Дерево (структура данных)
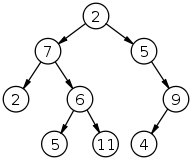

Дерево — одна из наиболее широко распространённых структур данных в информатике, эмулирующая древовидную структуру в виде набора связанных узлов. Является связанным графом, не содержащим циклы. Большинство источников также добавляют условие на то, что рёбра графа не должны быть ориентированными. В дополнение к этим трём ограничениям, в некоторых источниках указываются, что рёбра графа не должны быть взвешенными.
Содержание
Определения
Дерево считается ориентированным, если в корень не заходит ни одно ребро.
Узел является экземпляром одного из двух типов элементов графа, соответствующим объекту некоторой фиксированной природы. Узел может содержать значение, состояние или представление отдельной информационной структуры или самого дерева. Каждый узел дерева имеет ноль или более узлов-потомков, которые располагаются ниже по дереву (по соглашению, деревья ‘растут’ вниз, а не вверх, как это происходит с настоящими деревьями). Узел, имеющий потомка, называется узлом-родителем относительно своего потомка (или узлом-предшественником, или старшим). Каждый узел имеет не больше одного предка. Высота узла — это максимальная длина нисходящего пути от этого узла к самому нижнему узлу (краевому узлу), называемому листом. Высота корневого узла равна высоте всего дерева. Глубина вложенности узла равна длине пути до корневого узла.
Корневые узлы
Самый верхний узел дерева называется корневым узлом. Быть самым верхним узлом подразумевает отсутствие у корневого узла предков. Это узел, на котором начинается выполнение большинства операций над деревом (хотя некоторые алгоритмы начинают выполнение с «листов» и выполняются, пока не достигнут корня). Все прочие узлы могут быть достигнуты путём перехода от корневого узла по рёбрам (или ссылкам). (Согласно формальному определению, каждый подобный путь должен быть уникальным). В диаграммах он обычно изображается на самой вершине. В некоторых деревьях, например, кучах, корневой узел обладает особыми свойствами. Каждый узел дерева можно рассматривать как корневой узел поддерева, «растущего» из этого узла.
Поддеревья
Поддерево — часть древообразной структуры данных, которая может быть представлена в виде отдельного дерева. Любой узел дерева T вместе со всеми его узлами-потомками является поддеревом дерева T. Для любого узла поддерева либо должен быть путь в корневой узел этого поддерева, либо сам узел должен являться корневым. То есть поддерево связано с корневым узлом целым деревом, а отношения поддерева со всеми прочими узлами определяются через понятие соответствующее поддерево (по аналогии с термином «соответствующее подмножество»).
Упорядочивание деревьев
Существует два основных типа деревьев. В рекурсивном дереве или неупорядоченном дереве имеет значение лишь структура самого дерева без учёта порядка потомков для каждого узла. Дерево, в котором задан порядок (например, каждому ребру, ведущему к потомку, присвоены различные натуральные числа) называется деревом с именованными рёбрами или упорядоченным деревом со структурой данных, заданной перед именованием и называемой структурой данных упорядоченного дерева.
Упорядоченные деревья являются наиболее распространёнными среди древовидных структур. Двоичное дерево поиска — одно из разновидностей упорядоченного дерева.
Представление деревьев
Существует множество различных способов представления деревьев. Наиболее общий способ представления изображает узлы как записи, расположенные в динамически выделяемой памяти с указателями на своих потомков, предков (или и тех и других), или как элементы массива, связанные между собой отношениями, определёнными их позициями в массиве (например, двоичная куча).
Деревья как графы
В теории графов дерево — связанный ациклический граф. Корневое дерево — это граф с вершиной, выделенной в качестве корневой. В этом случае любые две вершины, связанные ребром, наследуют отношения «родитель-потомок». Ациклический граф со множеством связанных компонентов или набор корневых деревьев иногда называется лесом.
Методы обхода
Пошаговый перебор элементов дерева по связям между узлами-предками и узлами-потомками называется обходом дерева. Зачастую, операция может быть выполнена переходом указателя по отдельным узлам. Обход, при котором каждый узел-предок просматривается прежде его потомков называется предупорядоченным обходом или обходом в прямом порядке (pre-order walk), а когда просматриваются сначала потомки, а потом предки, то обход называется поступорядоченным обходом или обходом в обратном порядке (post-order walk). Существует также симметричный обход, при котором посещается сначала левое поддерево, затем узел, затем — правое поддерево, и обход в ширину, при котором узлы посещаются уровень за уровнем (N-й уровень дерева — множество узлов с высотой N). Каждый уровень обходится слева направо.
Структуры данных. Деревья
Статья познакомит вас с понятием дерева как структуры данных, пояснит в каких случаях и для чего можно их применять:
1 Что такое деревья (в программировании)?
Математическое определение дерева — «граф без петель и циклов» вряд-ли пояснит рядовому человеку какие выгоды можно извлечь из такой структуры данных.
В некоторых книгах, посвященным разработке алгоритмов, деревья определяются рекурсивно. Дерево является либо пустым, либо состоит из узла (корня), являющегося родительским узлом для некоторого количества деревьев (это количество определяет арность дерева) [1, 2].
Рабочее определение (в рамках этой статьи): дерево — это способ организации данных в виде иерархической структуры.
Когда применяются древовидные структуры:
Двоичный поиск [3] выполняется над отсортированным массивом. На каждом шаге искомый элемент сравнивается со значением, находящимся посередине массива. В зависимости от результатов сравнения — либо левая, либо правая части могут быть «отброшены».
Иерархия — способ упорядочивания объектов, соответственно применять ее можно для ускорения поиска. Именно этому посвящена остальная часть статьи.
2 Деревья и другие структуры данных
Итак, у нас есть много данных — возможно это информация о температуре за несколько лет, а может быть — данные о фирмах в вашем городе. Как хранить их внутри вашего приложения? — Правильный ответ зависит от того, как именно вы будете пользоваться этими данными.
В таблице приведены асимптотические оценки часто используемых операций над некоторыми структурами данных. На случай если вы еще не освоили асимптотический анализ, в таблице показано примерное значение количества действий, необходимых для выполнения операции над контейнером из 10 тысяч элементов.
| Операция | неупорядоченный массив | упорядоченный массив | неупорядоченный двусвязный список | сбалансированное дерево поиска |
|---|---|---|---|---|



4 Kd-деревья
Во многих программах появляется необходимость хранения и эффективной обработки объектов на плоскости. Это не только картографические приложения, но и все двумерные игры. Задумывались ли вы о том, как эту задачу решают игровые движки?

Мы уже разобрались с тем, что для эффективной реализации поиска объекты нужно хранить упорядоченными. Однако, как хранить точки? — ведь у них есть две (или три) координаты, а сортировка по одной из них не обеспечит приемлемую скорость поиска. Именно эти проблемы решают Kd-деревья.
Общая идея kd-деревьев заключается в разделении плоскости, содержащей объекты на части (прямоугольные области) таким образом, что в каждой области содержится один объект. При этом, между областями можно выстроить иерархические зависимости, за счет которых можно существенно повысить эффективность поиска. Существуют различные типы kd-деревьев, отличающиеся выбором секущей плоскости.
Задача: есть множество точек, находящихся на плоскости, нужно выстроить объекты в иерархическую структуру, исходя из их координат для обеспечения эффективного поиска. Описанные ниже подходы можно обобщить до более сложных геометрических объектов (не точек) и пространств больших размерностей.
Первый вариант решения:

С такой структурой данных, алгоритм вывода всех точек, входящих в Прямоугольник может выглядеть так:
Цветом на приведенной выше схеме обозначена область поиска. Она не пересекается с областью B (расположенной левее А ). Даже если бы в этой области были миллионы точек — мы «отсекли» бы их за одну итерацию алгоритма — то есть мы получили полноценный двоичный поиск на плоскости. Визуализация алгоритма: 
При перемещении объектов может возникать необходимость перестроения дерева — если объект переместился из одной области «родительского» объекта в другую.
Описанный подход называется Kd-деревья с циклическим проходом по измерениям. Возможны и другие варианты выбора секущей плоскости — например каждый узел квадрадерева делит свою часть плоскости на 4 части (левая верхняя, левая нижняя, правая верхняя, права нижняя). Если в какой-то части оказывается более 1 объекта — то она делится дальше. Октадеревья адаптируют эту идею к трехмерному пространству.
Все что нужно знать о древовидных структурах данных

Когда вы впервые учитесь кодировать, общепринято изучать массивы в качестве «основной структуры данных».
В конце концов, вы также изучаете хэш-таблицы. Для получения степени по «Компьютерным наукам» (Computer Science) вам придется походить на занятия по структурам данных, на которых вы узнаете о связанных списках, очередях и стеках. Эти структуры данных называются «линейными», поскольку они имеют логические начало и завершение.
Однако в самом начале изучения деревьев и графов мы можем оказаться слегка сбитыми с толку. Нам привычно хранить данные линейным способом, а эти две структуры хранят данные совершенно иначе.
Данная статья поможет вам лучше понять древовидные структуры данных и устранить все недоразумения на их счет.
Из этой статьи вы узнаете:
Давайте начнем наше учебное путешествие 🙂
Определения
Когда вы только начинаете изучать программирование, обычно бывает проще понять, как строятся линейные структуры данных, чем более сложные структуры, такие как деревья и графы.
Деревья являются широко известными нелинейными структурами. Они хранят данные не линейным способом, а упорядочивают их иерархически.
Давайте вплотную займемся реальными примерами
Что я имею в виду, когда я говорю иерархически?
Представьте себе генеалогическое древо отношений между поколениями: бабушки и дедушки, родители, дети, братья и сестры и т.д. Мы обычно организуем семейные деревья иерархически.
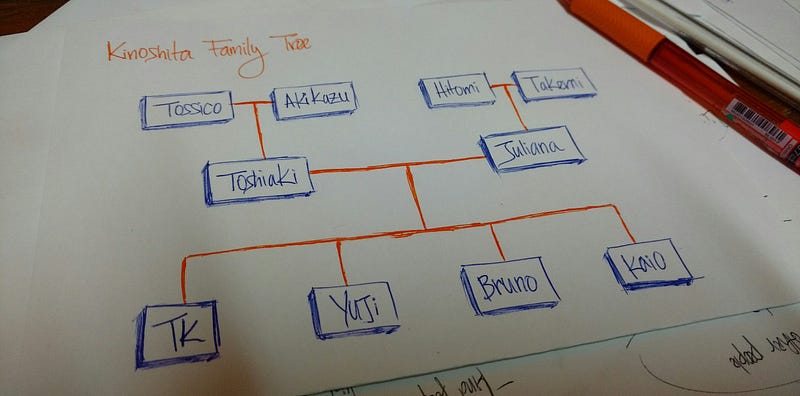 Мое фамильное дерево
Мое фамильное дерево
Приведенный рисунок – это мое фамильное древо. Тосико, Акикадзу, Хитоми и Такеми – мои дедушки и бабушки.
Тошиаки и Джулиана – мои родители.
ТК, Юдзи, Бруно и Кайо – дети моих родителей (я и мои братья).
Структура организации – еще один пример иерархии.
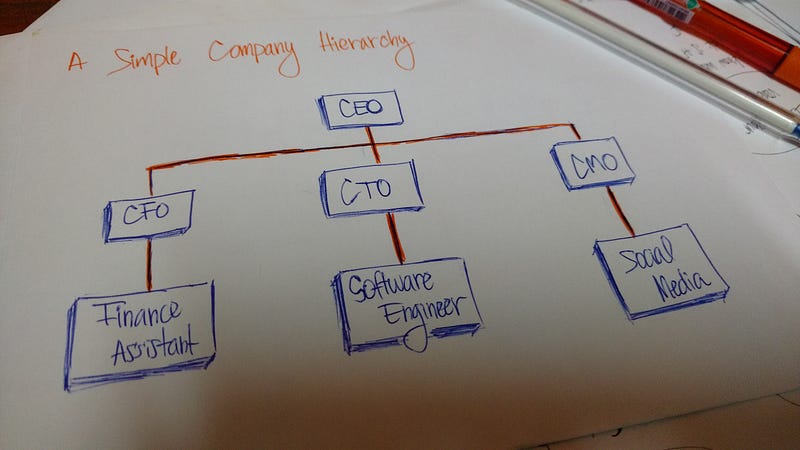 Структура компании является примером иерархии
Структура компании является примером иерархии
В HTML, объектная модель документа (DOM) представляется в виде дерева.
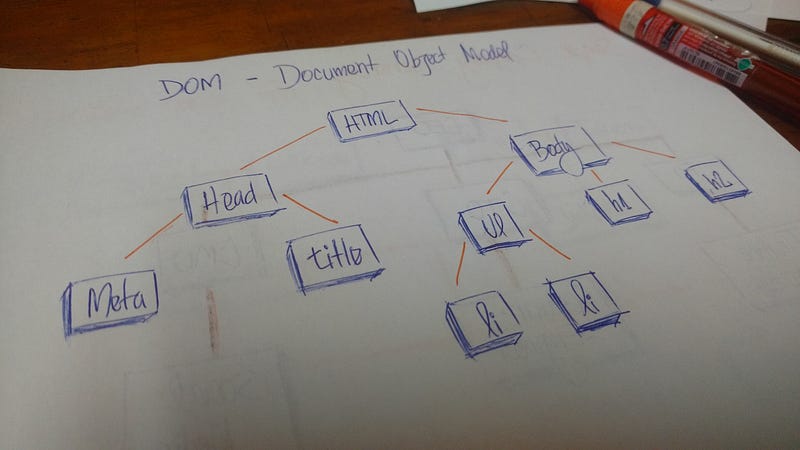 Объектная модель документа (DOM)
Объектная модель документа (DOM)
Техническое определение
Дерево представляет собой набор объектов, называемых узлами. Узлы соединены ребрами. Каждый узел содержит значение или данные, и он может иметь или не иметь дочерний узел.
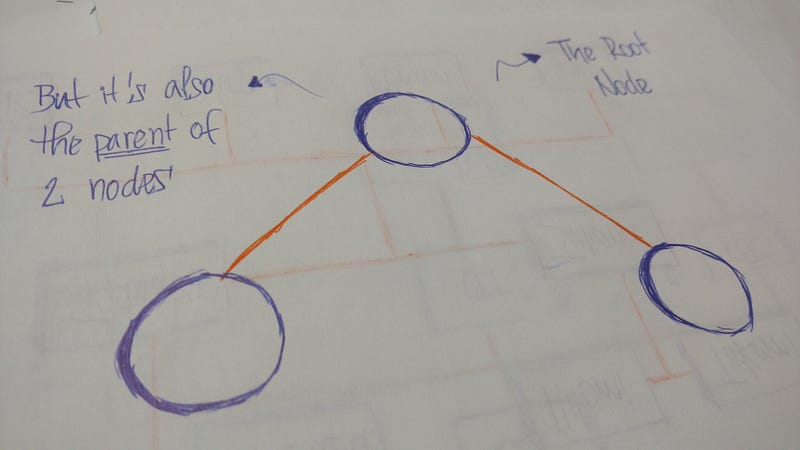
Первый узел дерева называется корнем. Если этот корневой узел соединен с другим узлом, тогда корень является родительским узлом, а связанный с ним узел — дочерним.
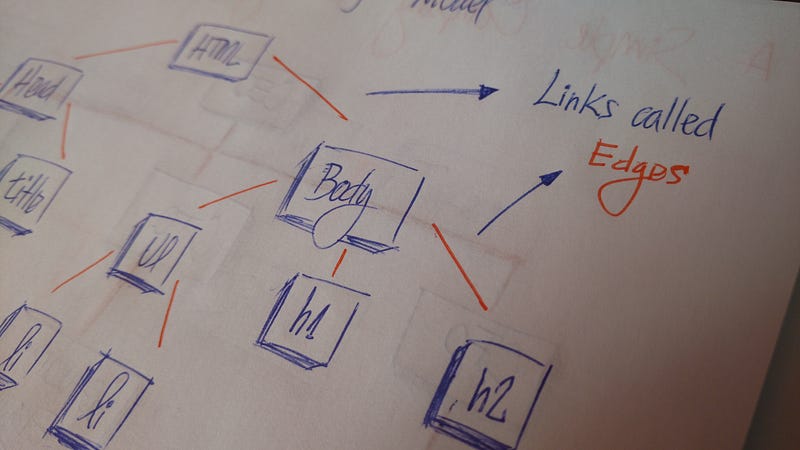
Все узлы дерева соединены линиями, называемыми ребрами. Это важная часть деревьев, потому что она управляет связью между узлами.
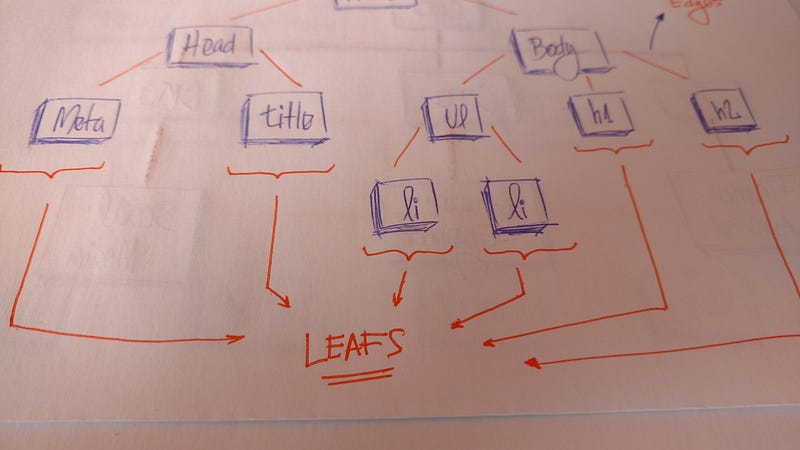
Листья — это последние узлы на дереве. Это узлы без потомков. Как и в реальных деревьях, здесь имеется корень, ветви и, наконец, листья.
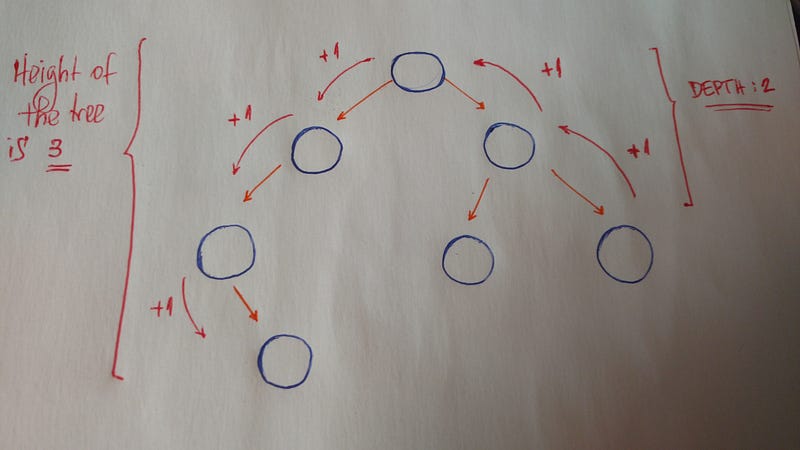
Другими важными понятиями являются высота и глубина.
Высота дерева — это длина самого длинного пути к листу.
Глубина узла — это длина пути к его корню.
Справочник терминов
Бинарные деревья
Теперь рассмотрим особый тип деревьев, называемых бинарными или двоичными деревьями.
Рассмотрим пример бинарного дерева.
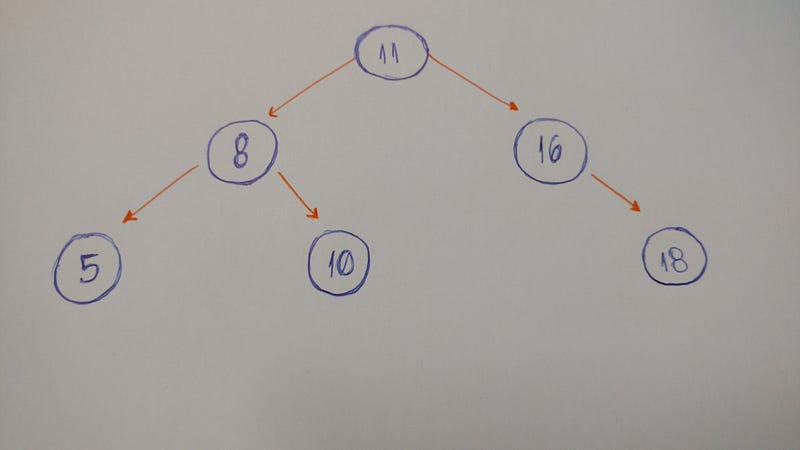
Давайте закодируем бинарное дерево
Как мы реализуем простое двоичное дерево, которое инициализирует эти три свойства?
Вот наш двоичный класс дерева.
Когда мы создаем наш узел, он не имеет потомков. Просто есть данные узла.
Давайте это проверим:
Перейдем к части вставки. Что нам нужно здесь сделать?
Мы реализуем метод вставки нового узла справа и слева.
Давайте это нарисуем 🙂
Вот программный код:
Еще раз, если текущий узел не имеет левого дочернего элемента, мы просто создаем новый узел и устанавливаем его в качестве left_child текущего узла. Или мы создаем новый узел и помещаем его вместо текущего левого потомка. Назначим этот левый дочерний узел в качестве левого дочернего элемента нового узла.
И мы делаем то же самое, чтобы вставить правый дочерний узел.
Но не полностью. Осталось протестировать.
Давайте построим следующее дерево:
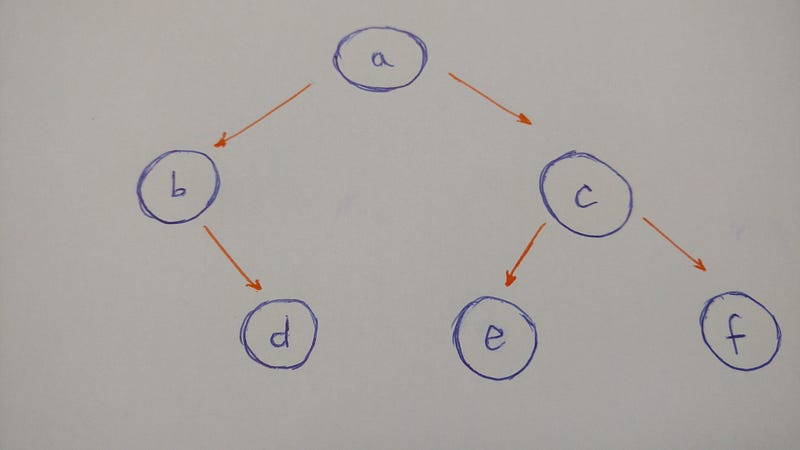
Подытоживая изображенное дерево, заметим:
Таким образом, вот код для нашего дерева следующий:
Теперь нам нужно подумать об обходе дерева.
У нас есть два варианта: поиск в глубину (DFS) и поиск по ширине (BFS).
• Поиск в глубину (Depth-first search, DFS) — один из методов обхода дерева. Стратегия поиска в глубину, как и следует из названия, состоит в том, чтобы идти «вглубь» дерева, насколько это возможно. Алгоритм поиска описывается рекурсивно: перебираем все исходящие из рассматриваемой вершины рёбра. Если ребро ведёт в вершину, которая не была рассмотрена ранее, то запускаем алгоритм от этой нерассмотренной вершины, а после возвращаемся и продолжаем перебирать рёбра. Возврат происходит в том случае, если в рассматриваемой вершине не осталось рёбер, которые ведут в не рассмотренную вершину. Если после завершения алгоритма не все вершины были рассмотрены, то необходимо запустить алгоритм от одной из не рассмотренных вершин.
• Поиск в ширину (breadth-first search, BFS) — метод обхода дерева и поиска пути. Поиск в ширину является одним из неинформированных алгоритмов поиска. Поиск в ширину работает путём последовательного просмотра отдельных уровней дерева, начиная с узла-источника. Рассмотрим все рёбра, выходящие из узла. Если очередной узел является целевым узлом, то поиск завершается; в противном случае узел добавляется в очередь. После того, как будут проверены все рёбра, выходящие из узла, из очереди извлекается следующий узел, и процесс повторяется.
Давайте подробно рассмотрим каждый из алгоритмов обхода.
Поиск в глубину (DFS)
DFS исследует все возможные пути вплоть до некоторого листа дерева, возвращается и исследует другой путь (осуществляя, таким образом, поиск с возвратом). Давайте посмотрим на пример с этим типом обхода.
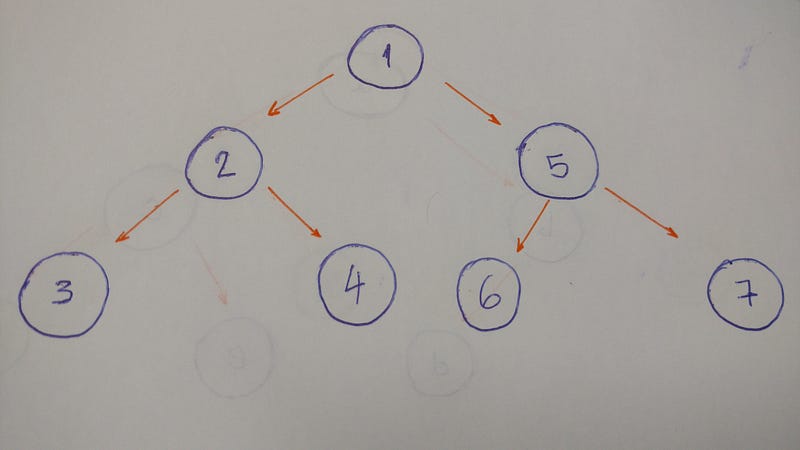
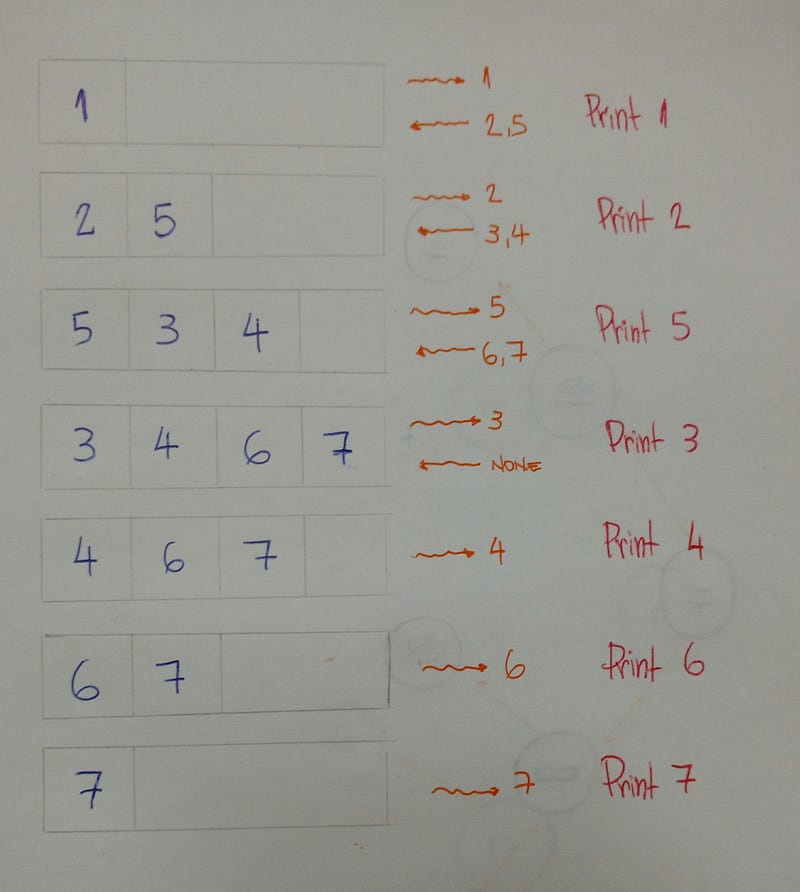
Результатом этого алгоритма будет: 1–2–3–4–5–6–7.
Давайте разъясним это подробно.
Проход в глубь дерева, а затем возврат к исходной точке называется алгоритмом DFS.
После знакомства с этим алгоритмом обхода, рассмотрим различные типы DFS-алгоритма: предварительный обход (pre-order), симметричный обход (in-order) и обход в обратном порядке (post-order).
Предварительный обход
Именно это мы и делали в вышеприведенном примере.
1. Записать значение узла.
2. Перейти к левому потомку и записать его. Это выполняется тогда и только тогда, когда имеется левый потомок.
3. Перейти к правому потомку и записать его. Это выполняется тогда и только тогда, когда имеется правый потомок.
Симметричный обход
Результатом алгоритма симметричного обхода для этого дерева tree в примере является 3–2–4–1–6–5–7.
Первый левый, средний второй и правый последний.
Теперь давайте напишем программный код.
Обход в обратном порядке
Результатом алгоритма прохода в обратном порядке для этого примера дерева является 3–4–2–6–7–5–1.
Первое левое, правое второе и последнее посередине.
Давайте напишем для него программный код.
Поиск в ширину (BFS)
BFS алгоритм обходит дерево tree уровень за уровнем вглубь дерева.
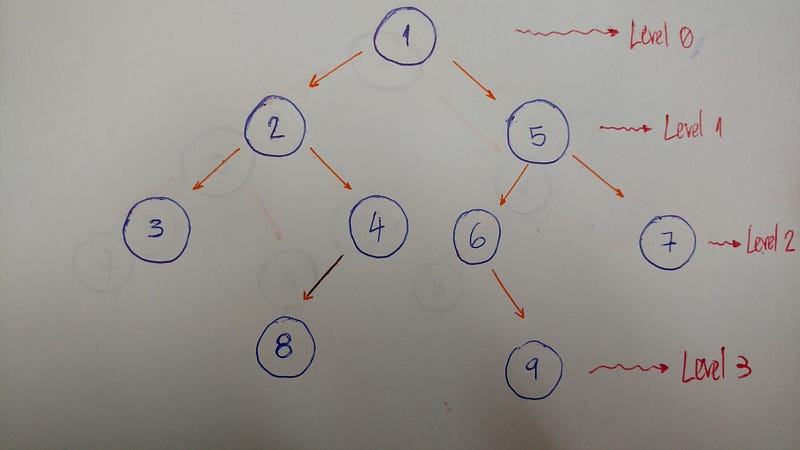
Вот пример, помогающий лучше объяснить этот алгоритм:
Таким образом мы обходим дерево уровень за уровнем. В этом примере результатом является 1–2–5–3–4–6–7.
Теперь давайте напишем программный код.
Для реализации BFS-алгоритма мы используем данные структуры «очередь«.
Вот пошаговое объяснение.
Бинарное дерево поиска
Важным свойством поиска на двоичном дереве является то, что величина узла Binary Search Tree больше, чем количество его потомков левого элемента-потомка, но меньшее, чем количество его потомков правого элемента-потомка.
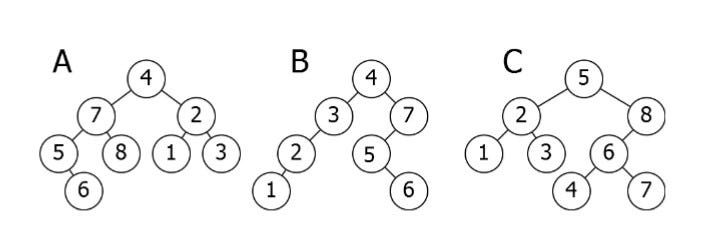
Вот детальный разбор приведенной выше иллюстрации.
Давайте напишем код для поиска на бинарном дереве!
Наступило время писать код!
Что вы увидите? Мы вставим новые узлы, поищем значения, удалим узлы и сбалансируем дерево.
Вставка: добавление новых узлов на наше дерево
Представьте, что у нас есть пустое дерево, и мы хотим добавить новые узлы со следующими значениями в следующем порядке: 50, 76, 21, 4, 32, 100, 64, 52.
Первое, что нам нужно знать, это то, что 50 является корнем нашего дерева.

Теперь мы можем начать вставлять узел за узлом.
Давайте напишем программный код.
Вроде бы все просто.
Большой частью этого алгоритма выступает рекурсия, которая находится в строке 9 и строке 13. Обе строки кода вызывают метод insert_node и используют его для своих левых и правых потомков соответственно.
Строки 11 и 15 осуществляют делают вставку для каждого потомка.
Давайте найдем значение узла … Или не найдем …
Теперь алгоритм, который мы будем строить — алгоритм поиска. Для данного значения (целое число), мы скажем, имеет ли наше дерево двоичного поиска или нет это значение.
Важно отметить, что мы определили алгоритм вставки. Сначала у нас есть наш корневой узел. Все левые узлы поддеревьев будут иметь меньшие значения, чем корневой узел. И все правильные узлы поддерева будут иметь значения, превышающие корневой узел.
Давайте рассмотрим пример.
Представьте, что у нас имеется это дерево.
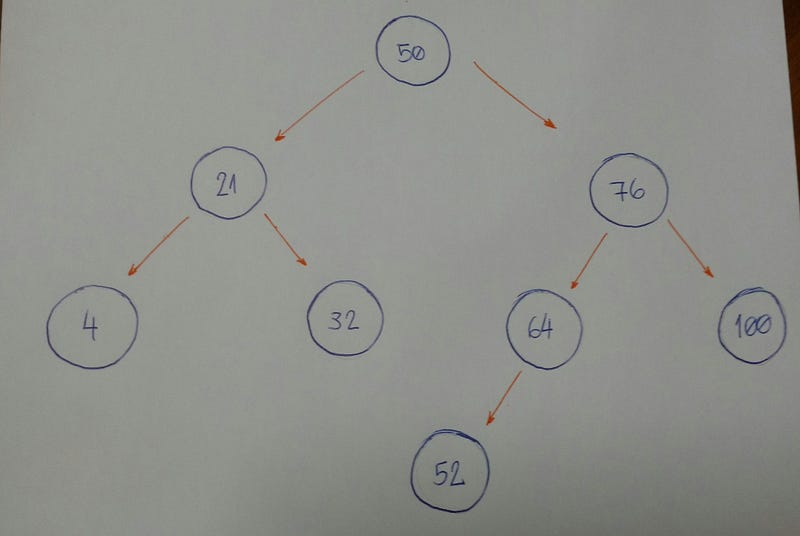
Теперь мы хотим узнать есть ли у нас узел со значением 52.
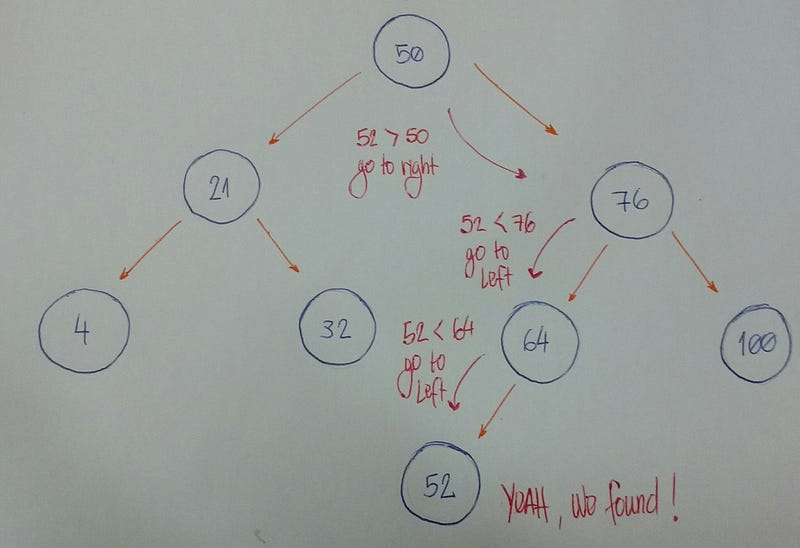
Давайте рассмотрим подробнее.
Давайте напишем код.
Разберем код подробнее:
Как нам это проверить?
Давайте создадим наше Binary Search Tree путем инициализации корневого узла значением 15.
А теперь мы вставим много новых узлов.
Да, он работает для этих заданных значений! Давайте проверим для значения, отсутствующего в нашем бинарном дереве поиска.
Стирание: удаление и организация
Удаление — более сложный алгоритм, потому что нам нужно обрабатывать разные случаи. Для заданного значения нам нужно удалить узел с этим значением. Представьте себе следующие сценарии для данного узла: у него нет потомков, есть один потомок или есть два потомка.
Если узел, который мы хотим удалить, не имеет дочерних элементов, мы просто удалим его. Алгоритм не требует реорганизации дерева.
В этом случае наш алгоритм должен заставить родительский узел указывать на узел-потомок. Если узел является левым дочерним элементом, мы делаем родительский элемент левого дочернего элемента дочерним. Если узел является правым дочерним по отношению к его родительскому, мы делаем родительский элемент правого дочернего дочерним.
Когда узел имеет 2 потомка, нужно найти узел с минимальным значением, начиная с дочернего узла. Мы поставим этот узел с минимальным значением на место узла, который мы хотим удалить.
Пришло время записать код.
Теперь давайте проверим.
Удалим узел со значением 8. Это узел без дочернего элемента.
Теперь давайте удалим узел со значением 17. Это узел с одним потомком.
Наконец, мы удалим узел с двумя потомками. Это корень нашего дерева.
Проверки успешно выполнены 🙂
Пока это все!
Мы с вами уже очень многое изучили.
Поздравляем с завершением чтения и разбора нашей насыщенной информацией и практикой статьи. Всегда довольно сложно понять новую, неизвестную еще концепцию. Но вы читатель, преодолели все трудности 🙂



