event
cudaEventRecord(syncEvent, 0); //Записываем event
cudaEventSynchronize(syncEvent); //Синхронизируем event
Рассмотрим более подробно функции из Event Managment API.
Рис. 4. Синхронизация работы основоной и GPU прграмм.
На рисунке 4 блок «Ожидание прохождения Event’а» и есть вызов функции cudaEventSynchronize.
Ну и в заключении выводим результат на экран и чистим выделенные ресурсы.
cudaFree(devVec1);
cudaFree(devVec2);
cudaFree(devVec3);
Думаю, что описывать функции высвобождения ресурсов нет необходимости. Разве что, можно напомнить, что они так же возвращают значения cudaError_t, если есть необходимость проверки их работы.
Заключение
Надеюсь, что этот материал поможет вам понять, как функционирует GPU. Я описал самые главные моменты, которые необходимо знать для работы с CUDA. Попробуйте сами написать сложение двух матриц, но не забывайте об аппаратных ограничениях видеокарты.
Что такое CUDA ядра в видеокарте
Уже долгое время технология CUDA является одной из главных особенностей видеокарт GeForce. Однако не все понимают, что это за технология и как она влияет на игры.
В этой статье расскажу и дам короткое объяснение. Так же рассмотрим и другие вопросы, которые могут возникнуть у пользователей.
Обработка графики требует одновременного выполнения сложных вычислений, именно одновременного. Поэтому в видеокартах и реализовано такое огромное количество ядер CUDA. Учитывая факт оптимизации видеокарт специально для работы с графикой, их ядра намного меньше и проще, чем у более универсальных ядер центрального процессора.


Обе технологии являются собственной разработкой компаний и в них есть различия, однако для обычного пользователя большой разницы между ними нет.
Это достаточно сложный вопрос, ответ на который не стоит искать в сухих цифрах характеристик графического адаптера. Количество не даст никаких представлений о производительности.
Многие другие характеристики, например, объем видеопамяти, поколение и скорости шины видеокарты намного важнее, для пользователя, чем данные о ядрах CUDA. Так же не стоит забывать об оптимизации в самих играх.
Лучшим способом выбора графического адаптера является все таки просмотр тестов производительности, просмотр отзывов людей, которые уже пользуются конкретной видеокартой, анализ рынка в целом, чтобы понять что выбирают покупатели. И конечно подбор по системным требованиям и fps под конкретную игру, в которую вы хотите зарубиться
Надеюсь, что помог ответить на вопрос о назначении ядер CUDA и развеять все сомнения и заблуждения о данной технологии. Теперь вы знаете что они делают и насколько важны.
CUDA: аспекты производительности при решении типичных задач
 Перед тем как начать переносить реализацию вычислительного алгоритма на видеокарту стоит задуматься — получим ли мы желаемый прирост производительности или только потеряем время. И несмотря на обещания производителей о сотнях GFLOPS, у современного поколения карт есть свои проблемы, о которых лучше знать заранее. Я не буду глубоко уходить в теорию и рассмотрю несколько существенных практических моментов и сформулирую некоторые полезные выводы.
Перед тем как начать переносить реализацию вычислительного алгоритма на видеокарту стоит задуматься — получим ли мы желаемый прирост производительности или только потеряем время. И несмотря на обещания производителей о сотнях GFLOPS, у современного поколения карт есть свои проблемы, о которых лучше знать заранее. Я не буду глубоко уходить в теорию и рассмотрю несколько существенных практических моментов и сформулирую некоторые полезные выводы.
Будем считать, что вы примерно разобрались, как работает CUDA и уже скачали стабильную версию CUDA Toolkit.
Я буду мучить теперь уже middle-end видеокарту GTX460 на Core Duo E8400.
Вызов функции
Да, если мы что-то хотим посчитать, то без вызова функции, выполняемой на карточке никак не обойтись. Для этого напишем простейшую тестовую функцию:
__global__ void stubCUDA( unsigned short * output)
<
// the most valid function: yep, does nothing.
>
cudaThreadSynchronize();
stubCUDA >>(0);
cudaThreadSynchronize();
Все вызовы функций по умолчанию асинхронны, поэтому вызовы cudaThreadSynchronize() необходимы для ожидания завершения вызванной функции.
Попробуем прогнать такой блок в цикле: получаем порядка 15000 вызовов в секунду для GRID=160, THREADS=96.
Скажем так, совсем не густо. Даже самая простейшая функция, которая ничего не делает, не может выполниться быстрее чем за 0.7 мс.
Первое предположение заключается в том, что бОльшая часть времени уходит на синхронизацию потоков и асинхронные вызовы отрабатывали бы значительно быстрее (хотя и применять их в конкретных задачах более специфично).
Проверим. Без синхронизации удалось запустить функцию 73100 раз в секунду. Результат, надо заметить, нисколько не впечатляющий.
И последний тест, запустим функцию с GRID=THREADS=1, казалось бы, это должно устранить накладные расходы на создание кучи потоков внутри карточки. Но это не так, получаем те же 73000-73500 вызовов в секунду.
Доступ к памяти извне
cudaMemcpy(data_cuda, image, data_cuda_size, cudaMemcpyHostToDevice);
Да, CUDA предлагает нам и средства асинхронной передачи данных, но их производительность, забегая вперед, не отличается от синхронной функции.
Копируем большие блоки: как и в сторону cudaMemcpyHostToDevice, так и cudaMemcpyDeviceToHost получаем производительность порядка 2 Гбайт/c на больших блоках (более 100 мегабайт). В целом это очень даже неплохо.
Значительно хуже обстоят дела с совсем небольшими структурами. Передавая по 4 байта мы получаем не более 22000 вызовов в секунду, т.е. 88 кбайт/c.
Доступ к памяти изнутри
__global__ void accessTestCUDA(unsigned short * output, unsigned short * data, int blockcount, int blocksize)
<
// just for test of max access speed: does nothing useful
unsigned short temp;
for ( int i = blockIdx.x; i int vectorBase = i * blocksize;
int vectorEnd = vectorBase + blocksize;
for ( int j = vectorBase + threadIdx.x; j
Здесь уже используются параметры GRID и THREADS, пока не буду объяснять зачем, но поверьте — все как следует. Придирчивые скажут, что результат пишется неправильно из-за отсутствия синхронизации, но нам-то он и не нужен.
Итак, получаем порядка 42 Гбайт/c для произвольного чтения. Вот это совсем неплохо.
Теперь модифицируем функцию, чтобы она копировала входные данные на выход. Бессмысленно, но позволяет оценить скорость записи в видеопамять (поскольку изменение совсем несложное, я не буду дублировать код).
Получаем порядка 30 Гбайт/с на ввод-вывод. Тоже неплохо.
Следует сделать поправку на то, что фактически мы использовали последовательный (с некоторыми отступлениями) доступ к памяти. Для произвольного цифры могут ухудшится до двух раз — но ведь и это не проблема?
Арифметические операции
__global__ void normalizeCUDA(unsigned short * data, int blockcount, int blocksize, float sub, float factor)
<
for ( int i = blockIdx.x; i int vectorBase = i * blocksize;
int vectorEnd = vectorBase + blocksize;
Здесь используется аж три казалось бы затратных вычислительных процедуры: приведение к вещественным числам, ADDMUL и приведение к целым. На форумах пугают, что приведение целые-вещественные работает из рук вон плохо. Может быть это было верно для старых поколений карточек, но сейчас это не так.
Итоговая скорость обработки: 26 Гбайт/c. Три операции ухудшили производительность относительно прямого ввода-вывода всего на 13%.
Если внимательно посмотреть код, то нормализует он не совсем верно. Перед записью в целые числа, вещественное необходимо округлить, например функцией round(). Но не делайте так, и постарайтесь ее никогда не использовать!
round(d): 20 Гбайт/c, еще минус 23%.
(unsigned short)(d + 0.5): 26 Гбайт/с, собственно время в пределах погрешности измерений даже не поменялось.
Логические операции
__global__ void getMinMaxCUDA(unsigned short * output, unsigned short * data, int blockcount, int blocksize)
<
__shared__ unsigned short sMins[MAX_THREADS];
__shared__ unsigned short sMaxs[MAX_THREADS];
sMins[threadIdx.x] = data[0];
sMaxs[threadIdx.x] = data[0];
for ( int i = blockIdx.x; i int vectorBase = i * blocksize;
int vectorEnd = vectorBase + blocksize;
for ( int j = vectorBase + threadIdx.x; j short d = data[j];
if (d if (d > sMaxs[threadIdx.x])
sMaxs[threadIdx.x] = d;
>
>
if (threadIdx.x == 0)
<
register unsigned short min = sMins[0];
for ( int j = 1; j if (sMins[j] if (min if (threadIdx.x == 1)
<
register unsigned short max = sMaxs[0];
for ( int j = 1; j if (sMaxs[j] > max)
max = sMaxs[j];
if (max > output[1])
output[1] = max;
>
Здесь уже не обойтись без синхронизации потоков и shared memory.
Итоговая скорость: 29 Гбайт/c, даже быстрее нормализации.
Почему я объединил код минимума и максимума — обычно нужны оба, а вызовы по отдельности теряют время (см. первый абзац).
В общем, киньте камнем в того, кто сказал что на видеокартах плохо с условным операциями: искусственно удалось замедлить этот фрагмент практически в 2 раза, но для этого потребовалось увеличить глубину условий аж до 4! if () if () if () if () else if ()…
Сложные структуры данных
Руководствуясь идеей о том что алгоритмы и структуры данных сильно связаны (хотя бы вспомнить Н. Вирта), следует проверить как же обстоят дела с некоторыми сложными структурами данных.
Вот тут возникает проблема, при передаче данных в функции мы можем использовать только два вида объектов — константные интегральные типы (чиселки) и ссылки на блоки видеопамяти.
Расплата за подобные ухищрения — необходимость применения двойной индексации:
for ( int j = vectorBase + threadIdx.x; j
Данный фрагмент работает со скоростью от 10 до 30 Гбайт/c в зависимости от наполнения и размеров индекса и данных. Использование памяти можно пытаться соптимизировать но даже в лучшем случае мы теряем 25% скорости доступа. Тройные индексы ведут себя еще хуже, теряя 40%-60% производительности.
Сегодня мы многое поняли
При грамотном использовании возможностей видеокарты можно получить небывалую производительность в задачах, скажем обработки изображений, звука, видео — везде где есть большие объемы данных, необходимость хитрой арифметики и отсутствие сложных структур данных.
Если топик вам понравится, то расскажу про то как обсчитывать на видеокарте несколько полезных объектов: Distance Map, морфологию изображений и поисковые индексы и покажу несколько интересных структур данных, которые работают достаточно быстро и не создают лишних проблем с синхронизацией.
Что такое ядра CUDA и как они улучшают компьютерные игры?
Когда вы выбираете новый графический процессор, вы, вероятно, встретите нечто, называемое «ядрами CUDA», в списке спецификаций графического процессора. Вы услышите, как люди в восторге от этих загадочных ядер, но вы до сих пор не представляете, как они улучшают GPU. Для вас они просто то, что заставляет вас думать о морском существе.
Это все изменится. Мы расскажем вам об основах ядер CvA от Nvidia и о том, как они помогают вашему ПК лучше воспроизводить графику.
Что такое ядра CUDA?
 Изображение предоставлено: kampfbox / Pixabay
Изображение предоставлено: kampfbox / Pixabay
Ядра CUDA звучат круто, но они, к сожалению, не имеют ничего общего с барракудой. CUDA расшифровывается как «Compute Unified Device Architecture», которая мало что объясняет, что конкретно делают ядра CUDA. Эти высокотехнологичные ядра фактически специализируются на параллельной обработке. Другими словами, они способны работать вместе, чтобы выполнить задачу.
Вы знакомы с тем, как работают процессоры?
Что такое процессор и что он делает?
Что такое процессор и что он делает?
Вычислительные сокращения сбивают с толку. Что такое процессор в любом случае? И нужен ли мне четырехъядерный или двухъядерный процессор? Как насчет AMD или Intel? Мы здесь, чтобы помочь объяснить разницу!
Прочитайте больше
? Вы, наверное, знаете, что процессоры поставляются с ядрами. Некоторые имеют двухъядерные, четырехъядерные или даже поставляются с восемью ядрами. Все эти ядра помогают процессору обрабатывать данные — чем больше ядер, тем быстрее процессорные процессы.
Ядра CUDA работают так же, как и ядра ЦП (за исключением того, что они находятся внутри графических процессоров). Хотя вы обычно можете подсчитать количество ядер ЦП на обеих руках, количество ядер CUDA в графическом процессоре может исчисляться сотнями или тысячами. Как правило, вы не увидите GPU только с одним ядром CUDA — у GPU обычно их сотни и более.
Поскольку ядра CUDA намного меньше, чем ядра ЦП, вы можете разместить больше из них внутри графического процессора. Кроме того, графические карты, как правило, имеют большую площадь по сравнению с процессорами, что делает их достаточно просторными для размещения тысяч ядер CUDA.
Почему CUDA Core имеет значение в играх?
Теперь, когда вы знаете, что такое ядра CUDA и как они возникли, вы, вероятно, задаетесь вопросом, как все эти крошечные ядра могут улучшить ваши игровые возможности. Ядра CUDA позволяют вашему графическому процессору обрабатывать подобные задачи одновременно.
Эффективность ядер CUDA проистекает из этой функции параллельной обработки. Поскольку одно ядро работает для выполнения одной задачи, связанной с графикой, другое ядро рядом с ним выполнит аналогичную работу. Это исключает потерю времени, которое происходит, когда одно ядро ждет, пока другое выполнит свою задачу, прежде чем двигаться дальше.
Ядра CUDA только выполняют задачи, связанные с графикой, и именно здесь ядра CUDA выделяются из ядер ЦП. В то время как ядра ЦП работают для выполнения различных несвязанных задач, ядрам CUDA приходится беспокоиться только о графике.
Что касается вашего игрового опыта, ядра CUDA помогают сделать вашу игру реалистичной, предоставляя графику с высоким разрешением, которая создает реалистичный 3D-эффект. Вы также заметите, что ваши игры выглядят более детально и имеют улучшенное освещение и затенение.
Когда вы сталкиваетесь с экраном загрузки во время игр, знайте, что ядра CUDA работают за кулисами. Ядра CUDA создают пейзажи, рисуют модели персонажей и настраивают освещение, прежде чем отправиться в виртуальное приключение.
В чем разница между ядрами CUDA и потоковыми процессорами?
Если вы поклонник AMD, то, вероятно, вы знаете о потоковых процессорах AMD. Большинство людей знают потоковые процессоры как версию ядер CUDA от AMD, что по большей части верно.
Потоковые процессоры имеют то же назначение, что и ядра CUDA, но оба ядра работают по-разному. Ядра CUDA и потоковые процессоры определенно не равны друг другу — 100 ядер CUDA не эквивалентны 100 потоковым процессорам.
Итак, что же отличает потоковые процессоры от ядер CUDA? В основном это связано с тем, как построен графический процессор. Структура графических процессоров AMD и Nvidia сильно различается, и это приводит к тому, что ядра работают по-разному.
Сколько ядер CUDA вам действительно нужно?
Чем больше у вас ядер CUDA, тем лучше будет ваш игровой опыт. Однако, если вы ищете доступную видеокарту
6 лучших бюджетных видеокарт для дешевых игр
6 лучших бюджетных видеокарт для дешевых игр
Бюджетные видеокарты очень способны в наши дни. Вот лучшие бюджетные видеокарты, которые позволят вам играть по дешевке.
Прочитайте больше
Возможно, вы не захотите получить одно с большим количеством ядер CUDA (они могут быть довольно дорогими).
Ядра CUDA не просто популярны среди геймеров. Они имеют несколько различных применений в областях, которые имеют дело с огромным количеством данных, таких как инжиниринг и майнинг биткойнов. Вам понадобится большое количество ядер CUDA в этих областях, но сколько вам нужно, чтобы просто играть в компьютерную игру?
Ответ на самом деле зависит от того, сколько денег в вашем кошельке и насколько хорошо вы хотите свою видеокарту. При этом видеокарта с большим количеством ядер CUDA не обязательно означает, что она лучше, чем карта с меньшим числом. Качество видеокарты действительно зависит от того, как другие ее функции взаимодействуют с ядрами CUDA.
Чтобы получить точное сравнение между двумя картами, вы должны взглянуть на тесты производительности
10 лучших бесплатных тестовых программ для Windows
10 лучших бесплатных тестовых программ для Windows
Используйте это фантастическое и бесплатное тестовое программное обеспечение для Windows, чтобы устранить неполадки в вашей системе и поддерживать ее в актуальном состоянии.
Прочитайте больше
,
Заменят ли когда-нибудь графические процессоры?
Разработка ядер CUDA заставляет задуматься о том, может ли графический процессор полностью заменить процессор. Ядра CUDA способны вместить тысячи ядер, но достаточно ли этого для замены?
С начала 2000-х годов Nvidia работает над созданием графического процессора для общих вычислений. В 2003 году исследователи из Стэнфордского университета создали модель программирования под названием Brook, которая позволит Nvidia еще на шаг приблизиться к созданию универсального графического процессора. В то время некоторые люди думали, что внедрение Brook положит конец процессорам (как вы можете видеть, этого еще не произошло).
Лидер исследовательской группы, Ян Бак, в конце концов присоединился к Nvidia, начав рассказ о ядре CUDA. Nvidia выпустила CUDA в 2006 году, и с тех пор она доминирует в сфере глубокого обучения
Глубокое обучение против машинного обучения против искусственного интеллекта: как они идут вместе?
Глубокое обучение против машинного обучения против искусственного интеллекта: как они идут вместе?
Пытаетесь понять разницу между искусственным интеллектом, машинным обучением и глубоким обучением? Вот что они все значат.
Прочитайте больше
отрасли, обработка изображений, вычислительная наука и многое другое. Даже с развитием ядер CUDA маловероятно, что графические процессоры заменят процессоры.
Обновление вашей видеокарты
Использование видеокарты, оснащенной ядрами CUDA, даст вашему ПК преимущество в общей производительности, а также в играх. Больше ядер CUDA означает более четкую и реалистичную графику. Только не забудьте учесть и другие особенности видеокарты.
Если все элементы работают вместе для достижения наилучшей производительности, вы будете знать, что сделали правильный выбор.
Не знаете, с чего начать поиск следующей видеокарты? Наше руководство по покупке видеокарт
Лучшие видеокарты для любого бюджета
Лучшие видеокарты для любого бюджета
Найти высокопроизводительный бюджетный графический процессор может быть непросто. Мы собрали лучшие видеокарты для любого бюджета.
Прочитайте больше
поможет вам сделать осознанную покупку, которая соответствует вашему бюджету.
Как пиратская игра престолов и другие шоу могут принести вам вредоносное ПО



