Что такое объектное хранилище?
Упорядочение неструктурированных данных в плоской среде
Объектное хранилище — это способ хранения данных без иерархии, который обычно используется в облачной среде. В отличие от остальных способов хранения данных, объектное хранилище не использует дерево каталогов. Отдельные единицы данных (объекты) сосуществуют в пуле данных на одном уровне. Каждый объект имеет уникальный идентификатор, используемый приложением для обращения к нему. Кроме того, каждый объект может содержать метаданные, получаемые вместе с ним.
Почему именно объектное хранилище

Масштабируемость
Объектное хранилище может содержать практически любое количество данных без необходимости в разбиении набора данных на разделы.

Эффективность
Отсутствие иерархии означает отсутствие узких мест, возникающих вследствие использования сложных систем каталогов.

Доступность
Объектные системы хранения имеют механизмы для сохранения целостности данных, обеспечивают репликацию данных, последовательные обновления и отсутствие простоев.
Замечания по объектным хранилищам
Ограниченные возможности
API объектов для доступа к данным часто очень простые. Приложения должны отвечать большему числу требований к управлению данными.
Совместимость
Инструменты файловой системы, такие как утилиты на основе POSIX, не имеют возможности взаимодействовать с объектными системами хранения без дополнительных промежуточных уровней.
Типы данных
Объектное хранилище идеально для неструктурированных данных, таких как медиаданные и веб-материалы. Оно не подходит для данных, которые регулярно изменяются.
Поддержка API
Для того чтобы воспользоваться преимуществами объектного хранилища, требуется доработка приложений. Многие вендоры выпускают версии со встроенной поддержкой объектных хранилищ.
Откройте для себя гибридное облачное объектное хранилище, которое отличается гибкостью, соответствующей сегодняшним требованиям к данным.
Взгляд IBM. Свежий подход к объектному хранилищу
По мере того как сотрудники создают все больше материалов, ИТ-отделы предприятий отмечают экспоненциальный рост требований к хранилищам данных. Создание мультимедийных ресурсов — ключевой фактор.
Спрос на объектные системы хранения будет расти из-за необходимости архивировать больше неструктурированных данных. Этот рост будет стимулировать развертывание новых, экономически эффективных решений распределенных систем хранения, которые могут масштабироваться до сотен петабайтов.
Требования рынка
Десять лет назад мы ожидали, что объем данных в мире превысит уровень петабайта для большинства организаций, а для некоторых из них достигнет даже эксабайта. Сегодня мы живем в мире, где облачные технологии привели к наступлению эпохи революционного новаторства, а Интернет вещей (IoT) позволил миллионам устройств создавать, собирать и отправлять данные каждую секунду. Этот прогноз стал реальностью.
Для управления беспрецедентным объемом создаваемых данных предприятиям необходимо определить, каким образом можно эффективно защищать, хранить, анализировать и максимально повышать ценность своих неструктурированных данных. Предназначение объектного хранилища — делать это в масштабе Интернета.
Интернет спроектирован таким образом, чтобы технология распространения информации была полностью децентрализованной. Каждый объект в системе объектного хранилища уникален. Объекты идентифицируются по ИД, который однозначно определяет способ поиска объектов.
В данной системе хранения существует несколько физических узлов, работающих независимо друг от друга. В любой момент в систему можно добавить дополнительные узлы. Эта структура позволяет предприятиям масштабировать вместимость и производительность независимо друг от друга.
В этом процессе данные, записываемые в систему объектного хранилища приложением, передаются через уровень доступа, на котором они шифруются, разделяются на части и распределяются.
Уникальный ИД объекта используется для получения объекта через уровень доступа путем нахождения порогового номера хранимых частей и воссоздания объекта.
Технология хранения
Благодаря ссылкам на объекты по ИД, а не по именам файлов, систему можно масштабировать. Этот подход не имеет ограничений по размеру, а получать данные проще, поскольку в объект можно добавить большое количество метаданных.
Система объектного хранилища гарантирует, что ИТ могут пользоваться текущими инвестициями. Кроме того, она позволяет организации не упустить будущие возможности независимо от того, хранятся ли данные локально, в облаке или и там и там.
Обзор рынка
По мере того как организации пересматривают свои стратегии хранения данных, чтобы справиться с ростом скорости создания и потребления данных, объектное хранилище предоставляет предприятиям защищенное, адаптивное и экономное решение для управления данными.
Чем больше пул данных, тем выше стоимость долговременного владения. Информация доступна постоянно, а упрощенная платформа управления ускоряет обслуживание и дополнительные операции.
Облачные технологии, IoT и мобильные устройства являются движущей силой наполненного данными мира, и многие организации поймут, что инвестиции в завтрашний день начинаются сегодня. Объектное хранилище позволяет организациям, которым требуется работать с данными в масштабах Интернета, реализовать масштабируемое дальновидное решение для хранения данных, которое даст предприятиям возможность развиваться в течение следующих 20 лет и более.
Петабайты данных и быстрый поиск: зачем хранить файлы в облачном объектном хранилище
Большая часть современных компаний работает с огромными объемами данных, которые надо, во-первых, где-то хранить, а во-вторых — не потерять среди них что-нибудь важное. Объектные облачные хранилища (object cloud storage) легко справляются с решением этих проблем. Рассказываем, чем они отличаются от других видов хранилищ и какую информацию там лучше всего хранить.
Что такое объектное S3-хранилище
Объектное хранилище, или object storage, подходит для хранения и управления большими объемами информации: аудио и видеофайлы, документы, сообщения чатов, письма. Его используют, когда традиционная система хранения с множеством файлов и папок становится неудобной и неэффективной.
Компании могут развернуть объектное хранилище в собственном центре обработки данных (ЦОД) или воспользоваться услугой облачных провайдеров. Объектные хранилища взаимодействуют с приложениями через программный интерфейс — то есть, через команды, которые хранилище и приложения передают друг другу. Как правило, это интерфейсы S3 API, Swift API или CDMI.
Наличие стандартного интерфейса у хранилища позволяет без проблем его использовать большинству приложений и систем. S3-совместимые хранилища (S3 compatible storage) сейчас используют чаще всего.
В чем плюсы объектного хранения данных
Бывает, что нужно предоставить доступ к объектам хранения одновременно многим пользователям. Например — видеохостинг должен выдерживать тысячи запросов к выложенному видеоролику. Для таких задач не подходят «обычные» хранилища данных, в том числе — жесткие диски и облачные хранилища других типов, например, такие, где пользователи хранят свои фото: они не оптимизированы под параллельный доступ многих пользователей.
Объектные хранилища реализованы таким образом, что число обращений пользователей к объектам практически не замедляет доступ к ним.
При этом доступ к самому облачному объектному хранилищу данных возможен из любой точки мира, а совокупный объем загружаемых файлов может достигать десятков и сотен петабайт. Посмотрим, для чего его можно использовать.
Объектные системы хранения – что, зачем и для чего
Если погуглить по ключевым словам «объектные системы хранения» или object storage, то можно найти много текстов, объясняющих, что такое объектное хранилище и как оно работает, как объектные системы опережают в росте объемов другие типы систем хранения: блочные и файловые. Но мало кто говорит, чем такой рост вызван, какие практические преимущества могут дать ИТ-бизнесу объектные системы хранения, для решения каких проблем они создаются.
Чтобы избавить вас от попыток составить единую картину из разрозненных фактов, которые к тому же надо искать преимущественно в англоязычных источниках, мы постараемся дать краткое и, по возможности, полное объяснение, что такое объектные системы хранения, зачем и в каких случаях они нужны.
Зачем?
Не секрет, что рост объемов хранимых данных в последние годы происходит экспоненциально. По результатам опроса, проведенного исследовательской компанией «451 Research» в 2017 году, более 60 % организаций заявили, что объемы их систем хранения превышают 50 Петабайт, и процент их роста выражен двузначной цифрой. Если читатель работает инженером по системам хранения, ему не нужно объяснять, что традиционные системы хранения (блочные и файловые) просто не рассчитаны на такие темпы роста объемов данных, которые нужно надежно хранить и защищать.
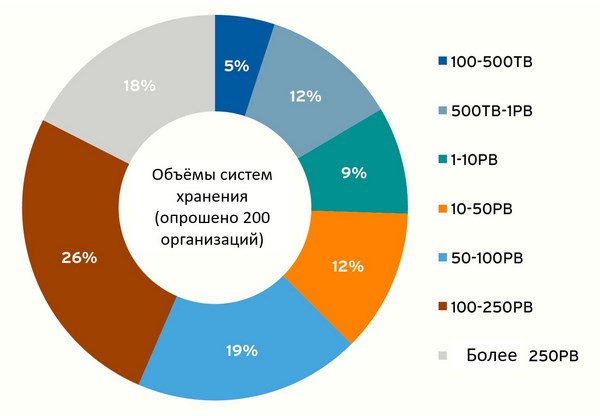
Объемы хранимых данных (источник: 451 Research, Western Digital, 2017 г.)
Традиционный подход
Традиционный подход к хранению данных – системы SAN (Storage Area Network) или NAS (Network attached Storage), если не рассматривать совсем простые системы DAS (Direct Attached Storage) – это, например, внешняя дисковая полка, подключенная напрямую к RAID-контроллеру сервера.
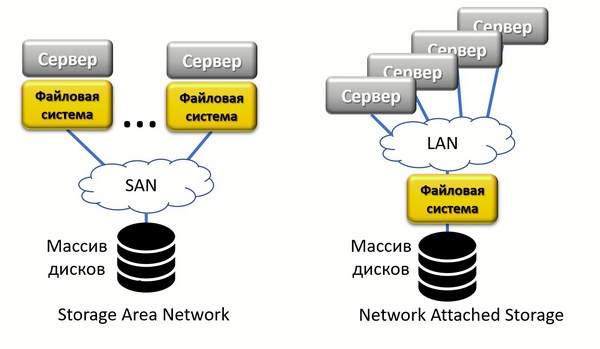
Различия SAN и NAS
Такой метод подойдет при относительно небольших объемах хранения. При росте дискового хранилища возникают проблемы с файловой системой. Традиционные файловые системы разбивают каждый файл на маленькие блоки, обычно объемом 4 килобайта, и сохраняют месторасположение каждого блока в таблицах просмотра (lookup table) файловой системы. Для небольших объемов данных это хорошо, но как только вы расширите систему хранения до петабайта и больше, таблицы станут непомерно огромными. Это сильно замедляет поиск нужного блока и увеличивает возможность ошибок.
Поэтому пользователи вынуждены разбивать свои наборы данных на многочисленные логические узлы LUN (Logical Unit Number), чтобы как-то поддержать быстродействие на приемлемом уровне. Однако при этом значительно увеличиваются сложность и затраты на администрирование и поддержку ИТ-системы, а проблемы быстродействия, потери данных и простои системы сказываются на бизнес-процессах.
Распределенная файловая система
Для решения этой проблемы стали использовать так называемые горизонтально-масштабируемые (Scale-out) файловые системы, такие как HDFS (Hadoop Distributed File System). Это распределенная файловая система на базе Hadoop, свободно распространяемого набора утилит для создания распределенных систем, работающих на кластерах из сотен и тысяч узлов. Проблема масштабирования при этом решается, однако поддержка таких систем также довольно трудоемка. Они конструктивно сложны и требуют постоянного обслуживания. К тому же в них чаще всего используется механизм репликации данных, то есть попросту хранения копий одних и тех же данных в разных местах системы. Стандартно сохраняются три копии каждого файла. Излишне говорить, что это увеличивает требуемый дисковый объем на целых 200 %! Хотя цены на диски все время снижаются, но объемы данных, которые необходимо хранить, растут еще быстрее. Это напрочь съедает экономию на недорогих дисках. Для петабайтов информации такой подход неприемлем.
Облачное хранение
Для минимизации этих проблем многие стали прибегать к использованию облачных хранилищ. Модель оплаты по мере потребления (pay-as-you-go) работает отлично, но опять-таки – для относительно небольших объемов данных и при нечастом их использовании. При постоянном масштабировании объемов данных, интенсивной работе с ними этот подход также становится весьма затратным, не дешевле HDFS. Дело в том, что многие облачные провайдеры берут плату не только за объем хранимых данных, но и за трафик извлекаемых/записываемых данных, а также и за число транзакций (обращений) к хранилищу. Поэтому, когда приходится иметь дело с анализом больших данных, передачей массивных объемов данных, то хранилище в публичном облаке – наверное, самый дорогой подход. Кроме того, могут возникнуть проблемы конфиденциальности данных и производительности системы, если много других пользователей также будут интенсивно использовать ресурсы данного облака.
Что делать?
Выходом в такой ситуации может быть объектная система хранения (object storage), в которой используются примерно те же технологии, что в публичном облаке (HTTP, API). Объектные хранилища можно легко масштабировать до объемов петабайта в одном домене, без какой-либо деградации производительности. Кроме того, объектные хранилища имеют функционал управления данными, чего нет в традиционных системах: управлении версиями, кастомизации метаданных и встроенной аналитике.
Такие характеристики достигаются за счет абстрагирования уровней системы – общий подход, который сейчас используется практически во всех ИТ- и телеком-системах, не только в системах хранения. Каждый диск на нижележащем уровне форматируется простой локальной файловой системой, такой как EXT4. На верхнем уровне, абстрагированном от нижнего, размещаются средства управления, что позволяет интегрировать все элементы в едином унифицированном томе. Файлы различного вида хранятся как «объекты», а не как файлы в файловой системе. Поскольку низкоуровневое управление блоками передано локальной файловой системе, объектное хранилище ведает только функциями управления высокого уровня, которые управляют нижележащим уровнем через стандартный интерфейс прикладного программирования API (Application Programing Interface).
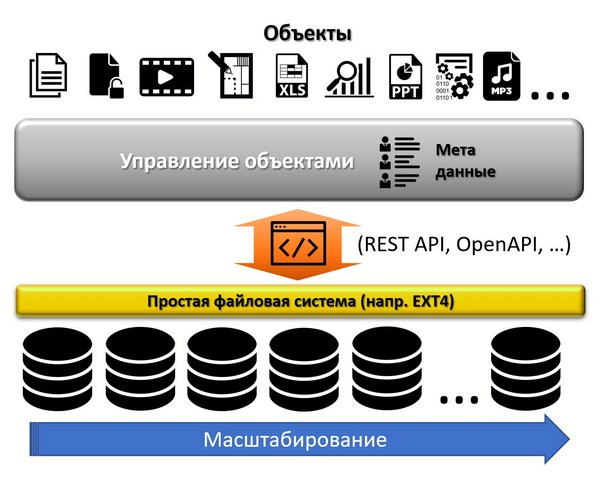
Объектная система хранения
Принцип объектного хранения можно сравнить с услугой парковки, когда вы просто оставляете машину (объект) для ее размещения на парковочном пространстве и получаете карточку, по которой вы можете получить машину обратно. В карточку могут быть внесены «метаданные»: ваше имя, номер и марка машины. Где именно запаркуют машину, вам неинтересно (абстрагирование), и вам не нужно кружить по парковке в поисках свободного места.
Такой подход позволяет сохранять таблицы просмотра файловой системы каждого узла нижележащего уровня в пределах легко управляемого размера. Это позволяет масштабировать систему до сотен петабайт без заметного снижения производительности.
Структурированные и неструктурированные данные
Понятие «структурированные» и «неструктурированные» данные – весьма относительно. Все файлы с данными имеют ту или иную структуру, тип файла. Поэтому, с этой точки зрения, все файлы – структурированные. Когда говорят, что данные – неструктурированные, имеется в виду, что они не хранятся в единой базе и содержат разные типы данных. Это просто набор разнородных файлов, созданных в различных приложениях и полученных из разных источников. Если открыть на компьютере папку «Мои документы», то примерно это там и будет.
Объектное хранилище предназначено в основном для работы с неструктурированными данными. Объекты неструктурированных данных можно пометить метаданными, которые описывают их содержимое и помогают быстро извлечь из хранилища нужный объект. В этом случае сами метаданные будут структурированы, т. е. будут иметь стандартную форму, определенную в API. Это позволяет отслеживать и индексировать объекты, без необходимости применять внешние программы или базы данных. Использование метаданных открывает новые возможности для аналитики. Файлы (объекты) можно индексировать и искать в объектном хранилище, не зная структуру их содержимого или того, в какой программе они были созданы.
Защита данных
Нужна ли репликация данных для надежного хранения в объектной системе? Да, нужна, но при этом не требуется утраивать объем дискового пространства, как в блочной системе. Для максимизации доступного дискового пространства и защиты данных используется технология Erasure Coding (ЕС). Упрощенно ее можно назвать следующим поколением хорошо известного метода защиты данных RAID, при котором необходимо двойное или тройное резервирование.
В методе ЕС файлы объектов разделяются на фрагменты (shards). Для некоторых из них создаются копии избыточности в формате N+M. Например, если для шести из десяти фрагментов создаются копии, это будет формат 10+6. Данные, для которых нужно, например, N дисков, копии избыточности распределяются по N+M дискам (в данном случае 16). При потере любых шести дисков, оставшихся десяти достаточно для восстановления исходных данных. Таким образом, избыточность объема хранения получается не такой большой, как в RAID, и она может противостоять множественным отказам дисков без риска потери данных. Тома ЕС могут выдерживать больше отказов дисков, чем дисковые массивы RAID. При этом петабайтное масштабирование системы не будет приводить к столь большим затратам на закупку дисков, как в файловых системах.
Для чего?
Объектное хранилище часто выбирается для данных WORM, которые пишутся один раз, но читаются много раз (Write Once Read Many). Оно подходит не для всех объемов данных и сценариев использования, но, безусловно, имеет много применений.
Объектные системы хранения целесообразно использовать в следующих случаях:
Таким образом, мы видим, что объектные системы хранения хорошо подходят для хранения массивных разнородных (неструктурированных) данных и отвечают запросам бурного роста объемов данных, которые нужно хранить, обрабатывать и анализировать в различных отраслях. Именно поэтому объемы объектных систем хранения растут значительно быстрее объемов файловых систем.
В следующей статье мы представим обзор рынка объектных СХД на примере популярных систем объектного хранения:
Как используют объектное хранилище, чтобы обыграть конкурентов
Объектные хранилища — облачный сервис для дешёвого хранения и массовой раздачи информации в больших объёмах. Они нужны в первую очередь разработчикам и легко встраиваются в любое приложение, будь то мобильная игра, видеохостинг или корпоративная система документооборота.
Мы расскажем о том, как клиенты платформы Mail.ru Cloud Solutions (MCS) реально используют объектные хранилища и ставят эту технологию в основу своего конкурентного преимущества. Здесь собраны кейсы Mail.ru Group, а именно ICQ (мессенджер), «Смотри Mail.ru» (персонализированная видеоплатформа), а также других компаний: «Битрикс24» (SaaS для управления бизнесом), Max Group (услуги торгового маркетинга), «Биорг» (умная оцифровка изображений) и Prequel (приложение для смартфона).
В объектные хранилища можно поместить любые данные: аудио- и видеофайлы, документы, бэкапы, фрагменты кода. Хранилище решает две главные задачи: надёжное хранение любого объёма данных и быструю их раздачу любому количеству пользователей. Представьте видеохостинг, который должен «без тормозов» раздавать видео на десятки тысяч одновременных запросов: это идеальная задача для такого хранилища.
Объектное хранилище особенно полезно, когда заранее не знаешь, какой объём хранения понадобится: в него можно поместить сотни петабайт данных в любой момент.
Биллинг хранилищ опирается на реальный объём находящихся в них данных и интенсивность их скачивания, так что оплачиваемые облачные ресурсы утилизированы на 100%. Это делает объектное хранилище мощным инструментом оптимизации расходов и ускорения вывода новых продуктов на рынок.
Стоимость скачивания данных из объектного хранилища различается у разных провайдеров. Приложение Prequel до прихода в MCS хранило данные в хранилище зарубежного провайдера Amazon Web Services (AWS). Переход на MCS, который предлагает скачивание по более низкой стоимости, удешевил раздачу контента.
Сам переход на новое хранилище занял несколько дней. AWS оставили «в резерве»: MCS раздаёт основной трафик, а AWS хранит синхронизированный бэкап.
По закону «О персональных данных» (152-ФЗ) обрабатывать персональные данные следует на территории России. Обработкой данных считаются любые действия с ними, в том числе сбор и хранение. Размещение таких данных в объектном хранилище MCS позволяет компаниям соблюдать требования российского законодательства.
Когда этот закон появился, «Битрикс24» хранили данные у зарубежного провайдера. Для исполнения закона можно было самостоятельно построить инфраструктуру хранения данных. Но это было невыгодно, потому что сервис «Битрикс24» активно рос, пришлось бы постоянно покупать оборудование и самостоятельно его администрировать. Компания решила сосредоточиться на своих продуктах, а не на поддержке инфраструктуры, поэтому перенесла обслуживание российских проектов на платформу MCS.
Возможность быстро получить ИТ-ресурсы в облаке особенно важна для экспериментальных проектов с непредсказуемой нагрузкой — и для стартапов, которые тестируют рынок с помощью MVP, и для R&D-проектов крупных компаний.
Раньше для такого запуска приходилось закупать оборудование, до введения которого в эксплуатацию могли пройти месяцы. Ошибки в объёме закупленных ресурсов было нереально исправить, и внезапный рост базы пользователей и объёма данных мог «завалить» систему под нагрузкой. Теперь в облаке по запросу можно сразу получить нужное количество ресурсов без длительных закупок, а при необходимости менять объём использования.
Создатели видеоплатформы «Смотри Mail.ru» не стали вкладываться в построение собственной инфраструктуры — весь видеоконтент разместили в объектном S3-хранилище MCS. Веб-сайт и мобильные приложения платформы загружают контент для показа в плеере из объектного хранилища.
Характерно, что «Смотри» начали использовать объектное хранилище с самого начала тестирования проекта, но продолжают его использовать по тем же принципам и сейчас, когда аудитория проекта значительно выросла.
Изначальный выбор этого масштабируемого решения избавил проект от замедления работы системы в момент роста проекта и последующего болезненного переезда.
Когда объём хранения постоянно растёт или плохо предсказуем, поддержка собственного хранилища ложится тяжким бременем на IT-службу компании, перетягивает ресурсы и управленческий фокус на себя с основного бизнеса. Объектные хранилища и другие облачные сервисы снимают эту непрофильную рутину и развязывают руки экспертам компании для развития бизнеса и решения стратегических задач.
Max Group оказывает услуги торгового маркетинга для крупнейших FMCG-компаний, и её сотрудники и клиенты взаимодействуют через сервис Max Merch. В условиях роста потока данных и нагрузки на инфраструктуру компания отказалась от регулярной покупки собственного железа и перешла к размещению нагрузки и хранению данных в MCS. Это на 20% уменьшило совокупную стоимость инфраструктуры и обеспечило высокую скорость работы сервиса.
Переход к облачной инфраструктуре, её оптимизацию и в целом администрирование можно отдать на аутсорс в рамках управляемых услуг (managed services).
Снизить стоимость итоговых решений клиентам MCS помогают некоторые технические приёмы.
Данные сразу готовы к скачиванию и использованию. Видеоплеер «Смотри Mail.ru» показывает видео, которое таким способом «подтягивается» из S3-хранилища.
Благодаря этому в том месте, где происходит транскодирование, не нужно хранить большие временные файлы, а сеть не перегружается закачкой объёмных файлов. Всё это позволяет параллельно транскодировать много видеофайлов.
В итоге приёмы использования хранилища строятся вокруг его способности к неограниченному масштабированию и возможности одновременного доступа многих пользователей. В корпоративных системах и бэкенде приложений достаточно распространены и более традиционные средства хранения данных, но при сколь-нибудь значимом масштабировании владельцы этих систем сталкиваются с трудностями. Переход к объектному хранению потребует некоторого редизайна действующей системы, но когда объёмы хранения постоянно меняются, это оправдано.
Принципы организации объектных хранилищ

Наш коллега недавно написал об архитектуре объектного S3-хранилища Mail.ru Cloud Storage. Теперь мы переводим хорошую статью об общих особенностях и ограничениях объектных хранилищ.
Объектные хранилища более масштабируемые, отказоустойчивые и надежные, чем параллельные файловые системы, кроме того, у них ошеломляющая пропускная способность для некоторых рабочих нагрузок. Такие характеристики производительности достигаются за счет отказа от файлов и каталогов.
В отличие от файловых систем, объектные хранилища не поддерживают вызовы ввода-вывода POSIX: открытие, закрытие, чтение, запись и поиск файла. Вместо этого у них только две основные операции: PUT и GET.
Ключевые особенности объектных хранилищ
Поскольку у объектного хранилища всего несколько доступных операций, появляются важные ограничения:
Эта нарочитая простота приводит к ряду ценных последствий в контексте высокопроизводительных вычислений:
Обратите внимание, что во многих реализациях объектных хранилищ к неизменяемости объектов подходят с некоторой гибкостью. Например, режим доступа только с добавлением по-прежнему устраняет узкие места блокировки, улучшая при этом полезность хранилища.
Ограничения объектных хранилищ
Простота организации объектного хранилища делает его масштабируемым, но также ограничивает его функциональность:

Поскольку объектное хранилище не пытается сохранить совместимость с POSIX, реализации шлюзов — удобные места для хранения метаданных объектов, превосходящие те, что традиционно предоставлялись ACL POSIX и NFSv4.
Например, S3 API предоставляет средства для связывания произвольных пар ключ-значение с объектами в качестве определяемых пользователем метаданных. А WOS DDN — запрашивать базу метаданных объектов, чтобы выбрать все объекты, соответствующие критериям запроса.
На базе объектных хранилищ можно построить и гораздо более сложные интерфейсы. Большинство параллельных файловых систем, включая Lustre, Panasas и BeeGFS, построены на концепциях, вытекающих из объектного хранилища. Они идут на компромиссы во внешнем и внутреннем интерфейсе, чтобы сбалансировать масштабируемость с производительностью и удобством использования. Но такая гибкость обеспечивается за счет построения поверх объектно-ориентированных, а не блочных, представлений данных.
Хотя отделение пользовательского интерфейса от базового объектного представления данных обеспечивает гибкость, не все такие шлюзы — шлюзы с двойным доступом. Двойной (или, например, тройной) доступ позволяет получать доступ к одним и тем же данным через несколько интерфейсов. Например, записывать объект с помощью PUT, но читать его обратно, как если бы это был файл. Шлюзы с двойным доступом стараются делать согласованными, однако, возможна ситуация, когда после записи данных они не сразу видны через все интерфейсы.
Реализации объектных хранилищ
Хотя принципы организации объектного хранилища достаточно просты, конкретные продукты отличаются. В частности, для обеспечения устойчивости, масштабируемости и производительности могут использоваться различные способы перемещения данных при получении запроса PUT или GET.
ShellStore: простейший пример
В этом разделе я хочу проиллюстрировать простоту базового хранилища объектов с помощью ShellStore Яна Киркера. Оно представляет собой хотя и безумную, но удивительно лаконичную реализацию объектного хранилища. Прелесть в том, что он демонстрирует основные тонкости работы хранилища с помощью простого bash.
DDN WOS
DDN WOS создавали как высокопроизводительное масштабируемое объектное хранилище, ориентированное на рынок высокопроизводительных систем хранения. Поскольку DDN WOS создавали с нуля, его конструкция проста, разумна и учитывает недостатки дизайна более ранних продуктов.
Простота WOS делает его отличной моделью для иллюстрации того, как в целом работают объектные хранилища. WOS используют очень крупные компании (например, считается, что на нем работает Siri), оно имеет такие примечательные особенности:
Openstack Swift
OpenStack Swift — одна из первых крупных реализаций объектного хранилища корпоративного уровня с открытым исходным кодом. Это то, что сегодня стоит за многими частными облаками. Но поскольку хранилище писали давно, в его архитектуре много неоптимальных решений:
RedHat/Inktank Ceph
Ceph использует детерминированный хэш, называемый CRUSH, который позволяет клиентам напрямую связываться с серверами хранилища объектов. Искать местоположение объекта для каждой операции чтения или записи не нужно.
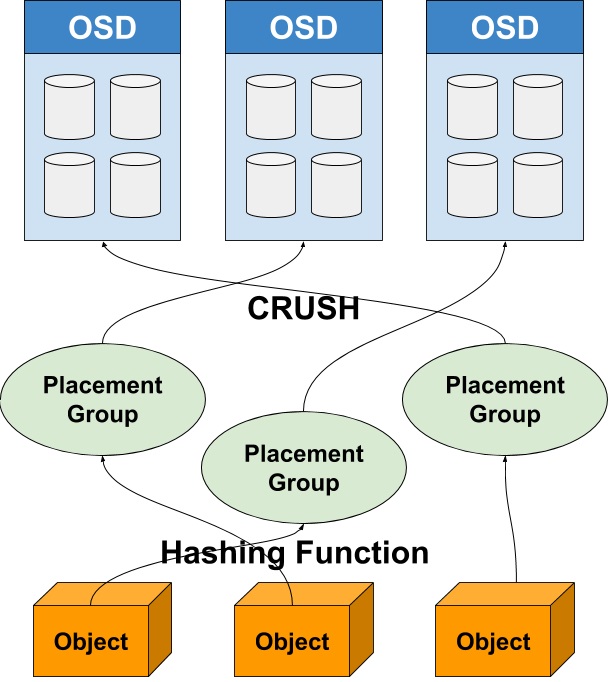
Общая схема потока данных
Объекты сопоставляются с группами размещения с помощью простой хеш-функции. Группы размещения (PG) — логические абстракции. Через хэш CRUSH они сопоставляются с демонами хранения объектов, которые владеют коллекциями физических дисков.
CRUSH уникален тем, что позволяет добавлять дополнительные OSD без перестройки всей структуры карты объект-PG-OSD. Переназначать на недавно добавленные OSD нужно только часть групп размещения, что обеспечивает гибкую масштабируемость и отказоустойчивость.
Группы размещения содержат собственные политики устойчивости объектов, а алгоритм CRUSH позволяет физически реплицировать объекты и географически распределять их по нескольким OSD.
Ceph реализует политику устойчивости на стороне сервера, так что клиент, выполняющий PUT или GET объекта, общается только с одним OSD. После помещения объекта в OSD этот OSD отвечает за его репликацию в другие OSD, выполнение сегментирования, кодирования стиранием и распределения закодированных сегментов. Хорошее описание (с диаграммами) путей данных репликации и кодирования стиранием Ceph опубликовали в Intel.
Ещё несколько ресурсов с информацией об архитектуре Ceph:
Scality RING
Я почти ничего не знаю о Scality RING. Но эта платформа быстро проникает в сферу High-Performance Computing и используется в Национальной лаборатории Лос-Аламоса, которая ведет разработки в области ядерного вооружения.
Scality RING — исключительно программный продукт (в отличие от DDN WOS), который работает на любом оборудовании. У него есть все стандартные шлюзовые интерфейсы (S3, NFS / CIFS и REST, называемые «коннекторами»), кодирование со стиранием и масштабируемый дизайн. Кажется, он основан на детерминированном хеш-коде, который отображает данные на определенный узел хранения в кластере. Все узлы хранения — одноранговые, и с помощью внутренней одноранговой передачи любой узел может отвечать на запросы данных, хранящихся на любом другом узле.
Некоторые архитектурные детали и ссылки на конкретные патенты — в презентации Scality RING.
Другие продукты
Хочу рассказать еще о нескольких платформах объектного хранения. Правда, они менее актуальны для индустрии высокопроизводительных вычислений из-за их направленности или особенностей проектирования.
NetApp StorageGRID
Платформа хранения объектов StorageGRID от NetApp появилась после покупки компании Bycast. StorageGRID в основном используют в бизнесе, связанном с хранением медицинских записей. NetApp особо не рассказывает о StorageGRID, и, насколько я могу судить, отметить нечего, кроме использования Cassandra в качестве прокси-базы данных для отслеживания индексов объектов.
Cleversafe
Cleversafe — платформа для хранения объектов, ориентированная на корпоративный рынок и обладающая исключительной надежностью. Они продают программный продукт, но по своеобразной модели.
Кластеры Cleversafe нельзя легко масштабировать, поскольку вы должны заранее купить все узлы хранения объектов (sliceStors). Всё, что вы можете — увеличивать емкость каждого узла хранения. Заполните до предела емкость каждого узла — придется покупать новый кластер. Такой подход нормален для организаций, которые масштабируются целыми стойками, но менее практичен за пределами высокопроизводительных центров HPC. Среди известных клиентов Cleversafe — Shutterfly.
Cleversafe не так функциональна, как другие платформы хранения объектов (если судить по последней инструкции, которую я читал). Она предоставляет несколько интерфейсов REST («устройств доступа»), включая S3, Swift и HDFS. Но доступ на основе NFS/CIFS осуществляется сторонними приложениями поверх S3/Swift. Впрочем, крупные компании часто пишут собственное ПО для работы с S3, так что это небольшое препятствие при масштабировании.
Периферийные технологии
Представленные ниже решения хоть и не являются строго платформами объектного хранения, дополняют или отражают дух объектных хранилищ.
iRODS: объектное хранилище без объектов или хранилища
iRODS обеспечивает уровень шлюза объектного хранилища без хранилища объектов под ним. Он способен превратить набор файловых систем во что-то, похожее на хранилище объектов, отказавшись от соответствия POSIX в пользу более гибкого и ориентированного на метаданные интерфейса. Однако iRODS предназначен для управления данными, а не для высокой производительности.
MarFS: POSIX-интерфейс к объектному хранилищу
MarFS — платформа, разработанная в Национальной лаборатории Лос-Аламоса. Предоставляет интерфейс для объектного хранилища, включающий знакомые операции POSIX. В отличие от шлюза, который находится перед хранилищем объектов, MarFS предоставляет интерфейс непосредственно на клиентских узлах и прозрачно транслирует операции POSIX в вызовы API, понятные хранилищу объектов.
Спроектированная как легкая, модульная и масштабируемая, MarFS во многом выполняет те же функции, что, например, клиент llite, сопоставляя вызовы POSIX на клиенте хранилища, с вызовами, понятными базовому представлению данных Lustre.
В текущей реализации, которую используют в LANL, — файловая система GPFS для хранения метаданных, которые обычная файловая система POSIX будет предоставлять своим пользователям. Вместо того чтобы хранить данные в GPFS, все файлы в этой индекс-системе являются заглушками — они не содержат данных, но имеют владельца, разрешения и другие атрибуты POSIX-объектов, которые они представляют.
Сами же данные находятся в хранилище объектов (предоставляемом Scality в реализации LANL), а демон MarFS FUSE на каждом клиенте хранилища использует файловую индекс-систему GPFS для связывания вызовов ввода-вывода POSIX с данными, находящимися в хранилище объектов.
Поскольку он подключает клиентов хранилища напрямую к хранилищу объектов, а не действует как шлюз, MarFS предоставляет только подмножество операций ввода-вывода POSIX. В частности, поскольку базовые данные хранятся как неизменяемые объекты, MarFS не позволяет пользователям перезаписывать данные, которые уже существуют.
Посмотрите презентацию MarFS на MSST 2016, чтобы узнать больше.



