Operating Systems: Three Easy Pieces. Part 2: Абстракция: Процесс (перевод)
Привет, Хабр! Хочу представить вашему вниманию серию статей-переводов одной интересной на мой взгляд литературы — OSTEP. В этом материале рассматривается достаточно глубоко работа unix-подобных операционных систем, а именно — работа с процессами, различными планировщиками, памятью и прочиими подобными компонентами, которые составляют современную ОС. Оригинал всех материалов вы можете посмотреть вот тут. Прошу учесть, что перевод выполнен непрофессионально (достаточно вольно), но надеюсь общий смысл я сохранил.
Рассмотрим наиболее фундаментальную абстракцию, которую ОС предоставляет пользователям: процесс. Определение процесса довольно-таки просто — это работающая программа. Программа сама по себе является безжизненной вещью, располагающейся на диске — это набор инструкций и возможно каких-то статических данных, ожидающих момента запуска. Именно ОС берет эти байты и запускает их, преобразую программу во что-то полезное.
Чаще всего пользователи хотят запускать более одной программы одновременно, например вы можете запустить на вашем ноутбуке браузер, игру, медиаплеер, текстовый редактор и тому подобное. Фактически типичная система может запускать десятки и сотни процессов одновременно. Этот факт делает систему более простой в использовании, вам никогда не приходится беспокоиться о том, свободен ли CPU, вы просто запускаете программы.
Отсюда вытекает проблема: как обеспечить иллюзию множества CPU? Как ОС создать иллюзию практически бесконечного количества CPU, даже если у вас всего один физический CPU?
ОС создает эту иллюзию посредством виртуализации CPU. Запуская один процесс, затем останавливая его, запуская другой процесс и так далее, ОС может поддерживать иллюзию того, что существует множество виртуальных CPU, хотя фактически это будет один или несколько физических процессоров. Такая техника называется разделение ресурсов CPU по времени. Эта техника позволяет пользователям запускать столько одновременных процессов, сколько они пожелают. Ценою такого решения является производительность – поскольку если CPU делят несколько процессов, каждый процесс будет обрабатываться медленнее.
Для воплощения виртуализации CPU, а особенно для того чтобы делать это хорошо, ОС нуждается и в низкоуровневой и в высокоуровневой поддержке. Низкоуровневая поддержка называется механизмами — это низкоуровневые методы или протоколы, которые реализуют нужную часть функционала. Пример такого функционала — контекстное переключение, которое дает ОС возможность останавливать одну программу и запускать на процессоре другую программу. Такое разделение по времени реализовано во всех современных ОС.
На вершине этих механизмов располагается некоторая логика, заложенная в ОС, в форме “политик”. Политика — это некоторый алгоритм принятия решения операционной системой. Такие политики, например, решают, какую программу надо запускать (из списка команд) в первую очередь. Так, например, данную задачу решит политика, называющаяся планировщик (scheduling policy) и при выборе решения будет руководствоваться такими данными как: история запуска (какая программа была запущена дольше всех за последнюю минут), какую нагрузку осуществляет данный процесс (какие типы программ были запущены), метрики производительности (оптимизирована ли система для интерактивного взаимодействия или для пропускной способности) и так далее.
Абстракция: процесс
Абстракция работающей программы, выполняемая операционной системой это то, что мы называем процесс. Как уже было сказано ранее процесс – это просто работающая программа, в любой моментальный промежуток времени. Программа с помощью которой мы можем получить суммарную информацию с различных ресурсов системы, и к которым обращается или которые эта программа затрагивает в процессе своего выполнения.
Для понимания составляющих процесса нужно понимать состояния системы: что программа может считывать или изменять во время своей работы. В любой момент времени нужно понимать, какие элементы системы важны для выполнения программы.
Одним из очевидных элементов состояния системы, которые включает в себя процесс — это память. Инструкции располагаются в памяти. Данные, которые программа читает или пишет также, располагаются в памяти. Таким образом, память, которую процесс может адресовать (так называемое адресное пространство) является частью процесса.
Также частью состояния системы являются регистры. Множество инструкций направлено на то, чтобы изменить значение регистров или прочитать их значение и таким образом регистры тоже становятся важной частью работы процесса.
Следует отметить, что состояние машины формируется также из некоторых специальных регистров. Например, IP — instruction pointer — указатель на инструкцию, которую программа исполняет в текущий момент. Еще есть stack pointer и связанный с ним frame pointer, которые используются для управления: параметрами функций, локальными переменными и адресами возврата.
Наконец, программы часто обращаются к ПЗУ (постоянному запоминающему устройству). Такая информация о “I/O” (вводе-выводе) должна включать в себя список файлов, открытых процессом в данный момент.
Process API
Для того чтобы улучшить понимания работы процесса изучим примеры системных вызовов, которые должны быть включены в любой интерфейс операционной системы. Эти API в том или ином виде доступны на любой ОС.

Создание процесса: детали
Одна из интересных вещей — как же именно программы трансформируются в процессы. Особенно, как ОС поднимает и запускает программу. Как конкретно создается процесс.
В первую очередь ОС должна загрузить код программы и статические данные в память (в адресное пространство процесса). Программы обычно располагаются на диске или твердотельном накопителе в некотором исполняемом формате. Таким образом, процесс загрузки программы и статических данных в память требует от ОС возможности прочитать эти байты с диска и расположить их где-то в памяти.
В ранних ОС процесс загрузки выполнялся нетерпеливо (eagerly), то есть это значит что код загружался в память целиком до того как программа запускалась. Современные ОС делают это лениво (lazily), то есть загружая кусочки кода или данных только тогда, когда они требуются программе во время ее выполнения.
После того как код и статические данные загружены в память ОС нужно выполнить еще несколько вещей перед тем как запустить процесс. Некоторое количество памяти должно быть выделено под стек. Программы используют стек для локальных переменных, параметров функций и адресов возврата. ОС выделяет эту память и отдает ее процессу. Стек также может выделяться с некоторыми аргументами, конкретно она заполняет параметры функции main(), например массивом argc и argv.
Операционная система может также выделять некоторое количество памяти под кучу (heap) программы. Куча используется программами для явно запрашиваемых динамически выделенных данных. Программы запрашивают это пространство, вызывая функцию malloc() и явно очищает, вызывая функцию free(). Куча нужна для таких структур данных как: связанные листы, таблицы хэшей, деревья и другие. По началу под кучу выделяется маленькое количество памяти, но со временем в процессе работы программы куча может запросить большее количество памяти, через библиотечный API вызов malloc(). Операционная система вовлечена в процесс выделения большего количества памяти для того, чтобы помочь в удовлетворении этих вызовов.
Операционная система также будет выполнять задачи инициализации, в частности те, которые относятся к вводу-выводу. Например, в системах UNIX каждый процесс по умолчанию имеет 3 открытых файловых дескриптора, для стандартного потока ввода, вывода и ошибок. Эти дескрипторы позволяют программам считывать ввод из терминала, а также выводить информацию на экран.
Таким образом, загружая код и статические данные в память, создавая и инициализируя стек, а также выполняя другую работу, относящуюся к выполнению задач ввода-вывода, ОС подготавливает площадку для выполнения процесса. В конце концов, остается последняя задача: запустить на исполнение программу через ее точку ввода, называемую функцией main(). Переходя к выполнению функции main(), ОС передает управление CPU вновь созданному процессу, таким образом, программа начинает исполняться.
Состояние процесса
Теперь, когда у нас есть некоторое понимание, что такое процесс и как он создается, перечислим состояния процесса, в которых он может находиться. В самой простой форме процесс может находиться в одном из этих состояний:
● Running. В запущенном состоянии процесс выполняется на процессоре. Это значит, что происходит выполнение инструкций.
● Ready. В состоянии готовности процесс готов запуститься, но по каким-то причинам ОС не исполняет его в заданный момент времени.
● Blocked. В заблокированном состоянии процесс выполняет какие-то операции, которые не дают ему быть готовым к исполнению до тех пор, пока не произойдет какое-либо событие. Один из обычных примеров — когда процесс инициализирует операцию IO, он становится заблокированным и таким образом какой-то другой процесс может использовать процессор.
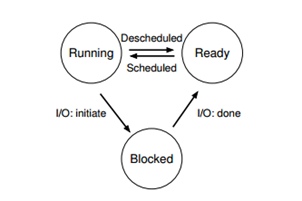
Представить себе эти состояния можно в виде графа. Как мы можем видеть на картинке, состояние процесса может меняться между RUNNING и READY на усмотрение ОС. Когда состояние процесса меняется с READY, на RUNNING это означает, что процесс был запланирован. В обратную сторону — снят с планировки. В момент, когда процесс становится BLOCKED, например, инициализирую операцию IO, ОС будет держать его в этом состоянии до наступления некоторого события, например завершение IO. в этот момент переход в состояние READY и возможно моментально в состояние RUNNING, если так решит ОС.
Давайте взглянем на пример того, как два процесса проходят через эти состояния. Для начала представим, что оба процесса запущены, и каждый использует только CPU. В этом случае, их состояния будут выглядеть следующим образом.

В следующем примере первый процесс через некоторое время работы запрашивает IO и переходит в состояние BLOCKED, предоставляя другому процессу возможность запуска (РИС 1.4). ОС видит, что процесс 0 не использует CPU и запускает процесс 1. Во время выполнения процесса 1 — IO завершается и статус процесса 0 меняется на READY. Наконец процесс 1 завершился, а по его окончание процесс 0 запускается, исполняется и заканчивает свою работу.

Структура данных
ОС сама является программой, и также как и любая другая программа имеет некоторые ключевые структуры данных, которые отслеживают разнообразные релевантные куски информации. Для отслеживания состояния каждого процесса в ОС будет поддерживаться некоторый process list для всех процессов в состоянии READY и некоторую дополнительную информацию для отслеживания процессов, которые выполняются в текущий момент. Также, ОС должна отслеживать и заблокированные процессы. После завершения IO, ОС обязана пробудить нужный процесс и перевести его в состояние готовности к запуску.
Так, например, ОС должна сохранить состояние регистров процессора. В момент остановки процесса состояние регистров сохраняется в адресном пространстве процесса, а в момент продолжения его работы — восстановить значения регистров и таким образом продолжить выполнения этого процесса.
Кроме состояний ready, blocked, running существуют еще некоторые другие состояния. Иногда в момент создания процесс может иметь состояние INIT. Наконец процесс может быть помещен состояние FINAL, когда он уже завершился, но информация о нем еще не вычищена. В UNIX системах такое состояние называется процесс-зомби. Это состояние полезно для случаев когда родительский процесс хочет узнать код возврата потомка, например, обычно 0 сигнализирует об успешном завершении, а 1 об ошибочном, однако программисты могут делать дополнительные коды вывода, сигнализируя о разных проблемах. При завершении процесс-родитель делает последний системный вызов, например wait(), чтобы дождаться завершения работы процесса-потомка и просигнализировать ОС о том, что можно очистить любые данные, связанные с завершенным процессом.
Что может делать процесс
Даже так называемые уровни выполнения системы (runlevels . и здесь), представляют собой удобный способ определения группы выполняющихся процессов и, соответственно, функциональности системы.
Модель процесса
Программы и процессы
С каждым процессом связывается его адресное пространство — список адресов в памяти от некоторого минимума (обычно нуля) до некоторого максимума, которые процесс может прочесть и в которые он может писать. Адресное пространство содержит саму программу, данные к ней и ее стек. Со всяким процессом связывается некий набор регистров, включая счетчик команд, указатель стека и другие аппаратные регистры, плюс вся остальная информация, необходимая для запуска программы.
В то же время процессы имеют возможность обмениваться друг с другом данными с помощью предоставляемой UNIX системой межпроцессного взаимодействия. В UNIX существует набор средств взаимодействия между процессами, таких как:
Типы процессов
Системные процессы
Демоны
Демоны (www.freedesktop.org) — это неинтерактивные процессы, которые запускаются обычным образом — путем загрузки в память соответствующих им программ (исполняемых файлов), и выполняются в фоновом режиме. Обычно демоны запускаются при инициализации системы (но после инициализации ядра) и обеспечивают работу различных подсистем UNIX: системы терминального доступа, системы печати, системы сетевого доступа и сетевых услуг и т. п. Демоны не связаны ни с одним пользовательским сеансом работы и не могут непосредственно управляться пользователем. Большую часть времени демоны ожидают пока тот или иной процесс запросит определенную услугу, например, доступ к файловому архиву или печать документа.Отдельной темой является Systemd (как и безвременно нас покинувший Upstart )— демон инициализации других демонов в Linux, который используется вместо SystemV Init ( sysvinit ). Критики считают, что демон systemd берёт на себя неоправданно много функций и превращается в главную угрозу стабильности системы.
Прикладные процессы
Пользовательские процессы могут выполняться как в интерактивном, так и в фоновом режиме, но в любом случае время их жизни (и выполнения) ограничено сеансом работы пользователя. При выходе из системы все пользовательские процессы будут уничтожены.
Интерактивные процессы монопольно владеют терминалом, и пока такой процесс не завершит свое выполнение, пользователь не сможет работать с другими приложениями.
Атрибуты процесса
Процесс в UNIX имеет несколько атрибутов, позволяющих операционной системе эффективно управлять его работой, важнейшие из которых рассмотрены ниже.
Идентификатор процесса Process ID (PID)
Каждый процесс имеет уникальный идентификатор PID, позволяющий ядру системы различать процессы. Когда создается новый процесс, ядро присваивает ему следующий свободный (т. е. не ассоциированный ни с каким процессом) идентификатор. Присвоение идентификаторов происходит по возрастающий, т. е. идентификатор нового процесса больше, чем идентификатор процесса, созданного перед ним. Если идентификатор достиг максимального значения, следующий процесс получит минимальный свободный PID и цикл повторяется. Когда процесс завершает свою работу, ядро освобождает занятый им идентификатор.
Идентификатор родительского процесса Parent Process ID (PPID)
Идентификатор процесса, породившего данный процесс.
Приоритет процесса (Nice Number)
Относительный приоритет процесса, учитываемый планировщиком при определении очередности запуска. Фактическое же распределение процессорных ресурсов определяется приоритетом выполнения, зависящим от нескольких факторов, в частности от заданного относительного приоритета. Относительный приоритет не изменяется системой на всем протяжении жизни процесса (хотя может быть изменен пользователем или администратором) в отличие от приоритета выполнения, динамически обновляемого ядром.
Терминальная линия (TTY)
Терминал или псевдотерминал, ассоциированный с процессом, если такой существует. Процессы-демоны не имеют ассоциированного терминала.
Реальный (RID) и эффективный (EUID) идентификаторы пользователя
Реальный (RGID) и эффективный (EGID) идентификаторы группы
Жизненный путь процесса
Рассмотрим эту схему на примере.
Построение процессов с нуля: от хаоса к порядку

В этой статье я расскажу про построение рабочих процессов в небольшом отделе, занимающемся веб-разработкой. Отдел был сформирован с нуля и сразу начал автономную работу, поэтому нам пришлось самостоятельно выстраивать производственные процессы, наступать на всевозможные грабли и делать из этого необходимые выводы. В надежде на то, что это поможет кому-нибудь сэкономить время, деньги и нервы, я опишу проблемы, с которыми мы столкнулись, и наши варианты их решения.
Важно отметить, что это не какая-то универсальная методология, которую можно внедрить в любой команде разработки, и все сразу станет замечательно. Это просто микс известных методик и практического опыта, который мы смогли эффективно подстроить под наши особенности разработки. В данном вопросе не существует единого простого решения. Всегда нужно отталкиваться от размера и опыта самой команды, особенностей бизнеса, специфики проектов и т. п.
Исходные данные нашего отдела: небольшая (5–10 человек), частично распределенная (некоторые сотрудники работают удаленно, некоторые в офисе) продуктовая команда с заказчиками внутри самой компании. Веб-проекты. Нет специалистов по системному администрированию внутри отдела, но есть занимающиеся этим отделы в компании.
Коммуникации в команде

Начнем с выстраивания эффективного общения внутри отдела. В любой команде важно построить эффективные каналы и способы коммуникации, но когда команда становится распределенной, эта потребность усиливается. Максимальной же остроты она достигла у нас потому, что команда распределена лишь частично. Нам пришлось научиться сращивать миры офисных и удаленных сотрудников.
Важнейшая проблема, с которой мы столкнулись, — устные обсуждения. У офисных сотрудников всегда есть соблазн быстро собраться за чашкой кофе и обсудить положение дел на проекте. Однако в этом случае удаленные работники не смогут поучаствовать в этом обсуждении, следовательно, не смогут внести свои идеи, да и вообще не будут знать, что что-то происходит. Как правило, это оборачивается рассинхронизацией действий команды, повторными обсуждениями из-за возникновения новых мыслей и предложений от распределенной части команды и просто неприятным осадком.
Стало понятно, что некоторые значимые общие вещи надо обсуждать письменно в общих чатах или на каких-то групповых звонках.
Это порождает другую очень распространенную проблему, которая появляется в командах, где нужно много писать, — проблему культуры письма. Уже нельзя просто подойти к коллеге, подергать за рукав, нарисовать что-то на салфетке и дополнить свой рассказ жестами. С одной стороны, это усложняет работу, а с другой — у людей развивается навык письменного выражения своих мыслей в понятной, структурированной форме. В результате такого подхода документация стала лучше оформляться, задачи стали четче формулироваться, каждый стал задумываться о том, как преподнести свою мысль так, чтобы она была понятна другим с первого прочтения.
Все вышесказанное не означает, что мы полностью отказались от личного общения, голосовых и видеозвонков. Однако мы взяли за правило, что результаты подобных обсуждений должны фиксироваться в письменном виде, как некий артефакт знаний, доступный всегда и всем.
Кратко взглянем на банальный список инструментов, с помощью которых мы решали наши коммуникационные задачи внутри команды.
Для начала мы завели чат в Telegram. Но потом, в связи с ростом команды, мы поняли, что в одном чате нам уже тесно, и перешли в Slack. Там мы разбили общий поток на тематические каналы и установили четкие правила — по каким поводам в какой канал писать. Это помогло избежать смешения полезной информации и флуда.
Плюс, переход на Slack дал нам некоторые приятные возможности для автоматизации и интеграции с другими сервисами, типа системы управления репозиториями или багтрекера.
Планирование, исполнение и контроль задач

Когда мы выстроили коммуникации, стала актуальной проблема постановки, контроля и выполнения задач внутри команды (о работе с заказчиком в этом плане я расскажу чуть позже).
У нас не существовало единого перечня задач, их приоритетов, статусов готовности и т. п. Вместо четкого, прозрачного и отслеживаемого плана присутствовало стихийное краткосрочное планирование и исполнение.
Чтобы бороться с этой ситуацией, мы стали использовать багтрекер (на самом деле мы попробовали их пять штук). Стали проявляться очертания общего направления проекта, появилось понимание того, в каком состоянии те или иные задачи и общая картина в целом. Однако мы столкнулись с проблемой недостатка дисциплины при использовании багтрекера, которая начала обесценивать многие наши начинания. Не все задачи заводились в багтрекере, не всегда актуализировались имеющиеся и т.д. Проще говоря, картина состояния проекта перестала быть актуальной и достоверной.
Для борьбы с этим мы разработали и внедрили свою культуру ведения задач:
Коммуникации с заказчиком
Следующая категория трудностей, которую нам было необходимо разрешить, — работа с заказчиками. Первое, что нам предстояло искоренить, — постановка задач на словах. Если мы внедрили культуру письма внутри отдела, то пришло время распространять ее и на внешние контакты.
Не секрет, что иной менеджер любит подойти к разработчику, на словах ему сказать, что надо сделать, для убедительности потыкать пальцами в экран и уйти, надеясь на то, что все будет выполнено хорошо и в срок. В данной ситуации менеджера и разработчика можно заменить на product owner и некоего менеджера команды разработки, который ведет все эти задачи. Результат от этого не поменяется.
В таком подходе кроется сразу несколько проблем:
Далее мы столкнулись с еще одной важной проблемой: заказчику сложно сформулировать задачу. Заказчик не всегда достаточно компетентен (а вернее, практически всегда недостаточно компетентен) в формулировании ТЗ для технической команды. И это нормально. Нельзя игнорировать и человеческий фактор: заказчику может быть банально неловко и неудобно приходить с просьбой к команде, когда он сам еще не смог до конца ее сформулировать. Один из критериев зрелой профессиональной команды — это умение помочь заказчику в выявлении его проблем, требований и решений.
Часто бывает, что заказчик, вместо того чтобы прийти с проблемой, приходит с просьбой о реализации уже выдуманного им решения. Чтобы не удивлять ни себя, ни заказчика результатами работы по ТЗ, составленному «на салфетке», мы создали базовый чек-лист вопросов для заказчика. Уже на основании этих ответов легче понять и заказчику, чего же он хочет на самом деле, и команде разработки, что от нее требуется. А потом настает черед задавать какие-то наводящие вопросы для уточнения или выявления требований.
Итак, перед первой встречей с заказчиком мы просим предварительно заполнить (насколько это возможно) и выслать нам этот чек-лист, чтобы после не пришлось тратить время на однотипные вопросы, а сразу приступить к плодотворному диалогу. Стоит отметить, что при взаимодействии с заказчиком важно не только уточнять те ответы, которые он предоставил, но и на основании заявленной им проблемы помочь ему выявить те требования, о которых он мог не подумать.
Список вопросов для заказчика:
Также в рамках этого пункта мы постарались искоренить классический антипаттерн «чайка-менеджмент», когда заказчик или менеджер прилетел, «наложил» задач — и улетел в полной уверенности, что раз он задачу поставил, то непременно на выходе получится отличный результат. Как показала практика, результат при таком подходе получался не самый впечатляющий. Как с этим бороться? Тут тоже нет какого-то универсального совета, какой-то волшебной фразы, изменяющей поведение людей. Для этого необходимо разговаривать, просвещать, объяснять, показывать, можно сказать воспитывать. Только просветительская работа и либо очень наглядные, либо очень измеримые (а желательно и то, и другое) позитивные и негативные примеры помогут в достаточной мере побороть «чайка-менеджмент».
Dev vs Ops
И последняя важная наша проблема — проблема в коммуникациях между отделами Dev и Ops.
Мы столкнулись с классической ситуацией, когда разработчики не очень хорошо понимают, как работает сервер, а сторонняя команда админов не очень представляет, как работает приложение. Каждое затруднение на стыке этих двух сфер давалось нам с болью и большими временными затратами. Трудно было даже диагностировать, на какой стороне проблема:
Разработка

Параллельно со всем эти мы занялись развитием культуры разработки.
Не буду заострять внимание на технической части, да и сейчас это уже стандарт де-факто и практически всем хватает понимания того, как необходимо наличие системы контроля версий, CI/CD и прочих инструментов разработки, сборки и деплоя. Остановлюсь лишь на soft моментах разработки.
Рефакторинг, технический долг и принцип непрерывного улучшения

Наш отдел стал формироваться вокруг уже существующего парка проектов, сделанных аутсорсерами. Естественно, никакой документации там не было, никто не следил за актуальностью и качеством кода. Так как мы понимали, что нам с этим еще долго работать, поддерживать и развивать, то было решено часть времени выделять на наведение порядка в проекте — рефакторинг, удаление неактуального кода и т. п.
Так как проект был большой, уровень энтропии был в нем также высок. Мы поняли, что за один присест это все не одолеть физически, да и морально опускаются руки от перспективы такой колоссальной работы. Мы решили применить японский принцип непрерывного улучшения «кайдзен». Раздробили технический долг на много маленьких частей и понемногу, но регулярно закрывали эти маленькие части, непрерывно модифицируя и улучшая как проекты, так и работу самой команды. Морально это никак не приносило неудобств, но при этом не оказывало значительного влияния на разработку новой функциональности и покрытие требований бизнеса. Спустя год-полтора мы обнаружили, что старый технический долг был полностью погашен, и это открыло нам возможности для разработки функциональности принципиально нового уровня сложности и важности.
Конечно, это не значит, что у нас сейчас нет технического долга. Так как проекты живут, эволюционируют, растут и развиваются, он, безусловно, накапливается. Однако мы за ним тщательно следим, откладываем в специальный пул задач и регулярно выделяем некоторое время на его погашение. Такая непрерывная работа с техническим долгом позволяет нам находить баланс между разработкой новой функциональности и качественной поддержкой старой.
В нашем случае нам, разработчикам, удалось объяснить и показать бизнесу важность погашения технического долга. Как мы это сделали? Мы на практике продемонстрировали такие ситуации, в которых, если не провести рефакторинг или какие-то другие структурные изменения текущего проекта, разработка новой функциональности или изменение старой будет невозможна в принципе (либо возможна, но в разы медленнее).
Внедрение Agile-методологий

Внедрение некоторых идей Agile-методологий позволило нам увеличить прозрачность нашей работы как внутри самой команды, так и для бизнеса, сделать разработку более прогнозируемой и гибкой, а результат более стабильным.
Первое, что мы сделали, — организовали ежедневные стендапы внутри команды. Так как команда распределенная, то в Slack отвели для этого отдельный канал, в котором каждое утро каждый сотрудник пишет три пункта: над какими задачами работал вчера, над какими планирует работать сегодня, есть ли какие-то проблемы, мешающие его работе. Флудить в этом канале, обсуждать чьи-то задачи или проблемы запрещено. Этот канал строго для агрегации информации о состоянии дел. Остальные обсуждения должны вестись в соответствующих тематических каналах. Это позволило каждому человеку в команде понимать, чем занимаются его коллеги, что происходит с проектом в общем, кому можно и нужно помочь. Если без стендапов проблемы замалчивались, а спустя долгое время неожиданно выяснялось, что задача еще не готова, то сейчас наглядно видно, кому требуется помощь, что нужно сделать, чтобы работа команды стала эффективнее.
Далее мы решили вести разработку по спринтам. Каждую пятницу в конце дня мы проводим ретроспективу спринта, смотрим, какие задачи были в планах, что готово, что не готово, и если что-то не готово, то почему так произошло. Думаем о том, какие у нас были проблемы и что мы могли бы сделать, чтобы избежать подобных трудностей в будущем. Затем планируем спринт на следующую неделю исходя из загруженности разных направлений внутри команды и бизнес-приоритетов. В результате в начале недели все разработчики знают, чем им заниматься и в какой последовательности, а бизнес знает, какие его потребности будут покрыты в ближайшее время, и может уже формировать свои «хотелки» на следующие спринты. Стоит сказать, что мы не избавлены от внезапных задач, которые могут нарушить наши планы на спринт. В этом случае нужно действовать исходя из конкретной специфики работы: как часто такие задачи возникают? Насколько много? Можно ли это спрогнозировать? В нашем конкретном случае в разработке мы опытным путем подсчитали, сколько времени в среднем приходится на незапланированные задачи и стараемся закладывать этот запас в спринт. Отдельно стоит отметить, что после начала работы по спринтам нам удалось конкретно выяснить, как много работы нам поставляется на вход внепланово, проанализировать и сократить это количество, тщательно обсуждая приоритеты с заказчиком и наглядно показывая, как сиюминутное желание получить не самую необходимую фичу прямо сейчас влияет на общую продуктивность всей команды.
Также мы перешли от длинных релизов к коротким. Раньше мы получали ТЗ, неделями или месяцами делали целый пак фич и только тогда показывали заказчику. В результате часто оказывалось, что заказчик либо передумал, либо ожидал не совсем того, и мы начинали переделывать все или часть того, что уже сделали. А вносить изменения в уже готовый большой набор фич — это сомнительное удовольствие. Сейчас мы демонстрируем каждую фичу как можно раньше, чтобы заказчик принял решение — то ли это, что он на самом деле хотел, или надо что-то изменить. Чем быстрее он либо утвердит, либо отправит на доработку, тем меньше трудозатрат мы вложим, следовательно, тем быстрее фича придет в продакшен. В результате фичи стали поступать в продакшен быстрее, быстрее проверяются гипотезы, быстрее пошло развитие проекта.
Bus factor
Так как команда у нас небольшая, мы сразу стали задумываться о проблемах, с которыми можем столкнуться при ротации кадров. Конкретные люди стали единоличными хранителями некоторых знаний, проекты достаточно разрослись вширь, и поэтому мы стали развивать культуру хранения и управления знаниями.
В искоренении этой проблемы нам помогло накопление артефактов знаний, которые переехали из голов конкретных людей в физический письменный мир. А именно:
Данный способ ведения артефактов знаний неоднократно помогал нам найти информацию о тех частях проекта, которые в противном случае были бы обязательно утеряны. А также он значительно снизил риски для проекта и команды при ротации кадров. Последний пример: мы довольно легко и быстро восстановили информацию о бизнес-логике, принципе работы и способе деплоя инструмента, который делал сотрудник, уволившийся два года назад.
Если наложить на эту методику работу со стендапами и спринтами, то bus factor сокращается еще сильнее. Не так давно мы провели эксперимент: один разработчик был в отпуске, а другой разработчик работал. На тот момент, когда первый вышел из отпуска, в отпуск ушел второй. Суть эксперимента заключалась в том, чтобы не писать никаких пояснительных писем, сообщений, никак не передавать дела и посмотреть, насколько будет сложно человеку после долгого отпуска понять, что происходило в его отсутствие, что изменилось, как именно и какие планы на будущее. Как показала практика, просмотр багтрекера, коммитов, документации, стендапов и спринтов позволил сотруднику довольно легко войти в курс дела и автономно продолжить свою работу.
Заключение
В заключение хотелось бы отметить, что ни одна из вышеуказанных проблем не решалась сразу и безупречно. Организационные изменения — это всегда долгий и методичный труд. Нельзя просто сказать «теперь делаем так» и надеяться, что теперь все станет иначе. Любые решения, которые вы примете, любые мероприятия, которые вы организуете, требуют контроля, обучения и просвещения людей, времени на адаптацию как команды к новым методикам, так и самих методик к конкретной ситуации. Также замечу, что навязывание людям какой-то методологии является очень трудоемким и малоэффективным процессом. Люди будут упираться, заб(ы/и)вать, возможно даже саботировать.
Чтобы в команде начались требующиеся изменения, команда должна сама захотеть эти изменения совершить. Необходимо следить за тем, как у нее обстоят дела, выявлять проблемные места, осознавать эти проблемы, находить решения и только тогда уже претворять их в жизнь. Конечно, не каждый член команды должен и хочет этим заниматься, но если есть кто-то, кто увидел эти проблемы и придумал их решения, то ему предстоит в первую очередь просвещать команду.
Делиться своими знаниями, наблюдениями, опытом, аргументировать, показывать и доказывать, где сейчас проблемы и какие можно предпринять шаги для их решения. Только так можно максимально эффективно производить крупные организационные преобразования. Даже если вы руководитель и хотите продавить свою позицию и свое решение — постарайтесь сделать это максимально аргументированно и убедительно, тем самым вы сэкономите время на внедрение и избавите команду от нежелательного негатива.
Автор: Евгений Антонов, руководитель группы разработки Positive Technologies



