Кластерный подход в розничной торговле
Или искусство найти «хвост», на который можно сесть
Концептуальная заметка
Кластер – это группа географически соседствующих взаимосвязанных компаний, действующих в определенной сфере и взаимодополняющих друг друга
Жизнь уплотняется. Болезнь под названием «Некогда!» становится хронической. И все, что позволяет сэкономить нам время — особо привлекательно. Если это торговые операторы на рынке, то они становятся носителями важного конкурентного преимущества. Понимая это или действуя интуитивно, они соединяются в подобия кластеров. Таким образом, логичен успех супермаркетов, где в одном строении собраны товары и услуги самых разных назначений – и продукты питания, и одежда, и лекарства, и бытовая химия, и химчистка, и пункт приема оплаты чего угодно…
Но мы сейчас не о крупных торговых операторах. Им кластеризация не нужна. Как видно из определения кластера, данного Портером, там должен быть принцип взаимодополнения. Чем должен дополниться магазин, в котором все есть?
Речь наша пойдет о небольших торговых предприятиях – салонах красоты, магазинах, кафе и ресторанах, пунктах бытовых услуг и т. д.
Думаю, кластер – прекрасный способ выживания малых предприятий и в условиях кризиса, и в условиях конкуренции с гигантами.
Перед тем, как перейти к основному содержанию заметки, коротко остановимся на трех самых важных для торговли признаках кластера, выведенных М. Портером.
Во-вторых, это действия в определенной сфере. Под этим будем понимать направленность интересов клиентского трафика на соответствие одной из его жизненных «озабоченностей», как например:
В-третьих, это принцип взаимодополнения. Именно он и экономит время клиента, позволяя собрать в одном месте максимальное количество операторов, удовлетворяющих спрос представителя одной из жизненных ролей, примеры которых приведены выше.
Если понять все возможности кластера и начать его осознанно формировать, то, как и в любом осознанном действии, надо начать с целеполагания. Думаю, достойной целью в нашем случае может быть обеспечение высоких темпов развития предприятий, образующих кластер, за счет повышения их конкурентоспособности.
Если быть конкретной, то приведу те основные выгоды, из которых складывается эта самая конкурентоспособность:
Справедливости ради надо привести и возможные риски участия в кластере:
Структура кластера обычно такова: один специализированный якорный участник, который и генерит трафик клиентов конкретной жизненной роли (за счет своей специализированности). Остальные – садятся ему «на хвост». Например, в непосредственной близости с большим магазином «Ткани» на Ленинском проспекте в Москве в свое время в 2005 году я насчитала 12 торговых палаток, торгующих фурнитурой, шерстью для вязания, а также товарами для рукоделия.
Даже если якорный участник и некоммерческое предприятие, ничего не меняется. На «хвост» ЗАГСа могут «сесть»: ювелирные салоны, рестораны и кафе, цветочные салоны и флористические мастерские, ателье, магазины косметики и парфюмерии, салоны красоты и свадебных платьев, СПА, магазины подарков, пункты проката лимузинов…
В качестве примеров
Возможные участники кластеров:
для владельцев домашних питомцев:
для озабоченных своим автомобилем:
Думаю, что кластер совершенно логично рассматривать как форму кросс-промоушн. И тогда принципы выбора соседей будут те же, что в партнерском продвижении:
В качестве заключения
И даже если вы не планируете участвовать ни в каком трафикоообразующем соседстве с другими торговыми предприятиями шаговой доступности, не забудьте посмотреть на соседей, чтоб не получилось как здесь:
Что такое кластеризация или кластерный анализ
Примеры кластеризации в маркетинге.
Если у вас есть большой массив данных, то наиболее эффективный способ понять, что с ними делать — рассортировать их в группы для первичного анализа. Группировать можно при помощи — сегментации (вы сами задаете критерии, например, возрастные и ценовые группы) или кластеризации (математический алгоритм сам выявляет “связующий” критерий или признак, который объединяет данные). Ценность data-driven подхода и основное отличие кластеризации заключается в том, что алгоритмы выявляют и объединяют параметры с похожими чертами из первичного массива данных.
Маркетинг и продажи — одно из направлений применения кластерного анализа. В частности для прогнозирования будущего поведения покупателя — персонализации и таргетирования. Кластерный анализ использует математические модели для обнаружения групп схожих клиентов, основываясь на наименьших различиях среди покупателей в каждой группе.
Кластерный анализ (англ. cluster analysis) — многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы.
Боль: кампании, как маркетинговая инвестиция, должны быть направлены на конкретную целевую группу.
Стандартный пул данных в датасете:
Более глубокое понимание клиентских сегментов достигается путем разработки 3D-модели кластеров на основе ключевых бизнес-показателей, таких как размещенные заказы (покупки), частота заказов, заказанные товары или изменение цен. Актуальность результатов кластеризации для бизнеса позволяет лицам, принимающим решения, выявлять проблемные кластеры, которые вынуждают продавца использовать больше ресурсов для достижения целевого результата. Затем можно сосредоточить свои маркетинговые и операционные усилия на правильных кластерах, чтобы обеспечить оптимальное использование ресурсов, включая:
Хотя возможности прогнозирования, предлагаемые кластеризацией, могут трансформировать результаты целевого маркетинга, кластеризация наиболее эффективна при использовании вместе с другими решениями для розничной аналитики. Ценность кластеризации продуктов особенно видна в очень разреженном датасете (наборе данных). В дополнение к повышению рентабельности маркетинговых инвестиций (ROMI) с точки зрения прибыльности клиентов, кластеризация продуктов может помочь ритейлерам таргетировать и активизировать клиентов из категории с невысокой платежеспособностью.
Подробнее о функционале модуля “Кластеризация” смотрите в обучающем видео.
Кластеризация: расскажи мне, что ты покупаешь, и я скажу кто ты
Задача Datawiz.io: провести кластеризацию клиентов программы лояльности в ритейле.
Кластеризация — это метод поиска закономерностей, предназначенный для разбиения совокупности объектов на однородные группы (кластеры) или поиска существующих структур в данных.
Целью кластеризации является получение новых знаний. Это как “найти клад в собственном подвале”.
Для чего это нужно компаниям? Чтобы лучше узнать своих клиентов. Чтобы найти индивидуальный подход к каждому клиенту, а не работать со всеми одинаково.
Несмотря на то, что многие компании используют программы лояльности и обладают колоссальными данными, их аналитики сначала определяют персону покупателя, а уже потом анализируют ее поведение.
Решение: Machine Learning позволяет пойти от обратного, от личных предпочтений — к персоне. Мы в Datawiz.io используем кластеризацию как метод группирования клиентов по данным о их поведении – покупках, банковских транзакциях, кредитных историях.
Для кластеризации массива данных (чеки, данные по программах лояльности) мы используем алгоритм K-means. Он хорошо масштабируется и оптимизируется под Hadoop.
Также как альтернативу можно использовать алгоритм Affinity Propagation. Конечно, у него есть ряд существенных минусов: он медленный и плохо масштабируется. Но в частных случаях, при желании и наличии свободного времени, можно использовать его для кластеризации на коротких промежутках времени.
1. Clean Datа.
Прежде, чем формировать матрицу — в обязательном порядке чистим информацию. Убираем то, что не влияет на поведение покупателей и является информационным шумом. Для ритейлеров, например, можно исключить рекламную продукцию, выданные дисконтные карты, скретч-карты, тару и пакеты, покупаемые на кассе. После того как данные очищены приступаем к формированию матрицы.
2. Формируем матрицу с входными данными.
Важно: Результаты кластеризации очень зависят от периода времени, по которому она проводится. Если выберем кроткий период — увидим текущие тренды.
Например, проведя кластеризацию перед Новым годом, увидим кластеры, которые не видны на длительном промежутке времени. (Скажем, кластер “Любители “Оливье” и “Селедки под шубой”). Кластеризация за длительный период позволит увидеть картину в целом, то есть клиентов со стабильным поведением (“лайфстайл”). “Студенты”, “Домохозяйки”, “Пенсионеры” и т.д.
Например, ритейлер хочет провести кластеризацию по программе лояльности за полгода.
У магазина есть чеки Васи, который за полгода купил 1 хлеб, 2 молока и 1 батон; и чеки Оли — она купила 3 хлеба, 5 молока и 2 батона за полгода и т.д.
Значит матрица для этого ритейлера будет выглядеть так: 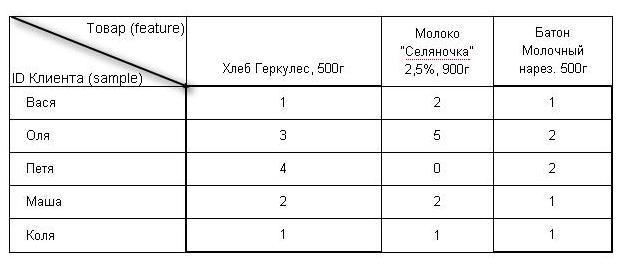
Для ритейлера в среднем, features = 15 тыс. SKU, а samples = 60 тыс. клиентов.
Возьмем каждого отдельно клиента, например Васю со всеми его чеками за полгода. В зависимости от количества вхождений всех товаров по всех его чеках, разместим Васю (и других) на графике, где:
количество осей = количеству товаров (features),
количество точек = количеству клиентов (samples), участвующих в программе лояльности.
Наглядное (и очень схематичное:) изображение: 
Но выглядеть результат кластеризации алгоритмом k-means будет так: 
Также можно проводить кластеризацию по разных уровнях категоризации товаров (feature reduction), тогда матрица будет выглядеть так: 
После того, как матрица сформирована, можно переходить к выбору количества кластеров.
3. Выбираем оптимальное количество кластеров.
Количество кластеров мы выбираем экспериментальным путем, исходя из собственного опыта. Малое количество кластеров будет малоэффективно и не информативно, потому что в таком случае мы получаем один-два “мегакластера”, куда будет входить 98% клиентов и несколько бесполезных маленьких кластеров.
При большом количестве кластеров получится слишком много маленьких групп. К тому же никто не хочет анализировать 5000 отдельных мелких кластеров. Для каждого отдельного случая должен быть свой индивидуальный подход.
Для длительных периодов и большого количества кластеров используем K-means.
4. Проводим кластеризацию.
Выбираем алгоритм K-means (или Affinity Propagation), используем Python библиотеку scikit-learn, на вход даем получившуюся матрицу, запускаем кластеризацию.
5. Анализируем результаты кластеризации.
Результатом работы алгоритма является маркировка всех клиентов программы лояльности, в зависимости от их поведения/покупки. Клиенты с одинаковыми поведенческими характеристиками попадают в один кластер.
Если вы проводите кластеризацию за весь период работы, то в ней участвуют все клиенты программы лояльности. Если за определенный период (год, месяц), то в кластеризации участвуют только те клиенты, которые совершили покупки в заданный период.
Итак, мы провели кластеризацию по программе лояльности для ритейлера за полгода, с количеством кластеров 75. Рассмотрим, как распределились по кластерам покупатели, и какие товары предпочитают в тех или иных кластерах: 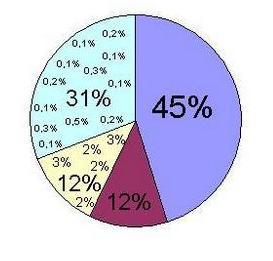
— В “Кластер 1” попало 45% клиентов за этот период. Лидерами продаж по товарам здесь стали: масло, бананы, яйца, молоко, батон, сметана.
— В “Кластере 2” оказалось 12% клиентов. Здесь популярнее остальных уже несколько видов хлеба и сметаны, бананы и непродовольственные товары.
— Пять последующих кластеров уже не такие большие, в каждый из них входят лишь по 2-3% клиентов. (В общей сложности в эти кластеры попали 12% клиентов за выбранный период). Здесь предпочтения клиентов весьма интересны, например: молочные продукты+фрукты, печенье+йогурты\сырки, йогурты\десерты+хлопья, курица+пиво+корм для кошек.
— Оставшиеся 31% покупателей рассеяны по 68 кластерам. в которые входят 0,1-2% клиентов. Также кластер может быть очень маленьким и состоять из 1-2 человек. Чем может быть интересен такой кластер? Читайте в кейсах в конце статьи.
При кластеризации алгоритм выявляет нестандартное поведение клиента. Выявить такое поведение поможет анализ отдельных “фич”(характеристик и особенностей) каждого отдельного кластера.
6. Анализируем характеристики каждого кластера.
7. Проводим персонализированную рассылку по каждому кластеру.
Используя кластеризацию клиентов, можно получить четкую систему рекомендаций для персонала — какой товар, какому клиенту и в какое время предлагать.
Зная, что и какой группе людей предлагать, компании смогут избежать метода “ковровой бомбардировки” при sms или e-mail рассылке. Предлагая клиентам только нужные им товары (не забывая про сопутствующие), можно добиться гораздо большего отклика и конверсии в покупку.
Рассмотрим несколько кейсов от Datawiz.io.
Повышение эффективности промо-рассылок с помощью кластеризации.
В результате кластеризации клиентов одной из сети магазинов мы получили 75 кластеров. Для примера рассмотрим три из них: “молодая семья”, “студент” и “пенсионер”.
— Клиенты кластера “молодая семья” были наиболее восприимчивы к предложениям по покупке подгузников, детского питания, фруктов и молока;
— “студентам” предложили скидки на продукты группы фастфуд и пиво;
— а “пенсионерам” на крупы и овощи.
В следствии такой рассылки конверсия в покупку увеличилась на 14,5 %.
Продвижение нового продукта.
Вариант 1. Чтобы узнать кому будет интересен новый продукт, мы сделали рассылку по всех клиентах программы лояльности. По результатах отклика узнали персону покупателя, которой необходимо маркетировать новый продукт. Далее, отследили нужных нам покупателей в кластерах. Провели рассылку уже только по интересующих нас кластерах.
Вариант 2. Компания не захотела проводить рассылку по всех клиентах, так как база весьма обширна. Поэтому мы создали гипотезу, каким кластерам клиентов этот продукт интересен. Из всех интересующих нас кластеров мы взяли рандомно по 1% клиентов и провели по ним тестовую рассылку. С теми кластерами, которые показали наивысшую конверсию в покупку после тестовой рассылки, и работали в дальнейшем, предлагая новый продукт всему кластеру.
Нестандартное поведение клиента.
Мы провели кластеризацию для магазина одной из сети. Алгоритм выдал кластер, в котором было всего 2 клиента. Но внимание привлекла сумма оборота по этому кластеру за небольшой период. Казалось бы, ну покупают люди много разнообразных продуктов и товаров.
Еще одной интересной деталью было то, что много чеков проводились с разницей в несколько минут. Когда же отследили этих клиентов в базе программы лояльности, оказалось, что владельцами двух дисконтных карт были сотрудники магазина.
Вопрос: может сотрудники таким образом склоняли клиентов к покупке? или зарабатывали себе дисконтные баллы? или продавали товар по полной стоимости, а разницу присваивали, то есть, мошенничали?
Кластерные системы

Parking.ru как облачный провайдер имеет опыт оказания не только услуг с «обычной» надежностью, но и услуг хостинга высокой доступности, построенных на кластеризованной дублированной инфраструктуре.
Имея весомый опыт в построении таких инфраструктурных проектов, мы решили предложить его не только избранным клиентам (которые уже много лет используют эти услуги), а сделать стандартизированное предложение для всех желающих.
Parking.ru запустил целый ряд кластерных решений построенных на надежной дублированной инфраструктуре и имеющих в основе самые разные решения: от виртуальных машин до группы физических серверов. Отдельного внимания заслуживает предложение по ГЕО кластеризации в двух разных ЦОД, объединенных дублированными каналами связи.
Если рассматривать вкратце, то в рамках предложения существуют следующие типовые схемы кластеров:
Кластеры высокой доступности (High Availability cluster)
Создаются для обеспечения высокой доступности сервиса, предоставляемого кластером. Избыточное число узлов, входящих в кластер, гарантирует предоставление сервиса в случае отказа одного или нескольких серверов. Минимальное количество узлов — два, но может быть и больше.
Обычно High Availability кластер строится для Microsoft SQL server’ов, который поддерживает базы данных интернет проектов. High Availability кластер возможно построить и для Exchange систем.
Существует ещё одна разновидность High Availability SQL кластера — «зеркалирование БД» или database mirroring. Этот вид кластера не требует выделенного дискового хранилища, но для автоматического переключения в случае аварии нужен ещё один SQL сервер — следящий/witness. Такой кластер идеально подходит для WEB приложений и требует меньше затрат на создание.
Балансировка нагрузки (Network Load Balancing, NLB)
Принцип действия NLB-кластеров — распределение приходящих запросов на несколько физических или виртуальных узлов серверов. Первоначальная цель такого кластера — производительность, однако, они используются также для повышения надёжности, поскольку выход из строя одного узла приведет просто к равномерному увеличению загрузки остальных узлов. Совокупность узлов кластера часто называют кластерной фермой. Минимальное количество узлов в ферме — два. Максимальное — 32.
При размещении высоконагруженных web-проектов в режиме NLB строится ферма web-серверов на IIS 7.х
Кластеры на виртуальных машинах
Наиболее доступным и масштабируемым решением является построение кластера на основе виртуальных машин на платформе Hyper-V.
В качестве web-боксов NLB-кластера используются виртуальные машины с установленными на них Windows Web Server 2008 (IIS7.х, пользовательское приложение).
В качестве кластера баз данных используется две виртуальные машины необходимой мощности на Windows Server 2008 Standard Edition и SQL Server 2008 Standard Edition.
Отказоустойчивое единое хранилище данных на основе Storage System от NetApp или HP.
Для обеспечения бОльшей надежности все узлы кластера располагаются на различных физических серверах\узлах кластера.
Масштабируемость решения достигается путем увеличения мощности используемых виртуальных машин (вплоть до 100% мощности физического сервера), а также за счет добавления новых узлов в NLB-кластер.
С использованием средств онлайновой миграции со временем возможен перенос узлов кластера на новые, более современные физические сервера без потери работоспособности и без простоя любого узла.
Данный кластер является лучшим решением в соотношении цена/качество и рекомендуется как для критичных для бизнеса приложений, так и для относительно нагруженных web-проектов (
до 30000-50000 посетителей ежедневно).
Кластеры на физических серверах
Web-проекты с нагрузкой выше 50000 посетителей, проекты со специальными требования по безопасности требуют построения кластерных решений на выделенных серверах без потерь мощностей физических серверов на виртуализацию.
Схема построения таких кластеров аналогична схеме построения кластеров на виртуальных машинах, только в качестве узлов используются выделенные физические серверы.
Геокластеры
При построении локальных кластеров единой точкой отказа системы является сама инфраструктура ЦОД. Parking.ru предлагает уникальное решение на российском рынке — построение географически распределенного кластера, узлы которого располагаются в разных ЦОДах Parking.ru.
Каждый из узлов кластера имеет независимый выход в интернет, но при этом из сети данных кластер выглядят как единый сервер с единым адресом и контентом.
Кластеризация
Кластеризация — это разбиение множества объектов на подмножества (кластеры) по заданному критерию. Каждый кластер включает максимально схожие между собой объекты. Представим переезд: нужно разложить по коробкам вещи по категориям (кластерам) — например одежда, посуда, декор, канцелярия, книги. Так удобнее перевозить и раскладывать предметы в новом жилье. Процесс сбора вещей по коробкам и будет кластеризацией.
Критерии кластеризации определяет человек, а не алгоритм, — этим она отличается от классификации. Этот метод машинного обучения (Machine Learning) часто применяют в различных неструктурированных данных — например если нужно автоматически разбить коллекцию изображений на мини-группы по цветам.

Кластерный анализ применяют в разных сферах:
Типы входных данных
Признаковое описание объектов
Объект описывается при помощи набора характеристик. Признаки бывают числовые и категориальные. Например, можно кластеризовать группу покупателей на основе их покупок в интернет-магазине. В качестве входных данных будут средний чек, возраст, количество покупок в месяц, любимая категория покупок и другие критерии.
Матрица расстояний между выделенными объектами
Это симметричная таблица, где по строкам и столбцам расположены объекты, а на пересечении — расстояние между ними: например, таблица с расстояниями между отелями в разных городах. Такой способ может помочь выделить кластеры отелей, которые сгруппированы в одной и той же локации.
Освойте самую востребованную технологию искусственного интеллекта. Дополнительная скидка 5% по промокоду BLOG.
Цели кластеризации
Сжатие данных
Кластеризация актуальна, если исходная выборка слишком большая. В результате от каждого кластера остается по одному типичному представителю. Количество кластеров может быть любым — здесь важно обеспечить максимальное сходство объектов внутри каждой группы.
Поиск паттернов внутри данных
Разбиение объектов на кластеры позволяет добавить дополнительный признак каждому объекту. Так, если в результате кластерного анализа выявилось, что определенный покупатель относится к первому кластеру, и мы знаем, что первый кластер — это кластер людей, которые тратят большое количество денег на покупки по средам, то можно сказать, что это покупатель приобретает продукты в основном по средам.
Поиск аномалий
В этом случае выделяют нетипичные объекты, не подходящие ни к одному сформированному кластеру. Интересны отдельные объекты, которые не вписываются ни в одну из сформированных групп.
Методы кластеризации
Общепринятой классификации методов нет, но есть несколько групп подходов.
1. Вероятностный подход. В рамках него предполагается, что каждый из объектов относится к одному из классов.
2. Подходы с учетом систем искусственного интеллекта. Большая условная группа методов, разнится с методической точки зрения.
4. Иерархический подход. Предполагает наличие вложенных групп — кластеров разного порядка. Выделяются агломеративные и дивизионные (объединительные и разделяющие) алгоритмы. В зависимости от количества признаков могут выделяться политетические (используют при сравнении нескольких признаков одновременно) и монотетические (используют при применении одного признака) методы классификации.
Как описать кластеризацию формально?
В кластеризации имеют дело с множеством объектов (X) и множеством номеров кластеров (Y). Задана функция расстояния между объектами ( p). Нужно разбить обучающую выборку на кластеры, так чтобы каждый кластер состоял из объектов, близких по метрике p, а объекты разных кластеров существенно отличались. При этом каждому объекту приписывается номер кластера y(i).
Алгоритм кластеризации — это функция, которая любому объекту X ставит в соответствие номер кластера Y.
Data Science с нуля
Вы получите достаточную математическую подготовку и опыт программирования на Python, чтобы решать задачи машинного обучения.



